Enhanced Latent Multi-view Subspace Clustering

0

Sign in to get full access
Overview
- Presents a new method for multi-view subspace clustering that leverages complementary and consistent information across views
- Proposes an enhanced latent representation that captures the underlying structure of the data by jointly learning the clustering assignments and the latent representation
- Employs sparse regularization to promote a compact latent representation and improve clustering performance
Plain English Explanation
Multi-view data, where the same set of objects is represented from different perspectives or "views," can provide richer and more comprehensive information about the underlying structure of the data. Enhanced Latent Multi-view Subspace Clustering aims to leverage this complementary and consistent information across the views to improve the performance of subspace clustering.
The key idea is to jointly learn the clustering assignments and a shared latent representation that captures the intrinsic structure of the data. By enforcing sparsity on the latent representation, the method can promote a more compact and informative representation, leading to better clustering results.
The paper formulates this as an optimization problem and solves it using the Alternating Direction Method of Multipliers (ADMM) algorithm, a powerful technique for large-scale optimization problems. The authors demonstrate the effectiveness of their approach on several real-world multi-view datasets, showing improvements over state-of-the-art multi-view clustering methods.
Technical Explanation
Multi-view subspace clustering aims to cluster data points based on the underlying subspaces they lie in, leveraging information from multiple views of the same data. The Enhanced Latent Multi-view Subspace Clustering method extends this by jointly learning the clustering assignments and a shared latent representation that captures the complementary and consistent information across the views.
The key components of the proposed method are:
-
Latent Representation: The method learns a shared latent representation that encodes the underlying structure of the data, by enforcing consistency between the latent representation and the observed multi-view data.
-
Sparse Regularization: Sparse regularization is applied to the latent representation to promote a compact and informative latent space, which can improve the clustering performance.
-
Optimization: The optimization problem is solved using the Alternating Direction Method of Multipliers (ADMM), a powerful technique for large-scale optimization problems.
The authors demonstrate the effectiveness of their approach on several real-world multi-view datasets, including text, image, and video data, and show that it outperforms state-of-the-art multi-view clustering methods.
Critical Analysis
The Enhanced Latent Multi-view Subspace Clustering method presents a promising approach for improving multi-view clustering by jointly learning the clustering assignments and a shared latent representation. The use of sparse regularization to promote a compact latent representation is a well-motivated strategy, as it can help capture the underlying structure of the data more effectively.
However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the proposed method. For example, the sensitivity of the method to the choice of hyperparameters or the impact of the sparsity constraint on the interpretability of the learned latent representation could be further explored.
Additionally, while the authors demonstrate the effectiveness of their approach on several real-world datasets, it would be valuable to see how the method performs on a wider range of datasets, including those with different characteristics or levels of complexity.
Conclusion
Enhanced Latent Multi-view Subspace Clustering presents a novel method for multi-view subspace clustering that leverages the complementary and consistent information across views. By jointly learning the clustering assignments and a shared latent representation, and employing sparse regularization, the method can capture the underlying structure of the data more effectively, leading to improved clustering performance.
The technical contributions of the paper, particularly the use of ADMM for optimization and the incorporation of sparse regularization, provide a solid foundation for further research in this area. While the paper demonstrates the method's effectiveness on several real-world datasets, additional analysis of its limitations and broader applicability would be valuable for the research community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhanced Latent Multi-view Subspace Clustering
Long Shi, Lei Cao, Jun Wang, Badong Chen
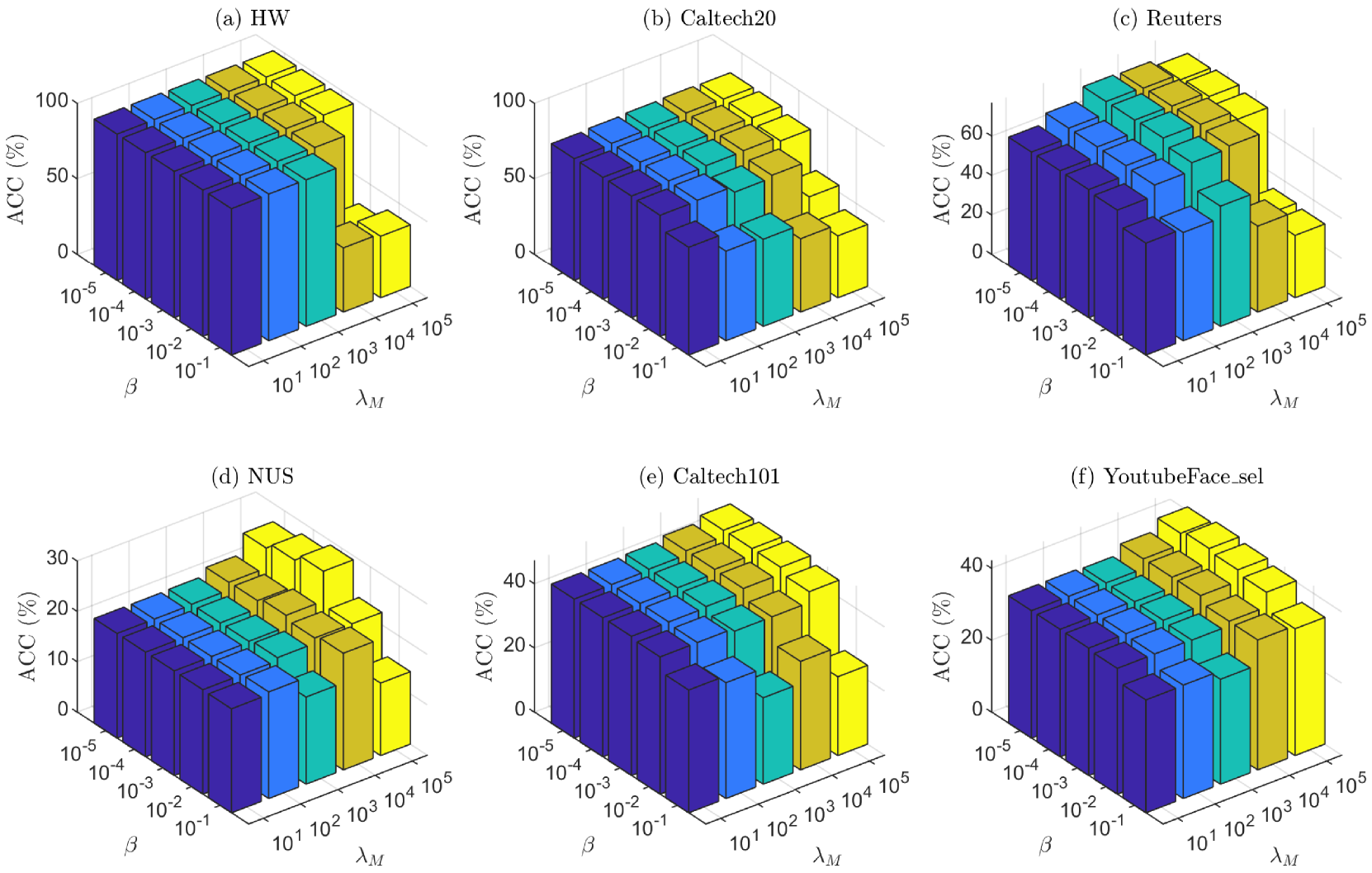
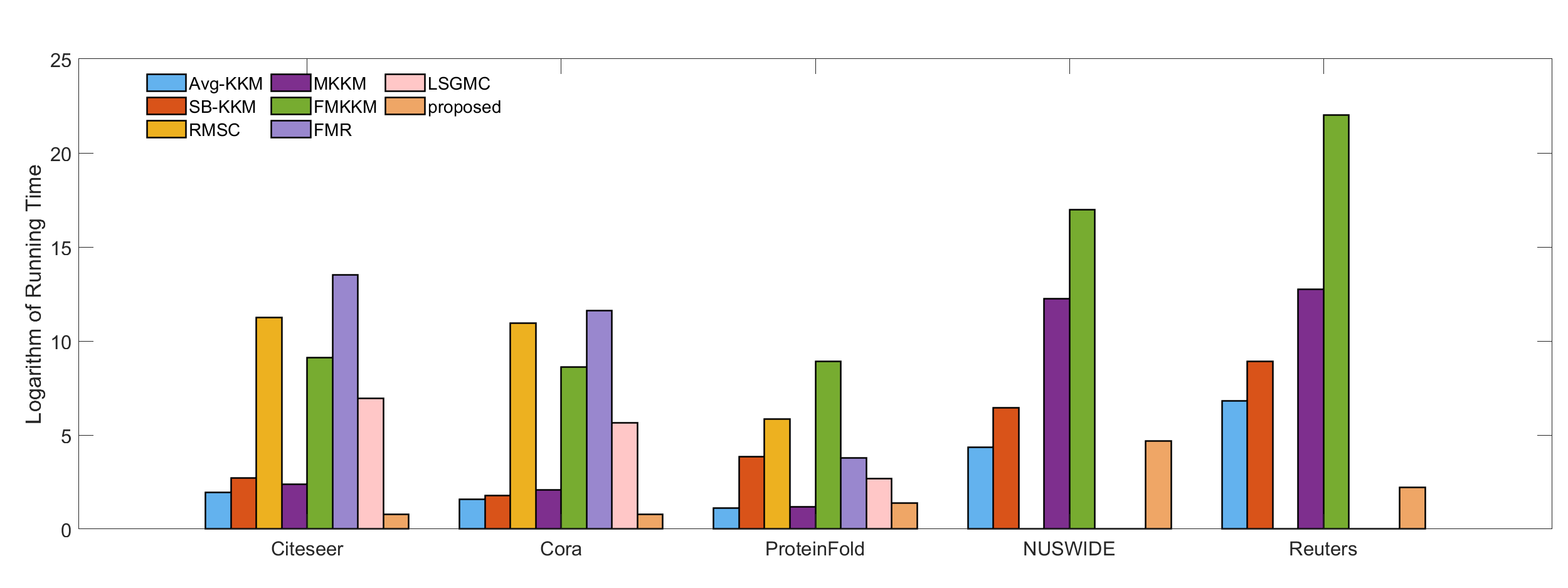
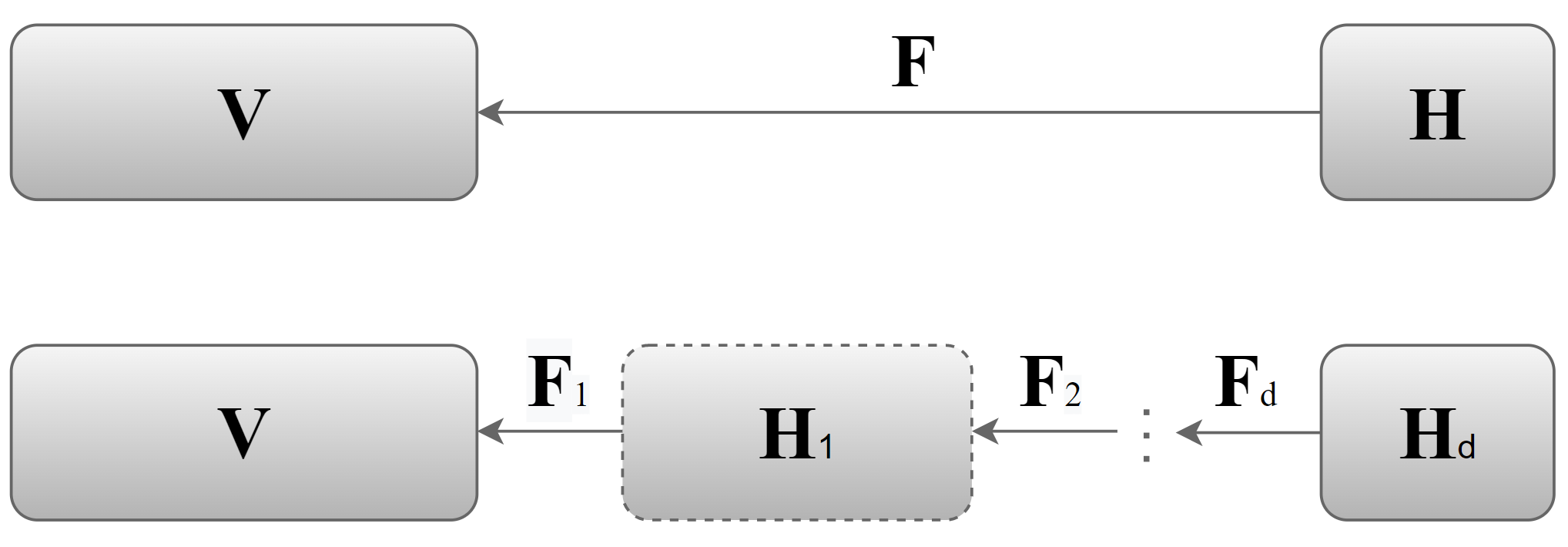
Latent multi-view subspace clustering has been demonstrated to have desirable clustering performance. However, the original latent representation method vertically concatenates the data matrices from multiple views into a single matrix along the direction of dimensionality to recover the latent representation matrix, which may result in an incomplete information recovery. To fully recover the latent space representation, we in this paper propose an Enhanced Latent Multi-view Subspace Clustering (ELMSC) method. The ELMSC method involves constructing an augmented data matrix that enhances the representation of multi-view data. Specifically, we stack the data matrices from various views into the block-diagonal locations of the augmented matrix to exploit the complementary information. Meanwhile, the non-block-diagonal entries are composed based on the similarity between different views to capture the consistent information. In addition, we enforce a sparse regularization for the non-diagonal blocks of the augmented self-representation matrix to avoid redundant calculations of consistency information. Finally, a novel iterative algorithm based on the framework of Alternating Direction Method of Multipliers (ADMM) is developed to solve the optimization problem for ELMSC. Extensive experiments on real-world datasets demonstrate that our proposed ELMSC is able to achieve higher clustering performance than some state-of-art multi-view clustering methods.
Read more8/28/2024
0
Fast and Scalable Semi-Supervised Learning for Multi-View Subspace Clustering
Huaming Ling, Chenglong Bao, Jiebo Song, Zuoqiang Shi
In this paper, we introduce a Fast and Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC) method, a novel solution to the high computational complexity commonly found in existing approaches. FSSMSC features linear computational and space complexity relative to the size of the data. The method generates a consensus anchor graph across all views, representing each data point as a sparse linear combination of chosen landmarks. Unlike traditional methods that manage the anchor graph construction and the label propagation process separately, this paper proposes a unified optimization model that facilitates simultaneous learning of both. An effective alternating update algorithm with convergence guarantees is proposed to solve the unified optimization model. Additionally, the method employs the obtained anchor graph and landmarks' low-dimensional representations to deduce low-dimensional representations for raw data. Following this, a straightforward clustering approach is conducted on these low-dimensional representations to achieve the final clustering results. The effectiveness and efficiency of FSSMSC are validated through extensive experiments on multiple benchmark datasets of varying scales.
Read more8/13/2024
0
One-Step Late Fusion Multi-view Clustering with Compressed Subspace
Qiyuan Ou, Pei Zhang, Sihang Zhou, En Zhu
Late fusion multi-view clustering (LFMVC) has become a rapidly growing class of methods in the multi-view clustering (MVC) field, owing to its excellent computational speed and clustering performance. One bottleneck faced by existing late fusion methods is that they are usually aligned to the average kernel function, which makes the clustering performance highly dependent on the quality of datasets. Another problem is that they require subsequent k-means clustering after obtaining the consensus partition matrix to get the final discrete labels, and the resulting separation of the label learning and cluster structure optimization processes limits the integrity of these models. To address the above issues, we propose an integrated framework named One-Step Late Fusion Multi-view Clustering with Compressed Subspace (OS-LFMVC-CS). Specifically, we use the consensus subspace to align the partition matrix while optimizing the partition fusion, and utilize the fused partition matrix to guide the learning of discrete labels. A six-step iterative optimization approach with verified convergence is proposed. Sufficient experiments on multiple datasets validate the effectiveness and efficiency of our proposed method.
Read more5/29/2024
0
Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent
Qiyuan Ou, Siwei Wang, Pei Zhang, Sihang Zhou, En Zhu
Multi-view clustering has attracted growing attention owing to its capabilities of aggregating information from various sources and its promising horizons in public affairs. Up till now, many advanced approaches have been proposed in recent literature. However, there are several ongoing difficulties to be tackled. One common dilemma occurs while attempting to align the features of different views. {Moreover, due to the fact that many existing multi-view clustering algorithms stem from spectral clustering, this results to cubic time complexity w.r.t. the number of dataset. However, we propose Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD) to tackle the discrepancy among views through hierarchical feature descent and project to a common subspace( STAGE 1), which reveals dependency of different views. We further reduce the computational complexity to linear time cost through a unified sampling strategy in the common subspace( STAGE 2), followed by anchor-based subspace clustering to learn the bipartite graph collectively( STAGE 3). }Extensive experimental results on public benchmark datasets demonstrate that our proposed model consistently outperforms the state-of-the-art techniques.
Read more4/10/2024