An End-to-End Model for Photo-Sharing Multi-modal Dialogue Generation

0

Sign in to get full access
Overview
- Proposes an end-to-end model for generating multi-modal dialogues around photo-sharing
- Leverages large language models and stable diffusion for generating text and images
- Aims to create engaging conversations centered around shared visual experiences
Plain English Explanation
This paper presents an end-to-end model for photo-sharing multi-modal dialogue generation. The key idea is to build a system that can engage in natural conversations about shared visual experiences, such as discussing and analyzing a photo that is presented.
The model uses large language models to generate the dialogue text and stable diffusion to create relevant images. This allows the system to not only discuss a provided photo, but also dynamically generate new images that are relevant to the conversation.
The goal is to create engaging, multi-modal interactions where the user and the system can explore and discuss visual content in a natural, back-and-forth manner, similar to how people might chat about a photo they've just shared. This could have applications in various domains, such as enhancing image selection through dialogue or enabling more interactive text-based image editing.
Technical Explanation
The proposed end-to-end model for photo-sharing multi-modal dialogue generation consists of two main components:
-
Language Model: A large language model is used to generate the dialogue text, including both the user's inputs and the system's responses. This allows the conversation to flow naturally and cover a wide range of topics related to the provided photo.
-
Stable Diffusion: A stable diffusion model is used to generate relevant images that are dynamically created based on the context of the ongoing dialogue. This enables the system to not only discuss the original photo, but also introduce new visual elements that are relevant to the conversation.
The authors explore different strategies for effectively combining these two components, including techniques for coordinating the text and image generation to create a coherent and engaging multi-modal interaction.
Critical Analysis
The proposed end-to-end model for photo-sharing multi-modal dialogue generation represents a promising approach to enabling more natural and interactive visual experiences. However, the paper does not discuss potential limitations or areas for further research in depth.
One potential concern is the empirical study and analysis of text-to-image generation, which can be challenging to control and may introduce biases or inconsistencies into the generated images. Careful consideration of these factors will be important for ensuring the system's outputs are reliable and trustworthy.
Additionally, the paper does not explore the potential societal impacts or ethical considerations of such a system, which could be an important area for future work. As multi-modal interactive dialogue systems become more advanced, it will be crucial to address issues of privacy, bias, and responsible development.
Conclusion
The end-to-end model for photo-sharing multi-modal dialogue generation proposed in this paper represents an exciting step forward in enabling more engaging and natural visual experiences. By combining large language models and stable diffusion, the system can generate dynamic conversations and images that could have a range of applications, from enhancing image selection through dialogue to revolutionizing text-based image editing. As this technology continues to evolve, it will be important to carefully consider the potential impacts and ensure responsible development for the benefit of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An End-to-End Model for Photo-Sharing Multi-modal Dialogue Generation
Peiming Guo, Sinuo Liu, Yanzhao Zhang, Dingkun Long, Pengjun Xie, Meishan Zhang, Min Zhang
Photo-Sharing Multi-modal dialogue generation requires a dialogue agent not only to generate text responses but also to share photos at the proper moment. Using image text caption as the bridge, a pipeline model integrates an image caption model, a text generation model, and an image generation model to handle this complex multi-modal task. However, representing the images with text captions may loss important visual details and information and cause error propagation in the complex dialogue system. Besides, the pipeline model isolates the three models separately because discrete image text captions hinder end-to-end gradient propagation. We propose the first end-to-end model for photo-sharing multi-modal dialogue generation, which integrates an image perceptron and an image generator with a large language model. The large language model employs the Q-Former to perceive visual images in the input end. For image generation in the output end, we propose a dynamic vocabulary transformation matrix and use straight-through and gumbel-softmax techniques to align the large language model and stable diffusion model and achieve end-to-end gradient propagation. We perform experiments on PhotoChat and DialogCC datasets to evaluate our end-to-end model. Compared with pipeline models, the end-to-end model gains state-of-the-art performances on various metrics of text and image generation. More analysis experiments also verify the effectiveness of the end-to-end model for photo-sharing multi-modal dialogue generation.
Read more8/19/2024
🤖
0
DialogCC: An Automated Pipeline for Creating High-Quality Multi-Modal Dialogue Dataset
Young-Jun Lee, Byungsoo Ko, Han-Gyu Kim, Jonghwan Hyeon, Ho-Jin Choi
As sharing images in an instant message is a crucial factor, there has been active research on learning an image-text multi-modal dialogue models. However, training a well-generalized multi-modal dialogue model remains challenging due to the low quality and limited diversity of images per dialogue in existing multi-modal dialogue datasets. In this paper, we propose an automated pipeline to construct a multi-modal dialogue dataset, ensuring both dialogue quality and image diversity without requiring minimum human effort. In our pipeline, to guarantee the coherence between images and dialogue, we prompt GPT-4 to infer potential image-sharing moments - specifically, the utterance, speaker, rationale, and image description. Furthermore, we leverage CLIP similarity to maintain consistency between aligned multiple images to the utterance. Through this pipeline, we introduce DialogCC, a high-quality and diverse multi-modal dialogue dataset that surpasses existing datasets in terms of quality and diversity in human evaluation. Our comprehensive experiments highlight that when multi-modal dialogue models are trained using our dataset, their generalization performance on unseen dialogue datasets is significantly enhanced. We make our source code and dataset publicly available.
Read more4/1/2024

0
Visualizing Dialogues: Enhancing Image Selection through Dialogue Understanding with Large Language Models
Chang-Sheng Kao, Yun-Nung Chen
Recent advancements in dialogue systems have highlighted the significance of integrating multimodal responses, which enable conveying ideas through diverse modalities rather than solely relying on text-based interactions. This enrichment not only improves overall communicative efficacy but also enhances the quality of conversational experiences. However, existing methods for dialogue-to-image retrieval face limitations due to the constraints of pre-trained vision language models (VLMs) in comprehending complex dialogues accurately. To address this, we present a novel approach leveraging the robust reasoning capabilities of large language models (LLMs) to generate precise dialogue-associated visual descriptors, facilitating seamless connection with images. Extensive experiments conducted on benchmark data validate the effectiveness of our proposed approach in deriving concise and accurate visual descriptors, leading to significant enhancements in dialogue-to-image retrieval performance. Furthermore, our findings demonstrate the method's generalizability across diverse visual cues, various LLMs, and different datasets, underscoring its practicality and potential impact in real-world applications.
Read more7/8/2024
0
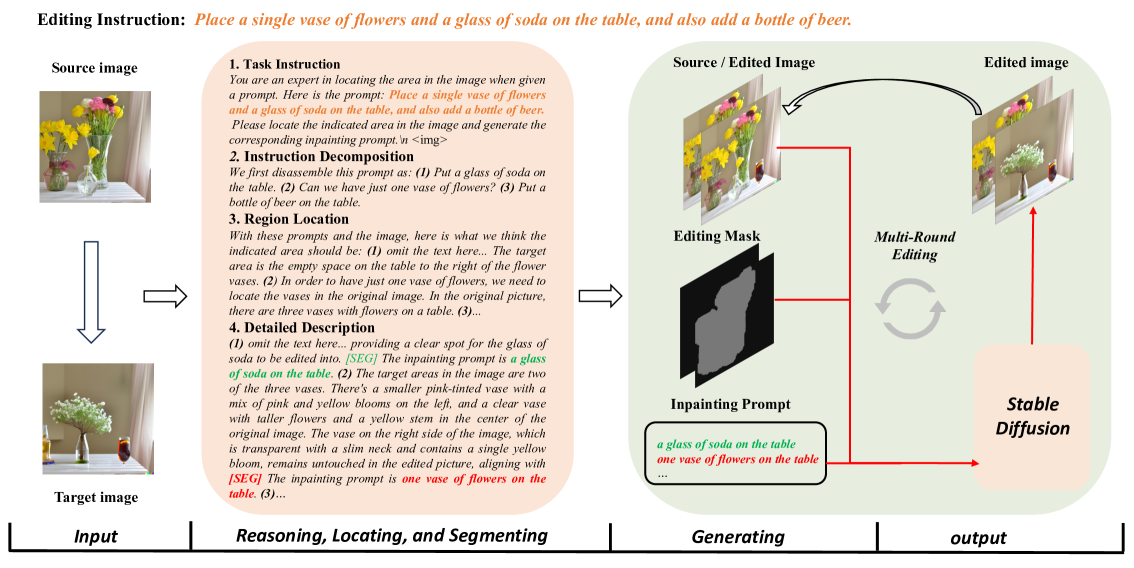
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
Xinyu Zhang, Mengxue Kang, Fei Wei, Shuang Xu, Yuhe Liu, Lin Ma
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
Read more5/28/2024