An End-to-End Structure with Novel Position Mechanism and Improved EMD for Stock Forecasting
2404.07969
0
0
🤖
Abstract
As a branch of time series forecasting, stock movement forecasting is one of the challenging problems for investors and researchers. Since Transformer was introduced to analyze financial data, many researchers have dedicated themselves to forecasting stock movement using Transformer or attention mechanisms. However, existing research mostly focuses on individual stock information but ignores stock market information and high noise in stock data. In this paper, we propose a novel method using the attention mechanism in which both stock market information and individual stock information are considered. Meanwhile, we propose a novel EMD-based algorithm for reducing short-term noise in stock data. Two randomly selected exchange-traded funds (ETFs) spanning over ten years from US stock markets are used to demonstrate the superior performance of the proposed attention-based method. The experimental analysis demonstrates that the proposed attention-based method significantly outperforms other state-of-the-art baselines. Code is available at https://github.com/DurandalLee/ACEFormer.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel method for forecasting stock market movements using attention mechanisms.
- The method considers both individual stock information and broader stock market information, and uses a novel EMD-based algorithm to reduce short-term noise in stock data.
- The authors demonstrate the superior performance of their attention-based method on two exchange-traded funds (ETFs) from the US stock market.
Plain English Explanation
Forecasting stock market movements is a challenging problem for investors and researchers. Recent advances in Transformer models have led many researchers to explore using attention mechanisms to predict stock prices. However, most existing research has focused only on individual stock information, ignoring broader stock market data and the high noise in stock prices.
The authors of this paper have developed a new method that uses attention mechanisms to consider both individual stock details and overall stock market trends. They've also created a novel algorithm based on Empirical Mode Decomposition (EMD) to help reduce the short-term noise in stock price data. EMD is a technique used in signal processing to extract meaningful patterns from noisy data.
The authors tested their attention-based method on two Exchange Traded Funds (ETFs) representing the US stock market over a 10-year period. They found that their approach significantly outperformed other state-of-the-art techniques for forecasting stock movements.
Technical Explanation
The authors propose an attention-based method for forecasting stock movements that considers both individual stock information and broader stock market data. They use an attention mechanism to learn the relationships between these different inputs.
To reduce the short-term noise in the stock price data, the authors develop a novel EMD-based algorithm. EMD is a technique that can decompose a signal into intrinsic mode functions, allowing the authors to isolate and remove the high-frequency, noisy components of the stock price time series.
The authors evaluate their attention-based method, which they call ACEFormer, on two randomly selected ETFs from the US stock market over a 10-year period. They compare the performance of ACEFormer to other state-of-the-art baselines and find that it significantly outperforms them in forecasting stock movements.
Critical Analysis
The authors acknowledge that their study is limited to two ETFs and suggest that further research is needed to validate the generalizability of their approach to a wider range of stocks and markets.
Additionally, while the authors demonstrate the superior performance of their attention-based method, they do not provide a detailed analysis of the specific mechanisms by which the attention-based approach outperforms other techniques. Further research could delve deeper into understanding the underlying reasons for the improved performance.
It would also be interesting to see how the authors' EMD-based noise reduction algorithm compares to other denoising techniques, and whether there are any potential drawbacks or limitations to their approach.
Conclusion
This paper presents a novel attention-based method for forecasting stock market movements that considers both individual stock information and broader market data. The authors also introduce a novel EMD-based algorithm to reduce short-term noise in stock price data.
The authors' experimental results demonstrate the superior performance of their attention-based method compared to other state-of-the-art techniques. This research advances the field of time series forecasting for financial markets and could have important implications for investors and financial decision-makers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Developing An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
Zhenglong Li, Vincent Tam
0
0
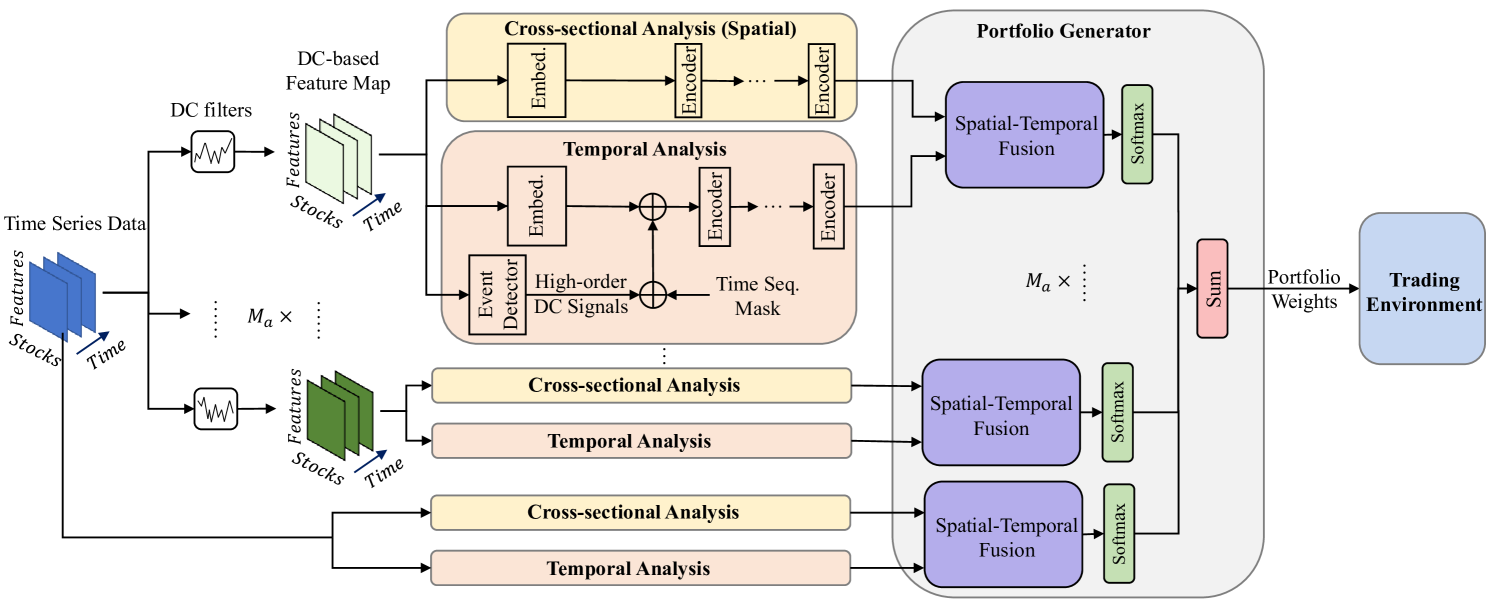
In recent years, deep or reinforcement learning approaches have been applied to optimise investment portfolios through learning the spatial and temporal information under the dynamic financial market. Yet in most cases, the existing approaches may produce biased trading signals based on the conventional price data due to a lot of market noises, which possibly fails to balance the investment returns and risks. Accordingly, a multi-agent and self-adaptive portfolio optimisation framework integrated with attention mechanisms and time series, namely the MASAAT, is proposed in this work in which multiple trading agents are created to observe and analyse the price series and directional change data that recognises the significant changes of asset prices at different levels of granularity for enhancing the signal-to-noise ratio of price series. Afterwards, by reconstructing the tokens of financial data in a sequence, the attention-based cross-sectional analysis module and temporal analysis module of each agent can effectively capture the correlations between assets and the dependencies between time points. Besides, a portfolio generator is integrated into the proposed framework to fuse the spatial-temporal information and then summarise the portfolios suggested by all trading agents to produce a newly ensemble portfolio for reducing biased trading actions and balancing the overall returns and risks. The experimental results clearly demonstrate that the MASAAT framework achieves impressive enhancement when compared with many well-known portfolio optimsation approaches on three challenging data sets of DJIA, S&P 500 and CSI 300. More importantly, our proposal has potential strengths in many possible applications for future study.
4/16/2024
🛠️
Easy attention: A simple attention mechanism for temporal predictions with transformers
Marcial Sanchis-Agudo, Yuning Wang, Roger Arnau, Luca Guastoni, Jasmin Lim, Karthik Duraisamy, Ricardo Vinuesa
0
0
To improve the robustness of transformer neural networks used for temporal-dynamics prediction of chaotic systems, we propose a novel attention mechanism called easy attention which we demonstrate in time-series reconstruction and prediction. While the standard self attention only makes use of the inner product of queries and keys, it is demonstrated that the keys, queries and softmax are not necessary for obtaining the attention score required to capture long-term dependencies in temporal sequences. Through the singular-value decomposition (SVD) on the softmax attention score, we further observe that self attention compresses the contributions from both queries and keys in the space spanned by the attention score. Therefore, our proposed easy-attention method directly treats the attention scores as learnable parameters. This approach produces excellent results when reconstructing and predicting the temporal dynamics of chaotic systems exhibiting more robustness and less complexity than self attention or the widely-used long short-term memory (LSTM) network. We show the improved performance of the easy-attention method in the Lorenz system, a turbulence shear flow and a model of a nuclear reactor.
5/16/2024
Enhanced LFTSformer: A Novel Long-Term Financial Time Series Prediction Model Using Advanced Feature Engineering and the DS Encoder Informer Architecture
Jianan Zhang, Hongyi Duan
0
0
This study presents a groundbreaking model for forecasting long-term financial time series, termed the Enhanced LFTSformer. The model distinguishes itself through several significant innovations: (1) VMD-MIC+FE Feature Engineering: The incorporation of sophisticated feature engineering techniques, specifically through the integration of Variational Mode Decomposition (VMD), Maximal Information Coefficient (MIC), and feature engineering (FE) methods, enables comprehensive perception and extraction of deep-level features from complex and variable financial datasets. (2) DS Encoder Informer: The architecture of the original Informer has been modified by adopting a Stacked Informer structure in the encoder, and an innovative introduction of a multi-head decentralized sparse attention mechanism, referred to as the Distributed Informer. This modification has led to a reduction in the number of attention blocks, thereby enhancing both the training accuracy and speed. (3) GC Enhanced Adam & Dynamic Loss Function: The deployment of a Gradient Clipping-enhanced Adam optimization algorithm and a dynamic loss function represents a pioneering approach within the domain of financial time series prediction. This novel methodology optimizes model performance and adapts more dynamically to evolving data patterns. Systematic experimentation on a range of benchmark stock market datasets demonstrates that the Enhanced LFTSformer outperforms traditional machine learning models and other Informer-based architectures in terms of prediction accuracy, adaptability, and generality. Furthermore, the paper identifies potential avenues for future enhancements, with a particular focus on the identification and quantification of pivotal impacting events and news. This is aimed at further refining the predictive efficacy of the model.
4/19/2024
New!An Embarrassingly Simple Approach to Enhance Transformer Performance in Genomic Selection for Crop Breeding
Renqi Chen, Wenwei Han, Haohao Zhang, Haoyang Su, Zhefan Wang, Xiaolei Liu, Hao Jiang, Wanli Ouyang, Nanqing Dong
0
0
Genomic selection (GS), as a critical crop breeding strategy, plays a key role in enhancing food production and addressing the global hunger crisis. The predominant approaches in GS currently revolve around employing statistical methods for prediction. However, statistical methods often come with two main limitations: strong statistical priors and linear assumptions. A recent trend is to capture the non-linear relationships between markers by deep learning. However, as crop datasets are commonly long sequences with limited samples, the robustness of deep learning models, especially Transformers, remains a challenge. In this work, to unleash the unexplored potential of attention mechanism for the task of interest, we propose a simple yet effective Transformer-based framework that enables end-to-end training of the whole sequence. Via experiments on rice3k and wheat3k datasets, we show that, with simple tricks such as k-mer tokenization and random masking, Transformer can achieve overall superior performance against seminal methods on GS tasks of interest.
5/17/2024