Enhancing Commentary Strategies for Imperfect Information Card Games: A Study of Large Language Models in Guandan Commentary
2406.17807
0
0
💬
Abstract
Recent advancements in large language models (LLMs) have unlocked the potential for generating high-quality game commentary. However, producing insightful and engaging commentary for complex games with incomplete information remains a significant challenge. In this paper, we introduce a novel commentary method that combine Reinforcement Learning (RL) and LLMs, tailored specifically for the Chinese card game textit{Guandan}. Our system leverages RL to generate intricate card-playing scenarios and employs LLMs to generate corresponding commentary text, effectively emulating the strategic analysis and narrative prowess of professional commentators. The framework comprises a state commentary guide, a Theory of Mind (ToM)-based strategy analyzer, and a style retrieval module, which seamlessly collaborate to deliver detailed and context-relevant game commentary in the Chinese language environment. We empower LLMs with ToM capabilities and refine both retrieval and information filtering mechanisms. This facilitates the generation of personalized commentary content. Our experimental results showcase the substantial enhancement in performance achieved by the proposed commentary framework when applied to open-source LLMs, surpassing the performance of GPT-4 across multiple evaluation metrics.
Create account to get full access
Overview
- Leveraging large language models (LLMs) to generate high-quality game commentary, particularly for complex games with incomplete information, remains a significant challenge.
- This paper introduces a novel commentary method that combines Reinforcement Learning (RL) and LLMs, tailored specifically for the Chinese card game
Guandan . - The framework comprises a state commentary guide, a Theory of Mind (ToM)-based strategy analyzer, and a style retrieval module, which work together to deliver detailed and context-relevant game commentary in the Chinese language environment.
Plain English Explanation
The paper describes a new way to generate high-quality commentary for complex games, like the Chinese card game
The key idea is to use RL to create detailed scenarios of how the game might unfold, and then use LLMs to generate commentary that explains the strategic thinking and narrates the gameplay. This mimics the kind of insightful analysis and engaging storytelling that professional commentators provide.
The system has three main components: a guide that helps the LLM understand the current state of the game, a "Theory of Mind" module that allows the LLM to reason about the players' strategies, and a style retrieval module that helps the LLM generate commentary that sounds natural and tailored to the game context.
By equipping the LLMs with these capabilities, the researchers were able to significantly improve the quality of the game commentary compared to using a general-purpose LLM like GPT-4. This suggests that this approach could be a valuable tool for enhancing the viewer experience in complex games and esports.
Technical Explanation
The paper presents a novel commentary generation framework that combines RL and LLMs to generate detailed and context-relevant game commentary for the complex Chinese card game
The proposed framework consists of three key components:
-
State Commentary Guide: This module provides the LLM with a detailed understanding of the current state of the game, including the cards played, player positions, and other relevant information.
-
Theory of Mind (ToM)-based Strategy Analyzer: This component allows the LLM to reason about the players' strategies and likely future actions, drawing on ToM capabilities.
-
Style Retrieval Module: This module helps the LLM generate commentary that is tailored to the game context and sounds natural, by retrieving and adapting relevant commentary styles.
The researchers trained this framework using RL to generate intricate game scenarios, and then used LLMs to produce the corresponding commentary text. This approach allowed the system to emulate the strategic analysis and narrative prowess of professional commentators.
The experimental results show that the proposed commentary framework significantly outperforms standalone LLMs, such as GPT-4, across multiple evaluation metrics when applied to the
Critical Analysis
The paper presents a promising approach to leveraging LLMs for generating game commentary, particularly for complex games like
However, the paper does not explore the potential limitations or biases of the approach. For example, the reliance on RL to generate game scenarios could lead to biases in the types of scenarios considered, and the use of LLMs could introduce biases in the generated commentary.
Additionally, the paper does not discuss the potential ethical considerations of using AI-generated game commentary, such as the impact on the viewer experience or the potential for misuse or manipulation.
Further research is needed to explore the broader effectiveness of LLMs as annotators and to uncover the strategic reasoning limitations of LLMs in the context of game commentary. Addressing these areas could lead to more robust and reliable commentary generation systems.
Conclusion
This paper presents a novel approach to leveraging LLMs for generating high-quality game commentary, specifically for the complex Chinese card game
The experimental results demonstrate a significant improvement in commentary quality compared to standalone LLMs, suggesting that this approach could be a valuable tool for enhancing the viewer experience in complex games and esports. However, the paper also highlights the need for further research to address potential limitations and ethical considerations.
Overall, the paper's contribution to the field of AI-generated game commentary is a promising step forward, and it encourages readers to think critically about the possibilities and challenges of leveraging LLMs in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generating Games via LLMs: An Investigation with Video Game Description Language
Chengpeng Hu, Yunlong Zhao, Jialin Liu
0
0
Recently, the emergence of large language models (LLMs) has unlocked new opportunities for procedural content generation. However, recent attempts mainly focus on level generation for specific games with defined game rules such as Super Mario Bros. and Zelda. This paper investigates the game generation via LLMs. Based on video game description language, this paper proposes an LLM-based framework to generate game rules and levels simultaneously. Experiments demonstrate how the framework works with prompts considering different combinations of context. Our findings extend the current applications of LLMs and offer new insights for generating new games in the area of procedural content generation.
5/31/2024
GTBench: Uncovering the Strategic Reasoning Limitations of LLMs via Game-Theoretic Evaluations
Jinhao Duan, Renming Zhang, James Diffenderfer, Bhavya Kailkhura, Lichao Sun, Elias Stengel-Eskin, Mohit Bansal, Tianlong Chen, Kaidi Xu
0
0
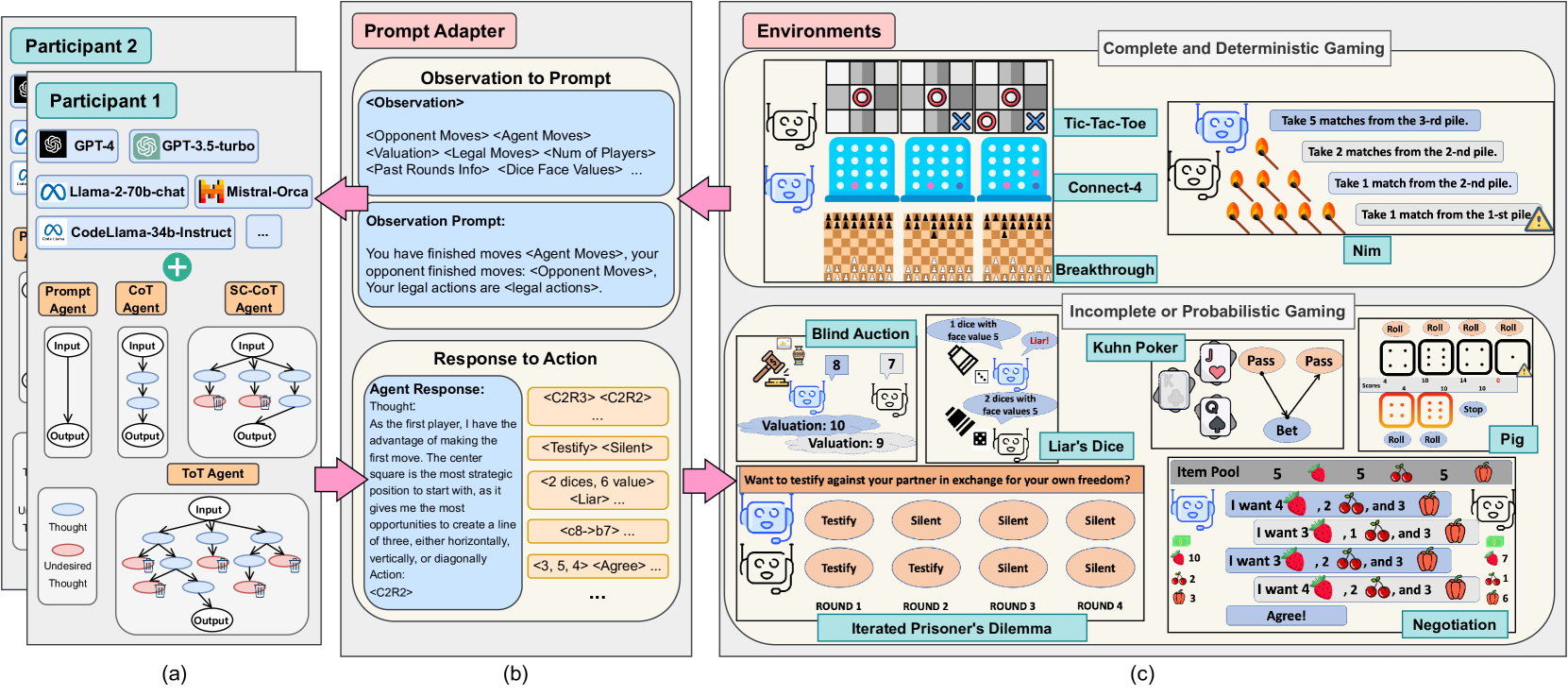
As Large Language Models (LLMs) are integrated into critical real-world applications, their strategic and logical reasoning abilities are increasingly crucial. This paper evaluates LLMs' reasoning abilities in competitive environments through game-theoretic tasks, e.g., board and card games that require pure logic and strategic reasoning to compete with opponents. We first propose GTBench, a language-driven environment composing 10 widely recognized tasks, across a comprehensive game taxonomy: complete versus incomplete information, dynamic versus static, and probabilistic versus deterministic scenarios. Then, we (1) Characterize the game-theoretic reasoning of LLMs; and (2) Perform LLM-vs.-LLM competitions as reasoning evaluation. We observe that (1) LLMs have distinct behaviors regarding various gaming scenarios; for example, LLMs fail in complete and deterministic games yet they are competitive in probabilistic gaming scenarios; (2) Most open-source LLMs, e.g., CodeLlama-34b-Instruct and Llama-2-70b-chat, are less competitive than commercial LLMs, e.g., GPT-4, in complex games, yet the recently released Llama-3-70b-Instruct makes up for this shortcoming. In addition, code-pretraining greatly benefits strategic reasoning, while advanced reasoning methods such as Chain-of-Thought (CoT) and Tree-of-Thought (ToT) do not always help. We further characterize the game-theoretic properties of LLMs, such as equilibrium and Pareto Efficiency in repeated games. Detailed error profiles are provided for a better understanding of LLMs' behavior. We hope our research provides standardized protocols and serves as a foundation to spur further explorations in the strategic reasoning of LLMs.
6/11/2024
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024
TeaMs-RL: Teaching LLMs to Teach Themselves Better Instructions via Reinforcement Learning
Shangding Gu, Alois Knoll, Ming Jin
0
0
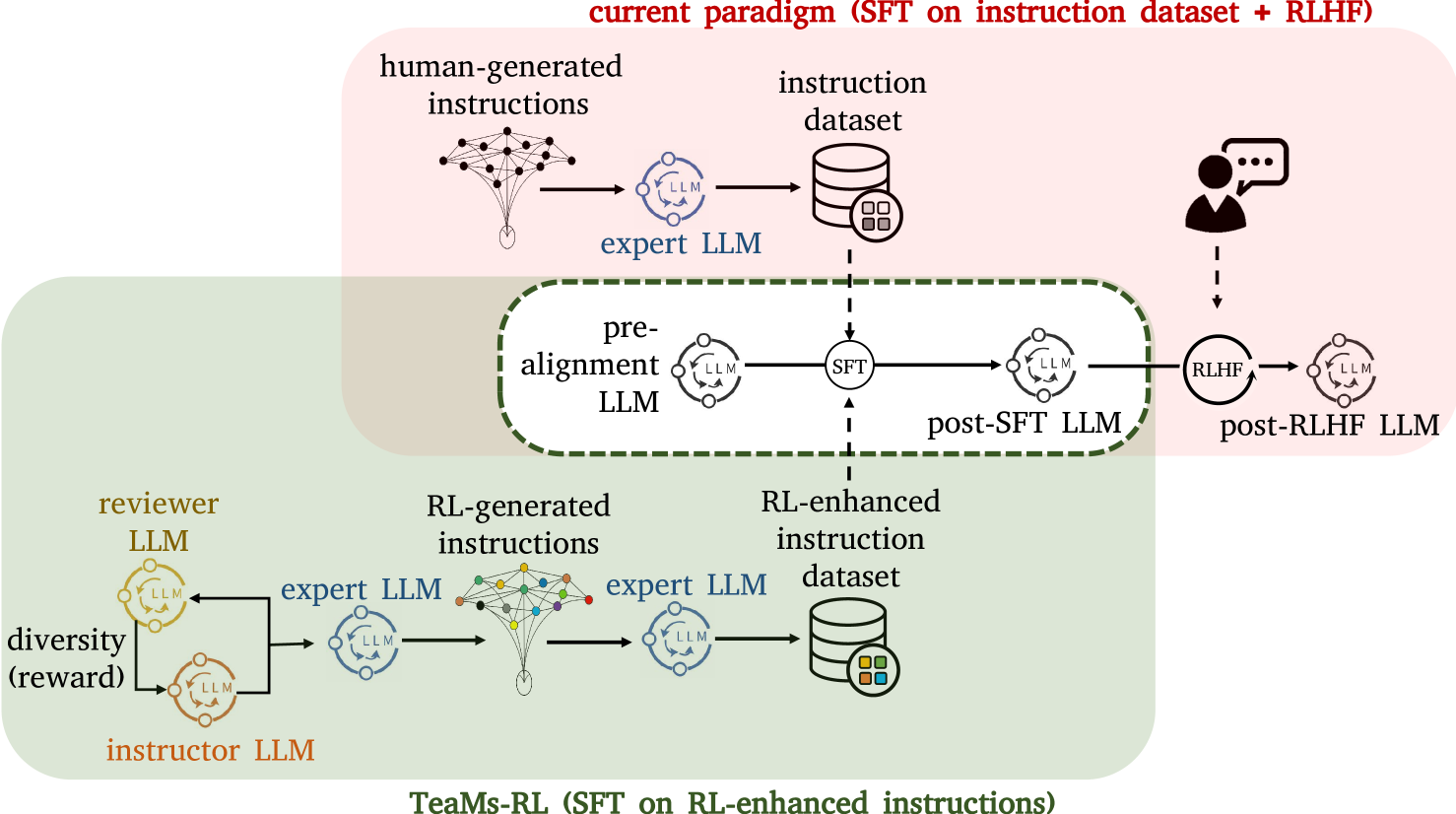
The development of Large Language Models (LLMs) often confronts challenges stemming from the heavy reliance on human annotators in the reinforcement learning with human feedback (RLHF) framework, or the frequent and costly external queries tied to the self-instruct paradigm. In this work, we pivot to Reinforcement Learning (RL) -- but with a twist. Diverging from the typical RLHF, which refines LLMs following instruction data training, we use RL to directly generate the foundational instruction dataset that alone suffices for fine-tuning. Our method, TeaMs-RL, uses a suite of textual operations and rules, prioritizing the diversification of training datasets. It facilitates the generation of high-quality data without excessive reliance on external advanced models, paving the way for a single fine-tuning step and negating the need for subsequent RLHF stages. Our findings highlight key advantages of our approach: reduced need for human involvement and fewer model queries (only $5.73%$ of WizardLM's total), along with enhanced capabilities of LLMs in crafting and comprehending complex instructions compared to strong baselines, and substantially improved model privacy protection.
5/7/2024