Enhancing context models for point cloud geometry compression with context feature residuals and multi-loss

0
Sign in to get full access
Overview
- The paper proposes enhancements to context models for point cloud geometry compression, including the use of context feature residuals and a multi-loss approach.
- The key ideas are to better capture local and global context information to improve the compression performance of point cloud data.
- The authors evaluate their methods on standard point cloud datasets and compare to existing compression techniques.
Plain English Explanation
Point clouds are a way of representing 3D objects and environments digitally, using a collection of individual data points. Compressing these point cloud datasets is important for efficient storage and transmission, especially for applications like virtual reality, robotics, and 3D mapping.
The researchers in this paper focus on improving the "context models" used in point cloud compression. Context models try to predict the position of each point based on the surrounding points. By enhancing how these models capture local and global context information, the compression can become more effective.
Specifically, the paper introduces two key ideas:
- Context Feature Residuals: Instead of just predicting the point positions directly, the model also predicts "residual" information about the local features around each point. This additional context helps the model make more accurate predictions.
- Multi-Loss: The model is trained using a combination of different loss functions, rather than just a single objective. This encourages the model to learn representations that are more useful for compression.
By incorporating these enhancements, the researchers show that their approach can outperform previous point cloud compression methods in terms of rate-distortion performance - meaning they can achieve higher compression ratios without sacrificing the quality of the reconstructed point clouds.
Technical Explanation
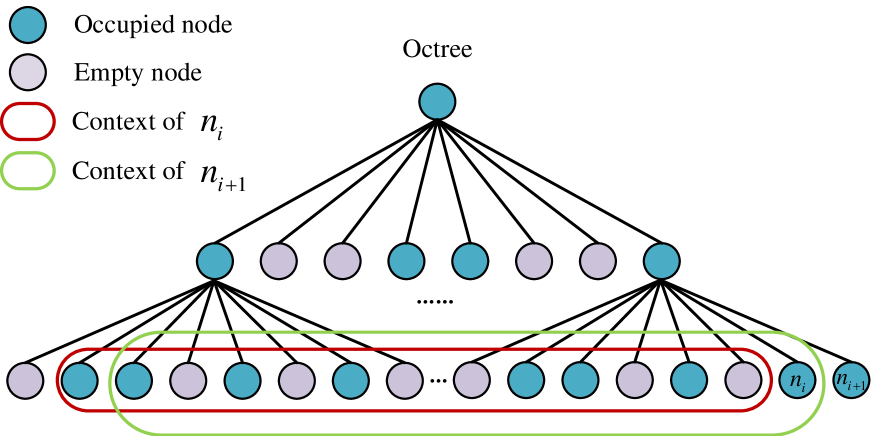
The paper builds upon octree-based context models for point cloud compression. These models capture the spatial relationships between points by partitioning the 3D space hierarchically using an octree structure.
The key contributions of this work are:
-
Context Feature Residuals: Instead of just predicting the point coordinates directly, the proposed model also predicts a "residual" vector that encodes additional context information about the local point cloud features around each point. This residual helps the model make more accurate predictions of the point positions.
-
Multi-Loss Training: The model is trained using a combination of several loss functions, including point position reconstruction, point normal reconstruction, and the context feature residual. This multi-loss approach encourages the model to learn more useful representations for compression.
The authors evaluate their approach on standard point cloud datasets and compare to state-of-the-art methods like Point Cloud Compression with Implicit Neural Representations and GeoCC: Geometrically Enhanced 3D Occupancy Network. They show that their enhancements to the context model lead to improved rate-distortion performance, allowing for higher compression ratios without sacrificing reconstruction quality.
Critical Analysis
The paper makes a solid technical contribution by introducing novel ways to enhance context models for point cloud compression. The authors thoughtfully address limitations of prior work, such as the need to better capture local and global context information.
One potential area for further research is exploring even richer representations of the local point cloud structure beyond just the residual vector. The paper suggests that incorporating additional features like normals is helpful, so there may be room to explore other geometric or semantic cues that could further improve the context modeling.
Additionally, the paper focuses on the compression performance metrics, but does not deeply analyze the computational complexity or inference time of the proposed approach. For practical applications, these efficiency considerations may also be important.
Overall, the work represents a valuable advance in point cloud compression research, with a clear path for further refinements and extensions. The authors have demonstrated the benefits of carefully designing the model architecture and training objectives to better leverage the underlying structure of point cloud data.
Conclusion
This paper introduces two key enhancements to context models for point cloud geometry compression: the use of context feature residuals and a multi-loss training approach. By more effectively capturing both local and global context information, the proposed model achieves improved rate-distortion performance compared to prior state-of-the-art methods.
The insights from this work could have broad implications for 3D data compression in applications like virtual reality, robotics, and 3D mapping, where efficient storage and transmission of point cloud data is crucial. The authors have demonstrated the value of thoughtfully designing neural network architectures and training objectives to better leverage the underlying structure of 3D point cloud data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing context models for point cloud geometry compression with context feature residuals and multi-loss
Chang Sun, Hui Yuan, Shuai Li, Xin Lu, Raouf Hamzaoui
In point cloud geometry compression, context models usually use the one-hot encoding of node occupancy as the label, and the cross-entropy between the one-hot encoding and the probability distribution predicted by the context model as the loss function. However, this approach has two main weaknesses. First, the differences between contexts of different nodes are not significant, making it difficult for the context model to accurately predict the probability distribution of node occupancy. Second, as the one-hot encoding is not the actual probability distribution of node occupancy, the cross-entropy loss function is inaccurate. To address these problems, we propose a general structure that can enhance existing context models. We introduce the context feature residuals into the context model to amplify the differences between contexts. We also add a multi-layer perception branch, that uses the mean squared error between its output and node occupancy as a loss function to provide accurate gradients in backpropagation. We validate our method by showing that it can improve the performance of an octree-based model (OctAttention) and a voxel-based model (VoxelDNN) on the object point cloud datasets MPEG 8i and MVUB, as well as the LiDAR point cloud dataset SemanticKITTI.
Read more7/12/2024

0
Enhancing octree-based context models for point cloud geometry compression with attention-based child node number prediction
Chang Sun, Hui Yuan, Xiaolong Mao, Xin Lu, Raouf Hamzaoui
In point cloud geometry compression, most octreebased context models use the cross-entropy between the onehot encoding of node occupancy and the probability distribution predicted by the context model as the loss. This approach converts the problem of predicting the number (a regression problem) and the position (a classification problem) of occupied child nodes into a 255-dimensional classification problem. As a result, it fails to accurately measure the difference between the one-hot encoding and the predicted probability distribution. We first analyze why the cross-entropy loss function fails to accurately measure the difference between the one-hot encoding and the predicted probability distribution. Then, we propose an attention-based child node number prediction (ACNP) module to enhance the context models. The proposed module can predict the number of occupied child nodes and map it into an 8- dimensional vector to assist the context model in predicting the probability distribution of the occupancy of the current node for efficient entropy coding. Experimental results demonstrate that the proposed module enhances the coding efficiency of octree-based context models.
Read more7/12/2024
0
Fast Point Cloud Geometry Compression with Context-based Residual Coding and INR-based Refinement
Hao Xu, Xi Zhang, Xiaolin Wu
Compressing a set of unordered points is far more challenging than compressing images/videos of regular sample grids, because of the difficulties in characterizing neighboring relations in an irregular layout of points. Many researchers resort to voxelization to introduce regularity, but this approach suffers from quantization loss. In this research, we use the KNN method to determine the neighborhoods of raw surface points. This gives us a means to determine the spatial context in which the latent features of 3D points are compressed by arithmetic coding. As such, the conditional probability model is adaptive to local geometry, leading to significant rate reduction. Additionally, we propose a dual-layer architecture where a non-learning base layer reconstructs the main structures of the point cloud at low complexity, while a learned refinement layer focuses on preserving fine details. This design leads to reductions in model complexity and coding latency by two orders of magnitude compared to SOTA methods. Moreover, we incorporate an implicit neural representation (INR) into the refinement layer, allowing the decoder to sample points on the underlying surface at arbitrary densities. This work is the first to effectively exploit content-aware local contexts for compressing irregular raw point clouds, achieving high rate-distortion performance, low complexity, and the ability to function as an arbitrary-scale upsampling network simultaneously.
Read more8/7/2024

0
Point Cloud Compression with Implicit Neural Representations: A Unified Framework
Hongning Ruan, Yulin Shao, Qianqian Yang, Liang Zhao, Dusit Niyato
Point clouds have become increasingly vital across various applications thanks to their ability to realistically depict 3D objects and scenes. Nevertheless, effectively compressing unstructured, high-precision point cloud data remains a significant challenge. In this paper, we present a pioneering point cloud compression framework capable of handling both geometry and attribute components. Unlike traditional approaches and existing learning-based methods, our framework utilizes two coordinate-based neural networks to implicitly represent a voxelized point cloud. The first network generates the occupancy status of a voxel, while the second network determines the attributes of an occupied voxel. To tackle an immense number of voxels within the volumetric space, we partition the space into smaller cubes and focus solely on voxels within non-empty cubes. By feeding the coordinates of these voxels into the respective networks, we reconstruct the geometry and attribute components of the original point cloud. The neural network parameters are further quantized and compressed. Experimental results underscore the superior performance of our proposed method compared to the octree-based approach employed in the latest G-PCC standards. Moreover, our method exhibits high universality when contrasted with existing learning-based techniques.
Read more5/21/2024