End User Authoring of Personalized Content Classifiers: Comparing Example Labeling, Rule Writing, and LLM Prompting

0

Sign in to get full access
Overview
- This paper compares different approaches for end-users to create personalized content classifiers: example labeling, rule writing, and prompting large language models (LLMs).
- The researchers conducted experiments to evaluate the effectiveness, efficiency, and user experience of these three approaches.
- They found that LLM prompting outperformed the other two methods in terms of accuracy, while rule writing was the fastest and most efficient approach.
- The paper provides insights into the tradeoffs between these authoring methods and their suitability for different user needs and use cases.
Plain English Explanation
The paper looks at ways for regular people, not just AI experts, to build their own custom content classifiers. Content classifiers are machine learning models that can automatically categorize or label different types of information, like whether an email is spam or not.
The researchers tested three different approaches:
- Example Labeling: Users provide examples of content they want to classify, and the system learns from those examples.
- Rule Writing: Users write if-then rules to specify how content should be classified.
- LLM Prompting: Users provide prompts to large language models, which then generate the content classifier.
The study found that the LLM prompting approach produced the most accurate classifiers, but the rule writing method was the fastest and easiest for users. The researchers discuss the tradeoffs between these different authoring approaches and how they might work best for different people's needs.
The key takeaway is that there are now more options for regular folks to build custom AI tools to help them manage their digital information, without needing advanced technical skills. This could empower people to create classifiers tailored to their personal preferences and workflows.
Technical Explanation
The paper examines three end-user authoring approaches for creating personalized content classifiers:
- Example Labeling: Users label examples of content as belonging to different classes, and a machine learning model is trained on those labeled examples.
- Rule Writing: Users write simple if-then rules to specify how content should be classified, without needing to train a model.
- LLM Prompting: Users provide prompts to large language models (LLMs), which then generate the classification logic.
The researchers conducted experiments to evaluate the effectiveness, efficiency, and user experience of these three authoring approaches. They had participants use each method to create classifiers for email spam detection and document topic categorization.
The results showed that the LLM prompting approach produced the most accurate classifiers, outperforming the other two methods. However, the rule writing approach was the fastest and most efficient for users. The researchers also found differences in the user experience, with some preferring the hands-on control of rule writing compared to the "black box" nature of LLM prompting.
The paper provides insights into the tradeoffs between these authoring methods and their suitability for different user needs and use cases. For example, LLM prompting may be better for complex classification tasks, while rule writing could be more appropriate for simpler, well-defined requirements.
Critical Analysis
The paper presents a thorough and well-designed study, but there are a few areas that could be explored further:
-
Generalization to other domains: The experiments focused on email spam detection and document topic categorization. It would be valuable to see how these authoring approaches perform on a wider range of classification tasks, such as sentiment analysis or intent recognition.
-
Long-term user experience: The study evaluated user experience during the authoring process, but it's unclear how users would feel about the classifiers over time, as their needs and preferences evolve. Longitudinal studies could provide insights into the maintainability and adaptability of the different authoring methods.
-
Transparency and explainability: While rule writing offers more transparency, the "black box" nature of LLM prompting may raise concerns about the interpretability and trustworthiness of the resulting classifiers. Further research could explore ways to improve the explainability of LLM-based authoring.
-
Scalability and collaboration: As users create more personalized classifiers, there may be challenges around managing and sharing these assets. Investigating scalable approaches and collaborative workflows could enhance the real-world applicability of these authoring methods.
Overall, this paper makes a valuable contribution by comparing different end-user authoring approaches and highlighting their respective strengths and tradeoffs. Continued research in this area could lead to more empowering and accessible AI tools for a wider range of users.
Conclusion
This paper presents a comprehensive study on end-user authoring of personalized content classifiers, comparing example labeling, rule writing, and LLM prompting approaches. The findings suggest that each method has its own advantages and is suited for different user needs and use cases.
The key takeaway is that there are now more options for regular people to build custom AI tools to help manage their digital information, without needing advanced technical skills. This could democratize the creation of personalized content classifiers and empower users to better organize, filter, and categorize the information they encounter.
As the capabilities of large language models continue to evolve, and as end-user authoring tools become more accessible, this area of research holds promise for enabling more people to harness the power of AI to suit their individual needs and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
End User Authoring of Personalized Content Classifiers: Comparing Example Labeling, Rule Writing, and LLM Prompting
Leijie Wang, Kathryn Yurechko, Pranati Dani, Quan Ze Chen, Amy X. Zhang
Existing tools for laypeople to create personal classifiers often assume a motivated user working uninterrupted in a single, lengthy session. However, users tend to engage with social media casually, with many short sessions on an ongoing, daily basis. To make creating personal classifiers for content curation easier for such users, tools should support rapid initialization and iterative refinement. In this work, we compare three strategies -- (1) example labeling, (2) rule writing, and (3) large language model (LLM) prompting -- for end users to build personal content classifiers. From an experiment with 37 non-programmers tasked with creating personalized comment moderation filters, we found that with LLM prompting, participants reached 95% of peak performance in 5 minutes, beating other strategies due to higher recall, but all strategies struggled with iterative refinement. Despite LLM prompting's better performance, participants preferred different strategies in different contexts and, even when prompting, provided examples or wrote rule-like prompts, suggesting hybrid approaches.
Read more9/6/2024
0
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
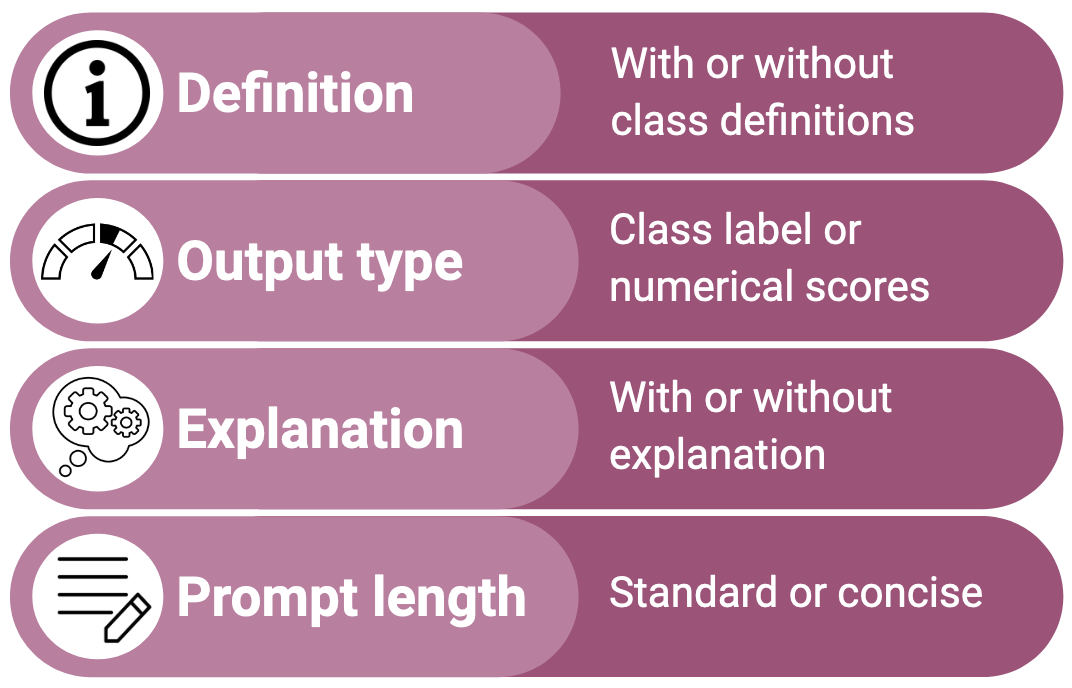
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
Read more6/19/2024
💬
0
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
Read more4/3/2024
💬
0
Large Language Models are Good Multi-lingual Learners : When LLMs Meet Cross-lingual Prompts
Teng Wang, Zhenqi He, Wing-Yin Yu, Xiaojin Fu, Xiongwei Han
With the advent of Large Language Models (LLMs), generating rule-based data for real-world applications has become more accessible. Due to the inherent ambiguity of natural language and the complexity of rule sets, especially in long contexts, LLMs often struggle to follow all specified rules, frequently omitting at least one. To enhance the reasoning and understanding of LLMs on long and complex contexts, we propose a novel prompting strategy Multi-Lingual Prompt, namely MLPrompt, which automatically translates the error-prone rule that an LLM struggles to follow into another language, thus drawing greater attention to it. Experimental results on public datasets across various tasks have shown MLPrompt can outperform state-of-the-art prompting methods such as Chain of Thought, Tree of Thought, and Self-Consistency. Additionally, we introduce a framework integrating MLPrompt with an auto-checking mechanism for structured data generation, with a specific case study in text-to-MIP instances. Further, we extend the proposed framework for text-to-SQL to demonstrate its generation ability towards structured data synthesis.
Read more9/18/2024