TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
2405.16803
0
0
Abstract
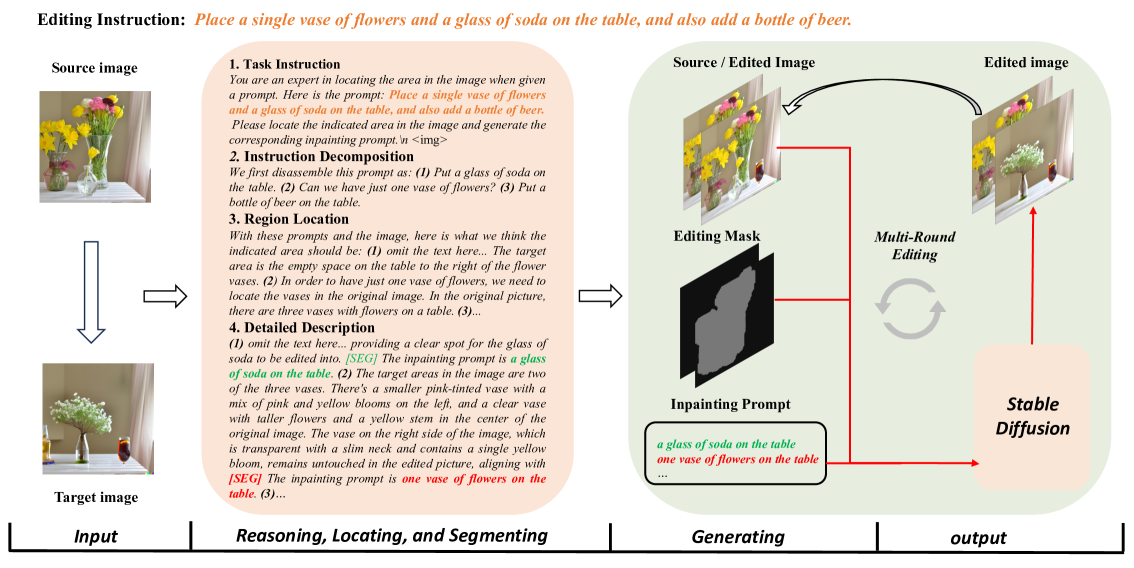
As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
Create account to get full access
Overview
- This paper introduces TIE, a text-based image editing system that can follow complex prompts and produce high-fidelity edited images.
- TIE combines a large language model with a diffusion-based image generation model to enable interactive, precise image editing guided by natural language instructions.
- The system can handle a wide range of text prompts, from simple commands to multi-step, compositional instructions, and generates images that closely match the desired edits.
Plain English Explanation
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing is a new AI-powered image editing tool that allows users to make sophisticated changes to images just by typing instructions. Rather than relying on predefined editing tools, TIE uses a large language model and a diffusion-based image generation model to understand and execute complex, multi-step editing prompts in natural language.
For example, a user could type something like "Add a yellow umbrella to the person in the center, make the sky bluer, and remove the background objects." TIE would then analyze this detailed prompt, figure out the intended edits, and generate a new image that matches the description. This allows for much more flexible and expressive image editing compared to traditional tools with discrete commands.
The key innovation in TIE is how it combines powerful language understanding with high-quality image generation. The language model can parse intricate, open-ended editing instructions, while the diffusion model can create realistic, high-resolution images that faithfully incorporate those edits. This enables a new level of text-guided image manipulation that goes beyond simple filters or pre-defined effects.
Technical Explanation
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing proposes a novel system for interactive, text-guided image editing. The key components are a large language model for understanding natural language prompts, and a diffusion-based image generation model for producing high-quality edited images.
The language model is trained on a large corpus of text data to develop strong language understanding capabilities. It can parse complex, multi-step editing instructions and identify the key semantic elements, such as the target objects, desired changes, and spatial relationships. This allows the system to handle a wide range of editing prompts, from simple commands to more compositional, open-ended instructions.
The diffusion model is then used to generate the edited image. Diffusion models are a type of generative AI that can create realistic images from scratch by iteratively adding and removing noise. In TIE, the diffusion process is conditioned on the text prompt, so that the final image matches the semantic content of the editing instructions.
Through extensive experiments, the authors demonstrate TIE's ability to follow complex prompts and generate high-fidelity edited images. They compare TIE's performance to other text-guided image editing approaches, showing significant improvements in both prompt following and visual quality.
Critical Analysis
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing represents an impressive advance in text-guided image manipulation, but it also has some limitations that are worth considering.
One key concern is the system's reliance on pre-trained models, which can introduce biases and limitations. The language model, for example, may struggle with handling rare or specialized vocabulary, and the diffusion model may have difficulty generating certain types of content or visual styles. Addressing these model-specific limitations could be an important area for future research.
Additionally, while TIE can handle complex prompts, the paper does not explore the system's robustness to ambiguous, contradictory, or adversarial instructions. Understanding how text-guided image editing systems respond to edge cases and potential misuse is an important consideration for real-world applications.
Image Thought Prompting: Visual Reasoning Refinement through Multimodal Chain-of-Thought and Multimodal Chain-of-Thought Reasoning in Language Models suggest that incorporating more sophisticated reasoning mechanisms, such as multi-step, cross-modal inference, could further improve the capabilities of text-guided image editing systems like TIE.
Overall, while TIE represents an impressive advance, there remains significant room for improvement and exploration in the field of text-guided image manipulation.
Conclusion
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing introduces a powerful new approach to interactive image editing that allows users to make sophisticated changes to images using natural language instructions. By combining a large language model with a diffusion-based image generation model, the system can understand and execute complex, multi-step editing prompts, producing high-quality edited images that closely match the desired changes.
This breakthrough in text-guided image manipulation has the potential to significantly simplify and enhance the image editing process, democratizing creative tools and empowering users of all skill levels. As the field of AI-powered image editing continues to evolve, systems like TIE could become invaluable for a wide range of applications, from professional design workflows to personal creative expression.
LDEdit: Towards Generalized Text-Guided Image Manipulation and ClickDiffusion: Harnessing Large Language Models for Interactive and Precise Image Editing represent other exciting developments in this space, showcasing the rapid progress and future potential of text-guided image editing technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding
Bozhi Luan, Hao Feng, Hong Chen, Yonghui Wang, Wengang Zhou, Houqiang Li
0
0
The advent of Large Multimodal Models (LMMs) has sparked a surge in research aimed at harnessing their remarkable reasoning abilities. However, for understanding text-rich images, challenges persist in fully leveraging the potential of LMMs, and existing methods struggle with effectively processing high-resolution images. In this work, we propose TextCoT, a novel Chain-of-Thought framework for text-rich image understanding. TextCoT utilizes the captioning ability of LMMs to grasp the global context of the image and the grounding capability to examine local textual regions. This allows for the extraction of both global and local visual information, facilitating more accurate question-answering. Technically, TextCoT consists of three stages, including image overview, coarse localization, and fine-grained observation. The image overview stage provides a comprehensive understanding of the global scene information, and the coarse localization stage approximates the image area containing the answer based on the question asked. Then, integrating the obtained global image descriptions, the final stage further examines specific regions to provide accurate answers. Our method is free of extra training, offering immediate plug-and-play functionality. Extensive experiments are conducted on a series of text-rich image question-answering benchmark datasets based on several advanced LMMs, and the results demonstrate the effectiveness and strong generalization ability of our method. Code is available at https://github.com/bzluan/TextCoT.
4/16/2024
💬
Image-of-Thought Prompting for Visual Reasoning Refinement in Multimodal Large Language Models
Qiji Zhou, Ruochen Zhou, Zike Hu, Panzhong Lu, Siyang Gao, Yue Zhang
0
0
Recent advancements in Chain-of-Thought (CoT) and related rationale-based works have significantly improved the performance of Large Language Models (LLMs) in complex reasoning tasks. With the evolution of Multimodal Large Language Models (MLLMs), enhancing their capability to tackle complex multimodal reasoning problems is a crucial frontier. However, incorporating multimodal rationales in CoT has yet to be thoroughly investigated. We propose the Image-of-Thought (IoT) prompting method, which helps MLLMs to extract visual rationales step-by-step. Specifically, IoT prompting can automatically design critical visual information extraction operations based on the input images and questions. Each step of visual information refinement identifies specific visual rationales that support answers to complex visual reasoning questions. Beyond the textual CoT, IoT simultaneously utilizes visual and textual rationales to help MLLMs understand complex multimodal information. IoT prompting has improved zero-shot visual reasoning performance across various visual understanding tasks in different MLLMs. Moreover, the step-by-step visual feature explanations generated by IoT prompting elucidate the visual reasoning process, aiding in analyzing the cognitive processes of large multimodal models
5/30/2024
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024

A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
Xincheng Shuai, Henghui Ding, Xingjun Ma, Rongcheng Tu, Yu-Gang Jiang, Dacheng Tao
0
0
Image editing aims to edit the given synthetic or real image to meet the specific requirements from users. It is widely studied in recent years as a promising and challenging field of Artificial Intelligence Generative Content (AIGC). Recent significant advancement in this field is based on the development of text-to-image (T2I) diffusion models, which generate images according to text prompts. These models demonstrate remarkable generative capabilities and have become widely used tools for image editing. T2I-based image editing methods significantly enhance editing performance and offer a user-friendly interface for modifying content guided by multimodal inputs. In this survey, we provide a comprehensive review of multimodal-guided image editing techniques that leverage T2I diffusion models. First, we define the scope of image editing from a holistic perspective and detail various control signals and editing scenarios. We then propose a unified framework to formalize the editing process, categorizing it into two primary algorithm families. This framework offers a design space for users to achieve specific goals. Subsequently, we present an in-depth analysis of each component within this framework, examining the characteristics and applicable scenarios of different combinations. Given that training-based methods learn to directly map the source image to target one under user guidance, we discuss them separately, and introduce injection schemes of source image in different scenarios. Additionally, we review the application of 2D techniques to video editing, highlighting solutions for inter-frame inconsistency. Finally, we discuss open challenges in the field and suggest potential future research directions. We keep tracing related works at https://github.com/xinchengshuai/Awesome-Image-Editing.
6/21/2024