Enhancing Cross-Modality Synthesis: Subvolume Merging for MRI-to-CT Conversion

0
Sign in to get full access
Overview
- The paper presents a novel method for enhancing cross-modality synthesis, specifically for converting MRI scans to their corresponding CT scans.
- The key innovation is a "subvolume merging" technique that combines the outputs of a Swin Transformer model to produce higher-quality CT images.
- The authors demonstrate improved performance on various evaluation metrics compared to prior state-of-the-art methods.
Plain English Explanation
Magnetic Resonance Imaging (MRI) and Computed Tomography (CT) are two common medical imaging techniques used by doctors to diagnose and monitor various health conditions. While MRI scans provide excellent soft tissue contrast, CT scans are better at capturing bone and other dense structures.
Enhancing Cross-Modality Synthesis: Subvolume Merging for MRI-to-CT Conversion proposes a method to automatically convert MRI scans into their corresponding CT scans. This is useful because it allows doctors to leverage the complementary information from both imaging modalities without the need for additional scans, which can be time-consuming and expose patients to more radiation.
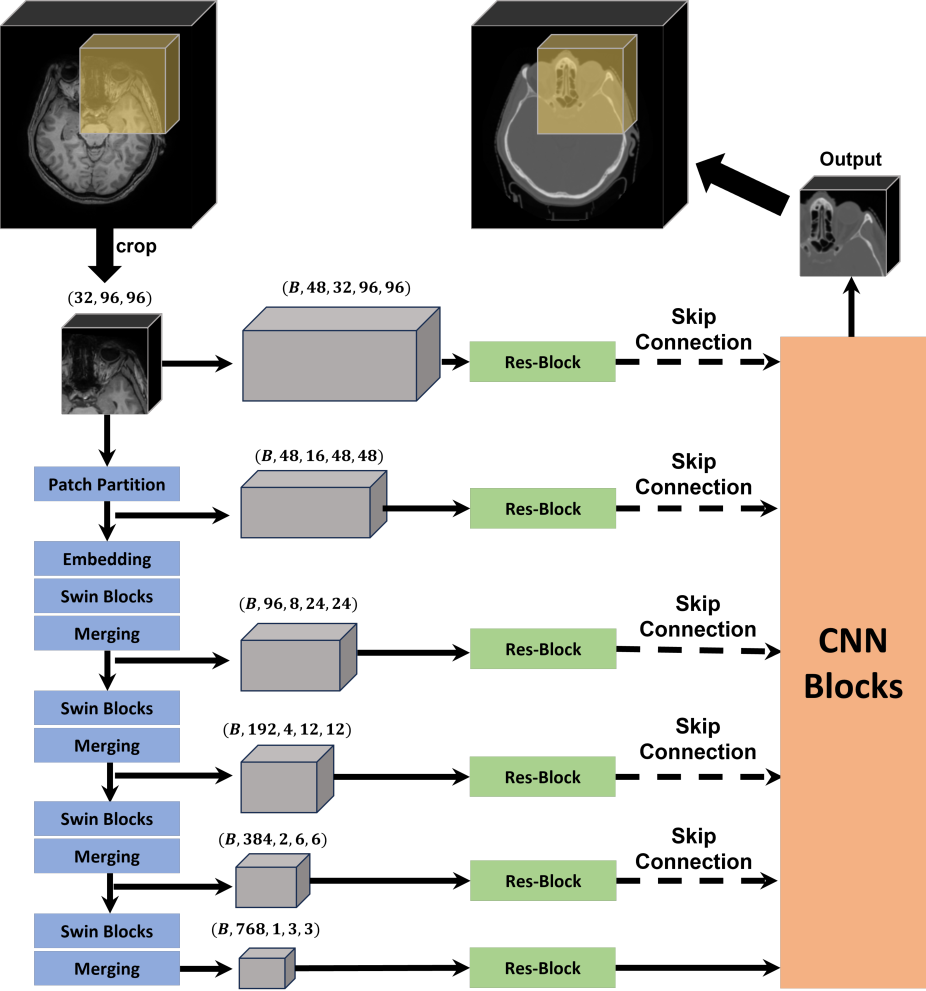
The key innovation in this paper is a "subvolume merging" technique. The authors first divide the input MRI scan into smaller 3D subvolumes, and then use a machine learning model called a Swin Transformer to predict the corresponding CT subvolumes. Finally, they merge these predicted subvolumes back together to reconstruct the full CT scan.
This approach allows the model to focus on smaller, more manageable regions of the image, which can improve the overall quality of the predicted CT scan compared to trying to generate the entire scan at once. The authors demonstrate that their method outperforms previous state-of-the-art techniques on various evaluation metrics, bringing us closer to the goal of seamlessly integrating MRI and CT data for more comprehensive patient care.
Technical Explanation
The authors propose a novel "subvolume merging" technique for enhancing cross-modality synthesis, specifically for the task of converting MRI scans to their corresponding CT scans.
The key components of their approach are as follows:
- Subvolume Extraction: The input MRI scan is divided into smaller 3D subvolumes, which are then processed independently by the model.
- Swin Transformer: A Swin Transformer model is used to predict the corresponding CT subvolumes for each MRI subvolume. The Swin Transformer is a type of deep learning architecture that has shown impressive performance on various computer vision tasks.
- Subvolume Merging: The predicted CT subvolumes are then merged back together to reconstruct the full CT scan. This merging process helps to preserve the spatial relationships and anatomical details between the different regions of the image.
The authors evaluate their approach on several publicly available datasets and compare it to prior state-of-the-art methods for MRI-to-CT conversion. They demonstrate that their subvolume merging technique leads to significant improvements in various evaluation metrics, such as peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM).
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for enhancing cross-modality synthesis, specifically for the task of converting MRI scans to their corresponding CT scans.
One potential limitation of the proposed method is that it may not perform as well on datasets with significant anatomical variability, as the subvolume-based approach may struggle to capture larger-scale contextual information. Additionally, the computational complexity of the subvolume extraction and merging steps may be a concern for real-time or resource-constrained applications.
Further research could explore ways to address these limitations, such as by incorporating global context modeling or developing more efficient subvolume processing techniques. Additionally, investigating the transferability of the trained model to different anatomical regions or patient populations could help assess the broader applicability of the approach.
Conclusion
The paper presents a novel "subvolume merging" technique for enhancing cross-modality synthesis, specifically for the task of converting MRI scans to their corresponding CT scans. By leveraging a Swin Transformer model and a subvolume-based approach, the authors demonstrate improved performance over prior state-of-the-art methods.
This work represents an important step forward in the field of medical image synthesis, as it brings us closer to the goal of seamlessly integrating information from different imaging modalities for more comprehensive patient care. The proposed method may find applications in a variety of clinical scenarios, such as treatment planning, disease diagnosis, and longitudinal monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Cross-Modality Synthesis: Subvolume Merging for MRI-to-CT Conversion
Fuxin Fan, Jingna Qiu, Yixing Huang, Andreas Maier
Providing more precise tissue attenuation information, synthetic computed tomography (sCT) generated from magnetic resonance imaging (MRI) contributes to improved radiation therapy treatment planning. In our study, we employ the advanced SwinUNETR framework for synthesizing CT from MRI images. Additionally, we introduce a three-dimensional subvolume merging technique in the prediction process. By selecting an optimal overlap percentage for adjacent subvolumes, stitching artifacts are effectively mitigated, leading to a decrease in the mean absolute error (MAE) between sCT and the labels from 52.65 HU to 47.75 HU. Furthermore, implementing a weight function with a gamma value of 0.9 results in the lowest MAE within the same overlap area. By setting the overlap percentage between 50% and 70%, we achieve a balance between image quality and computational efficiency.
Read more9/11/2024

0
Leveraging Multimodal CycleGAN for the Generation of Anatomically Accurate Synthetic CT Scans from MRIs
Leonardo Crespi, Samuele Camnasio, Damiano Dei, Nicola Lambri, Pietro Mancosu, Marta Scorsetti, Daniele Loiacono
In many clinical settings, the use of both Computed Tomography (CT) and Magnetic Resonance (MRI) is necessary to pursue a thorough understanding of the patient's anatomy and to plan a suitable therapeutical strategy; this is often the case in MRI-based radiotherapy, where CT is always necessary to prepare the dose delivery, as it provides the essential information about the radiation absorption properties of the tissues. Sometimes, MRI is preferred to contour the target volumes. However, this approach is often not the most efficient, as it is more expensive, time-consuming and, most importantly, stressful for the patients. To overcome this issue, in this work, we analyse the capabilities of different configurations of Deep Learning models to generate synthetic CT scans from MRI, leveraging the power of Generative Adversarial Networks (GANs) and, in particular, the CycleGAN architecture, capable of working in an unsupervised manner and without paired images, which were not available. Several CycleGAN models were trained unsupervised to generate CT scans from different MRI modalities with and without contrast agents. To overcome the problem of not having a ground truth, distribution-based metrics were used to assess the model's performance quantitatively, together with a qualitative evaluation where physicians were asked to differentiate between real and synthetic images to understand how realistic the generated images were. The results show how, depending on the input modalities, the models can have very different performances; however, models with the best quantitative results, according to the distribution-based metrics used, can generate very difficult images to distinguish from the real ones, even for physicians, demonstrating the approach's potential.
Read more7/16/2024

0
Improve Cross-Modality Segmentation by Treating MRI Images as Inverted CT Scans
Hartmut Hantze, Lina Xu, Leonhard Donle, Felix J. Dorfner, Alessa Hering, Lisa C. Adams, Keno K. Bressem
Computed tomography (CT) segmentation models frequently include classes that are not currently supported by magnetic resonance imaging (MRI) segmentation models. In this study, we show that a simple image inversion technique can significantly improve the segmentation quality of CT segmentation models on MRI data, by using the TotalSegmentator model, applied to T1-weighted MRI images, as example. Image inversion is straightforward to implement and does not require dedicated graphics processing units (GPUs), thus providing a quick alternative to complex deep modality-transfer models for generating segmentation masks for MRI data.
Read more5/8/2024

0
Deep learning-based brain segmentation model performance validation with clinical radiotherapy CT
Selena Huisman, Matteo Maspero, Marielle Philippens, Joost Verhoeff, Szabolcs David
Manual segmentation of medical images is labor intensive and especially challenging for images with poor contrast or resolution. The presence of disease exacerbates this further, increasing the need for an automated solution. To this extent, SynthSeg is a robust deep learning model designed for automatic brain segmentation across various contrasts and resolutions. This study validates the SynthSeg robust brain segmentation model on computed tomography (CT), using a multi-center dataset. An open access dataset of 260 paired CT and magnetic resonance imaging (MRI) from radiotherapy patients treated in 5 centers was collected. Brain segmentations from CT and MRI were obtained with SynthSeg model, a component of the Freesurfer imaging suite. These segmentations were compared and evaluated using Dice scores and Hausdorff 95 distance (HD95), treating MRI-based segmentations as the ground truth. Brain regions that failed to meet performance criteria were excluded based on automated quality control (QC) scores. Dice scores indicate a median overlap of 0.76 (IQR: 0.65-0.83). The median HD95 is 2.95 mm (IQR: 1.73-5.39). QC score based thresholding improves median dice by 0.1 and median HD95 by 0.05mm. Morphological differences related to sex and age, as detected by MRI, were also replicated with CT, with an approximate 17% difference between the CT and MRI results for sex and 10% difference between the results for age. SynthSeg can be utilized for CT-based automatic brain segmentation, but only in applications where precision is not essential. CT performance is lower than MRI based on the integrated QC scores, but low-quality segmentations can be excluded with QC-based thresholding. Additionally, performing CT-based neuroanatomical studies is encouraged, as the results show correlations in sex- and age-based analyses similar to those found with MRI.
Read more6/26/2024