One-Step Late Fusion Multi-view Clustering with Compressed Subspace
2401.01558
0
0
Abstract
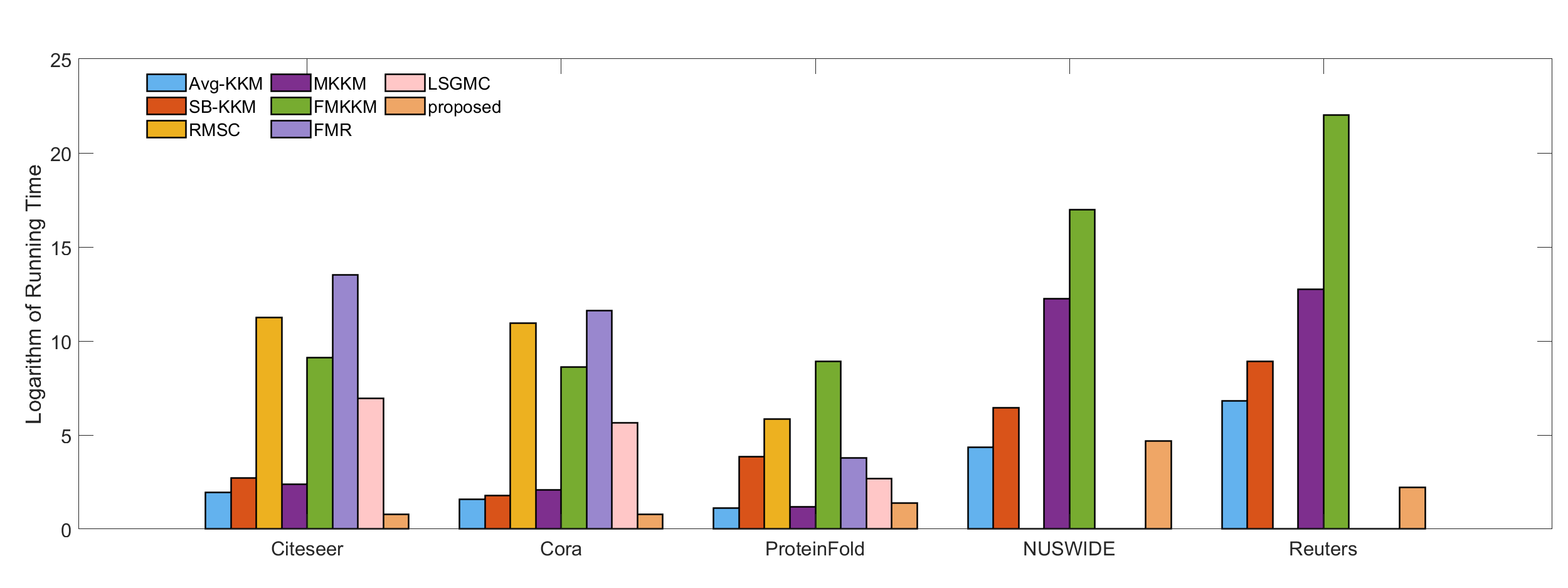
Late fusion multi-view clustering (LFMVC) has become a rapidly growing class of methods in the multi-view clustering (MVC) field, owing to its excellent computational speed and clustering performance. One bottleneck faced by existing late fusion methods is that they are usually aligned to the average kernel function, which makes the clustering performance highly dependent on the quality of datasets. Another problem is that they require subsequent k-means clustering after obtaining the consensus partition matrix to get the final discrete labels, and the resulting separation of the label learning and cluster structure optimization processes limits the integrity of these models. To address the above issues, we propose an integrated framework named One-Step Late Fusion Multi-view Clustering with Compressed Subspace (OS-LFMVC-CS). Specifically, we use the consensus subspace to align the partition matrix while optimizing the partition fusion, and utilize the fused partition matrix to guide the learning of discrete labels. A six-step iterative optimization approach with verified convergence is proposed. Sufficient experiments on multiple datasets validate the effectiveness and efficiency of our proposed method.
Create account to get full access
Overview
- Proposes a one-step late fusion multi-view clustering method with compressed subspace
- Aims to effectively leverage multiple data views while reducing computational complexity
- Introduces a novel optimization framework to learn a shared subspace and cluster assignments simultaneously
Plain English Explanation
The paper presents a new approach for multi-view clustering, which is the task of grouping data points that have been represented in multiple different ways (or "views"). The key idea is to find a shared low-dimensional subspace that captures the underlying structure across all the views, while also determining the cluster assignments for the data points.
This is done in a one-step process, rather than the more common two-step approach of first finding the subspace and then clustering. The authors argue that their "late fusion" method is more efficient and effective, as it allows the subspace learning and clustering to inform each other.
To keep the computational complexity manageable, the method also compresses the subspace representation, rather than working in the full high-dimensional space of the original data views. This compression step helps make the optimization tractable, without sacrificing too much of the relevant information.
Overall, this work provides a novel framework for tackling multi-view clustering problems, with potential applications in areas like multimedia analysis and hyperspectral image processing.
Technical Explanation
The paper proposes a "One-Step Late Fusion Multi-view Clustering with Compressed Subspace" (OLFC) method. The key elements are:
-
Shared Subspace Learning: OLFC aims to learn a shared low-dimensional subspace that captures the underlying structure across all the input data views. This is done by optimizing a matrix factorization objective that projects the multi-view data into the shared space.
-
Clustering: Simultaneously with the subspace learning, OLFC also determines the cluster assignments for the data points. This is achieved by incorporating a k-means-style clustering loss into the overall optimization.
-
Compression: To keep the computational complexity manageable, OLFC compresses the subspace representation by imposing a low-rank constraint on the projection matrices. This allows the method to work with a much smaller number of dimensions than the original high-dimensional views.
The authors formulate this as a unified optimization problem and provide an efficient alternating minimization algorithm to solve it. Experiments on several real-world multi-view datasets demonstrate the advantages of OLFC over previous multi-view clustering approaches, in terms of clustering accuracy and computational efficiency.
Critical Analysis
The paper makes a compelling case for the advantages of the proposed one-step late fusion approach over traditional two-step multi-view clustering methods. By jointly learning the shared subspace and cluster assignments, OLFC is able to better leverage the interactions between these two key components.
However, the paper does not address some potential limitations of the method. For example, the reliance on a low-rank subspace assumption may not be appropriate for all types of multi-view data, where the underlying structures could be more complex. Additionally, the optimization procedure, while efficient, still involves iterative updates that could be computationally expensive for very large-scale problems.
Further research could explore ways to relax the low-rank constraint, perhaps by using more flexible subspace representations, such as tensor-based approaches. Investigating the robustness of OLFC to noise or outliers in the input data views would also be a valuable direction for future work.
Conclusion
The proposed "One-Step Late Fusion Multi-view Clustering with Compressed Subspace" method provides a novel framework for effectively leveraging multiple data representations in clustering tasks. By jointly learning the shared subspace and cluster assignments, the approach is able to achieve strong performance while managing computational complexity through subspace compression.
This work has the potential to impact a variety of application domains that involve multi-view data, such as multimedia analysis and hyperspectral image processing. Further research to address the identified limitations and explore more flexible subspace representations could lead to even more powerful and versatile multi-view clustering solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent
Qiyuan Ou, Siwei Wang, Pei Zhang, Sihang Zhou, En Zhu
0
0
Multi-view clustering has attracted growing attention owing to its capabilities of aggregating information from various sources and its promising horizons in public affairs. Up till now, many advanced approaches have been proposed in recent literature. However, there are several ongoing difficulties to be tackled. One common dilemma occurs while attempting to align the features of different views. {Moreover, due to the fact that many existing multi-view clustering algorithms stem from spectral clustering, this results to cubic time complexity w.r.t. the number of dataset. However, we propose Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD) to tackle the discrepancy among views through hierarchical feature descent and project to a common subspace( STAGE 1), which reveals dependency of different views. We further reduce the computational complexity to linear time cost through a unified sampling strategy in the common subspace( STAGE 2), followed by anchor-based subspace clustering to learn the bipartite graph collectively( STAGE 3). }Extensive experimental results on public benchmark datasets demonstrate that our proposed model consistently outperforms the state-of-the-art techniques.
4/10/2024

How to characterize imprecision in multi-view clustering?
Jinyi Xu, Zuowei Zhang, Ze Lin, Yixiang Chen, Zhe Liu, Weiping Ding
0
0
It is still challenging to cluster multi-view data since existing methods can only assign an object to a specific (singleton) cluster when combining different view information. As a result, it fails to characterize imprecision of objects in overlapping regions of different clusters, thus leading to a high risk of errors. In this paper, we thereby want to answer the question: how to characterize imprecision in multi-view clustering? Correspondingly, we propose a multi-view low-rank evidential c-means based on entropy constraint (MvLRECM). The proposed MvLRECM can be considered as a multi-view version of evidential c-means based on the theory of belief functions. In MvLRECM, each object is allowed to belong to different clusters with various degrees of support (masses of belief) to characterize uncertainty when decision-making. Moreover, if an object is in the overlapping region of several singleton clusters, it can be assigned to a meta-cluster, defined as the union of these singleton clusters, to characterize the local imprecision in the result. In addition, entropy-weighting and low-rank constraints are employed to reduce imprecision and improve accuracy. Compared to state-of-the-art methods, the effectiveness of MvLRECM is demonstrated based on several toy and UCI real datasets.
4/9/2024

S^2MVTC: a Simple yet Efficient Scalable Multi-View Tensor Clustering
Zhen Long, Qiyuan Wang, Yazhou Ren, Yipeng Liu, Ce Zhu
0
0
Anchor-based large-scale multi-view clustering has attracted considerable attention for its effectiveness in handling massive datasets. However, current methods mainly seek the consensus embedding feature for clustering by exploring global correlations between anchor graphs or projection matrices.In this paper, we propose a simple yet efficient scalable multi-view tensor clustering (S^2MVTC) approach, where our focus is on learning correlations of embedding features within and across views. Specifically, we first construct the embedding feature tensor by stacking the embedding features of different views into a tensor and rotating it. Additionally, we build a novel tensor low-frequency approximation (TLFA) operator, which incorporates graph similarity into embedding feature learning, efficiently achieving smooth representation of embedding features within different views. Furthermore, consensus constraints are applied to embedding features to ensure inter-view semantic consistency. Experimental results on six large-scale multi-view datasets demonstrate that S^2MVTC significantly outperforms state-of-the-art algorithms in terms of clustering performance and CPU execution time, especially when handling massive data. The code of S^2MVTC is publicly available at https://github.com/longzhen520/S2MVTC.
4/12/2024
Fast Asymmetric Factorization for Large Scale Multiple Kernel Clustering
Yan Chen, Liang Du, Lei Duan
0
0
Kernel methods are extensively employed for nonlinear data clustering, yet their effectiveness heavily relies on selecting suitable kernels and associated parameters, posing challenges in advance determination. In response, Multiple Kernel Clustering (MKC) has emerged as a solution, allowing the fusion of information from multiple base kernels for clustering. However, both early fusion and late fusion methods for large-scale MKC encounter challenges in memory and time constraints, necessitating simultaneous optimization of both aspects. To address this issue, we propose Efficient Multiple Kernel Concept Factorization (EMKCF), which constructs a new sparse kernel matrix inspired by local regression to achieve memory efficiency. EMKCF learns consensus and individual representations by extending orthogonal concept factorization to handle multiple kernels for time efficiency. Experimental results demonstrate the efficiency and effectiveness of EMKCF on benchmark datasets compared to state-of-the-art methods. The proposed method offers a straightforward, scalable, and effective solution for large-scale MKC tasks.
5/28/2024