Enhancing In-Context Learning via Implicit Demonstration Augmentation
2407.00100
0
0
Abstract
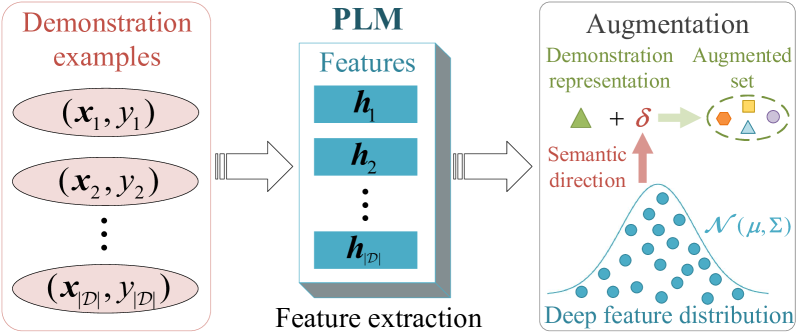
The emergence of in-context learning (ICL) enables large pre-trained language models (PLMs) to make predictions for unseen inputs without updating parameters. Despite its potential, ICL's effectiveness heavily relies on the quality, quantity, and permutation of demonstrations, commonly leading to suboptimal and unstable performance. In this paper, we tackle this challenge for the first time from the perspective of demonstration augmentation. Specifically, we start with enriching representations of demonstrations by leveraging their deep feature distribution. We then theoretically reveal that when the number of augmented copies approaches infinity, the augmentation is approximately equal to a novel logit calibration mechanism integrated with specific statistical properties. This insight results in a simple yet highly efficient method that significantly improves the average and worst-case accuracy across diverse PLMs and tasks. Moreover, our method effectively reduces performance variance among varying demonstrations, permutations, and templates, and displays the capability to address imbalanced class distributions.
Create account to get full access
Overview
- This paper explores a novel technique called "Implicit Demonstration Augmentation" to enhance in-context learning, a powerful approach for language models to learn new tasks by observing a few examples.
- The key idea is to automatically generate additional "implicit demonstrations" that capture the underlying reasoning and problem-solving steps, going beyond the surface-level input-output pairs.
- The authors demonstrate the effectiveness of this approach on a range of tasks, showing significant improvements in few-shot learning performance compared to standard in-context learning.
Plain English Explanation
The paper focuses on a technique called Implicit Context Learning that aims to improve how language models learn new tasks from just a few examples. The core insight is that simply showing the model input-output pairs may not be enough - the model also needs to understand the underlying reasoning and problem-solving steps.
To address this, the researchers developed a way to automatically generate "implicit demonstrations" that capture this additional context. For example, if the task is to solve math problems, the implicit demonstrations could show the step-by-step workings, not just the final answer. Let's Learn Step-by-Step: Enhancing Context for Few-Shot Learning explores a similar concept.
By incorporating these implicit demonstrations into the training process, the language model can learn more effectively from just a handful of examples. The authors tested this approach on a variety of tasks and found significant improvements in the model's few-shot learning performance compared to standard in-context learning.
The key innovation is this idea of Demonstration Selection via Influence Analysis - automatically generating the most informative implicit demonstrations to complement the original examples. This helps the model rapidly acquire new skills without requiring massive amounts of training data.
Technical Explanation
The paper introduces a novel technique called "Implicit Demonstration Augmentation" (IDA) to enhance in-context learning, a powerful few-shot learning paradigm where language models learn new tasks by observing just a few examples.
The core idea is to automatically generate additional "implicit demonstrations" that capture the underlying reasoning and problem-solving steps, going beyond the surface-level input-output pairs typically provided in in-context learning. For example, for a math problem, the implicit demonstrations could show the step-by-step workings rather than just the final answer.
The authors propose an Implicit Context Learning framework that first trains a contextual decomposition model to extract these implicit demonstrations from the original examples. Then, during in-context learning, the language model is presented with both the original examples and the generated implicit demonstrations.
Through extensive experiments across various tasks, the authors demonstrate the effectiveness of this Implicit Demonstration Augmentation approach. Compared to standard in-context learning, their method achieves significant improvements in few-shot learning performance, allowing the model to rapidly acquire new skills from just a handful of examples.
The key technical innovation is the Demonstration Selection via Influence Analysis component, which selects the most informative implicit demonstrations to complement the original examples. This helps the model focus on the essential problem-solving steps and reasoning, unifying demonstration selection, compression, and context learning.
Critical Analysis
The paper presents a compelling approach to enhancing in-context learning, a crucial capability for language models to quickly adapt to new tasks and domains. The authors' key insight - that simply showing input-output pairs may not be enough, and the model also needs to understand the underlying reasoning - is an important one that deserves further exploration.
One potential limitation of the work is the reliance on a separate "contextual decomposition" model to extract the implicit demonstrations. While this allows for flexibility in the types of demonstrations generated, it also introduces an additional component that must be trained and integrated into the overall system. A more unified approach that can directly generate the implicit demonstrations within the main language model architecture may be an area for future research.
Additionally, the paper focuses on a relatively narrow set of tasks, primarily involving language and reasoning. It would be interesting to see how the Implicit Demonstration Augmentation approach performs on a broader range of domains, such as visual or multimodal tasks, to better understand its generalizability.
Overall, this research represents an important step forward in enhancing the few-shot learning capabilities of language models. By incorporating more contextual information beyond just input-output pairs, the authors have demonstrated a promising path towards more efficient and effective in-context learning.
Conclusion
The paper introduces a novel technique called "Implicit Demonstration Augmentation" that significantly improves the few-shot learning performance of language models. By automatically generating additional "implicit demonstrations" that capture the underlying reasoning and problem-solving steps, the authors show that language models can more effectively learn new tasks from just a handful of examples.
This research highlights the importance of going beyond simple input-output pairs in in-context learning and instead providing the model with richer contextual information. The Implicit Context Learning framework and Demonstration Selection via Influence Analysis techniques developed in this work represent an important step towards more efficient and effective few-shot learning, with potential applications across a wide range of domains.
As language models continue to grow in capability and importance, enhancing their ability to quickly adapt to new tasks and environments will be crucial. The insights and approaches presented in this paper offer a promising direction for further research and development in this area, with the ultimate goal of building more versatile and capable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Demonstration Augmentation for Zero-shot In-context Learning
Yi Su, Yunpeng Tai, Yixin Ji, Juntao Li, Bowen Yan, Min Zhang
0
0
Large Language Models (LLMs) have demonstrated an impressive capability known as In-context Learning (ICL), which enables them to acquire knowledge from textual demonstrations without the need for parameter updates. However, many studies have highlighted that the model's performance is sensitive to the choice of demonstrations, presenting a significant challenge for practical applications where we lack prior knowledge of user queries. Consequently, we need to construct an extensive demonstration pool and incorporate external databases to assist the model, leading to considerable time and financial costs. In light of this, some recent research has shifted focus towards zero-shot ICL, aiming to reduce the model's reliance on external information by leveraging their inherent generative capabilities. Despite the effectiveness of these approaches, the content generated by the model may be unreliable, and the generation process is time-consuming. To address these issues, we propose Demonstration Augmentation for In-context Learning (DAIL), which employs the model's previously predicted historical samples as demonstrations for subsequent ones. DAIL brings no additional inference cost and does not rely on the model's generative capabilities. Our experiments reveal that DAIL can significantly improve the model's performance over direct zero-shot inference and can even outperform few-shot ICL without any external information.
6/4/2024
👨🏫
Implicit In-context Learning
Zhuowei Li, Zihao Xu, Ligong Han, Yunhe Gao, Song Wen, Di Liu, Hao Wang, Dimitris N. Metaxas
0
0
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of task-ids, enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.
5/24/2024
🌿
Let's Learn Step by Step: Enhancing In-Context Learning Ability with Curriculum Learning
Yinpeng Liu, Jiawei Liu, Xiang Shi, Qikai Cheng, Yong Huang, Wei Lu
0
0
Demonstration ordering, which is an important strategy for in-context learning (ICL), can significantly affects the performance of large language models (LLMs). However, most of the current approaches of ordering require high computational costs to introduce the priori knowledge. In this paper, inspired by the human learning process, we propose a simple but effective demonstration ordering method for ICL, named the few-shot In-Context Curriculum Learning (ICCL). The ICCL implies gradually increasing the complexity of prompt demonstrations during the inference process. The difficulty can be assessed by human experts or LLMs-driven metrics, such as perplexity. Then we design extensive experiments to discuss the effectiveness of the ICCL at both corpus-level and instance-level. Moreover, we also investigate the formation mechanism of LLM's ICCL capability. Experimental results demonstrate that ICCL, developed during the instruction-tuning stage, is effective for representative open-source LLMs. To facilitate further research and applications by other scholars, we make the code publicly available.
6/18/2024
🌿
In-Context Learning Demonstration Selection via Influence Analysis
Vinay M. S., Minh-Hao Van, Xintao Wu
0
0
Large Language Models (LLMs) have showcased their In-Context Learning (ICL) capabilities, enabling few-shot learning without the need for gradient updates. Despite its advantages, the effectiveness of ICL heavily depends on the choice of demonstrations. Selecting the most effective demonstrations for ICL remains a significant research challenge. To tackle this issue, we propose a demonstration selection method named InfICL, which utilizes influence functions to analyze impacts of training samples. By identifying the most influential training samples as demonstrations, InfICL aims to enhance the ICL generalization performance. To keep InfICL cost-effective, we only use the LLM to generate sample input embeddings, avoiding expensive fine-tuning. Through empirical studies on various real-world datasets, we demonstrate advantages of InfICL compared to state-of-the-art baselines.
6/19/2024