Enhancing Customer Churn Prediction in Telecommunications: An Adaptive Ensemble Learning Approach

0
🔮
Sign in to get full access
Overview
- Customer churn, when customers discontinue using a company's services, is a significant challenge for the telecommunications industry.
- This research paper proposes a novel adaptive ensemble learning framework for highly accurate customer churn prediction.
- The framework combines multiple machine learning models, including XGBoost, LightGBM, LSTM, Multi-Layer Perceptron (MLP), and Support Vector Machine (SVM).
- The models are integrated using a stacking ensemble method and further enhanced by generating meta-features from the base model predictions.
- Rigorous data preprocessing and feature engineering optimize the model performance.
- The framework is evaluated on three publicly available telecom churn datasets, demonstrating substantial accuracy improvements over existing techniques.
- The research achieves a remarkable 99.28% accuracy, a significant advancement in churn prediction.
- The findings have implications for developing proactive customer retention strategies in the telecommunications industry.
Plain English Explanation
Customers discontinuing their services with a company, known as customer churn, is a major problem for the telecommunications industry. This research paper introduces a new machine learning system that can very accurately predict when customers are likely to stop using a company's services.
The system works by combining the predictions of several different machine learning models, including some advanced techniques like XGBoost and LightGBM. These models are carefully integrated using a technique called stacking, which allows the system to make even more accurate predictions.
The researchers also put a lot of work into preprocessing the data and engineering new features that help the models perform better. When they tested the system on real-world telecom customer data, it achieved an accuracy of over 99%, which is a major improvement over existing methods.
This research could help telecom companies develop better strategies for retaining their customers and preventing them from leaving. By accurately predicting which customers are at risk of churning, companies can proactively reach out and address their needs before they decide to switch to a competitor.
Technical Explanation
The proposed framework integrates multiple base models, including XGBoost, LightGBM, LSTM, Multi-Layer Perceptron (MLP), and Support Vector Machine (SVM). These models are strategically combined using a stacking ensemble method, which involves training a meta-model to learn from the predictions of the base models.
The framework further enhances the ensemble by generating meta-features from the base model predictions. This allows the meta-model to learn more complex patterns in the data by considering the outputs of the individual models.
A rigorous data preprocessing pipeline is implemented, including handling missing values, encoding categorical features, and scaling numeric features. The feature engineering approach involves creating new attributes from the original dataset, such as recency, frequency, and monetary value (RFM) features, to capture customer behavior patterns.
The proposed framework is evaluated on three publicly available telecom churn datasets. The results demonstrate substantial accuracy improvements over state-of-the-art techniques, achieving a remarkable 99.28% accuracy on the best-performing dataset.
Critical Analysis
The researchers acknowledge that while the proposed framework achieves exceptional accuracy, there may be limitations in its real-world applicability. The paper does not provide detailed information about the size and complexity of the datasets used, which could impact the scalability and generalizability of the approach.
Additionally, the paper does not discuss the computational resources required to train and deploy the ensemble model, which could be a significant consideration for practical implementation in a production environment.
Further research could explore the interpretability of the ensemble model, as understanding the key factors driving the churn predictions could be valuable for informing customer retention strategies.
Conclusion
This research presents a novel adaptive ensemble learning framework for highly accurate customer churn prediction in the telecommunications industry. By combining multiple advanced machine learning models and leveraging meta-feature engineering, the framework demonstrates substantial improvements in predictive accuracy compared to existing techniques.
The implications of this research could be significant for telecom companies, as the ability to accurately predict which customers are at risk of churning can enable the development of proactive customer retention strategies. This could lead to increased customer loyalty, reduced customer acquisition costs, and ultimately, improved profitability for the industry.
While the framework shows promising results, further research is needed to address potential scalability and interpretability concerns. Nonetheless, this work represents an important step forward in the application of advanced machine learning techniques to address a critical challenge facing the telecommunications sector.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Enhancing Customer Churn Prediction in Telecommunications: An Adaptive Ensemble Learning Approach
Mohammed Affan Shaikhsurab, Pramod Magadum
Customer churn, the discontinuation of services by existing customers, poses a significant challenge to the telecommunications industry. This paper proposes a novel adaptive ensemble learning framework for highly accurate customer churn prediction. The framework integrates multiple base models, including XGBoost, LightGBM, LSTM, a Multi-Layer Perceptron (MLP) neural network, and Support Vector Machine (SVM). These models are strategically combined using a stacking ensemble method, further enhanced by meta-feature generation from base model predictions. A rigorous data preprocessing pipeline, coupled with a multi-faceted feature engineering approach, optimizes model performance. The framework is evaluated on three publicly available telecom churn datasets, demonstrating substantial accuracy improvements over state-of-the-art techniques. The research achieves a remarkable 99.28% accuracy, signifying a major advancement in churn prediction.The implications of this research for developing proactive customer retention strategies withinthe telecommunications industry are discussed.
Read more8/30/2024
0
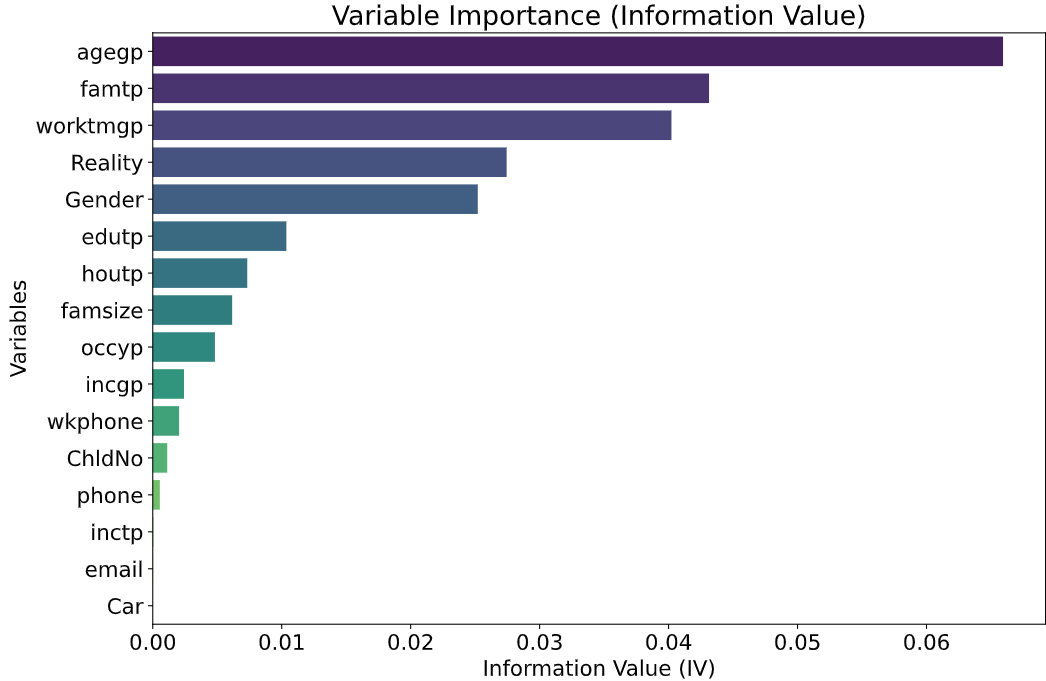
Advanced User Credit Risk Prediction Model using LightGBM, XGBoost and Tabnet with SMOTEENN
Chang Yu, Yixin Jin, Qianwen Xing, Ye Zhang, Shaobo Guo, Shuchen Meng
Bank credit risk is a significant challenge in modern financial transactions, and the ability to identify qualified credit card holders among a large number of applicants is crucial for the profitability of a bank'sbank's credit card business. In the past, screening applicants'applicants' conditions often required a significant amount of manual labor, which was time-consuming and labor-intensive. Although the accuracy and reliability of previously used ML models have been continuously improving, the pursuit of more reliable and powerful AI intelligent models is undoubtedly the unremitting pursuit by major banks in the financial industry. In this study, we used a dataset of over 40,000 records provided by a commercial bank as the research object. We compared various dimensionality reduction techniques such as PCA and T-SNE for preprocessing high-dimensional datasets and performed in-depth adaptation and tuning of distributed models such as LightGBM and XGBoost, as well as deep models like Tabnet. After a series of research and processing, we obtained excellent research results by combining SMOTEENN with these techniques. The experiments demonstrated that LightGBM combined with PCA and SMOTEENN techniques can assist banks in accurately predicting potential high-quality customers, showing relatively outstanding performance compared to other models.
Read more8/9/2024
0
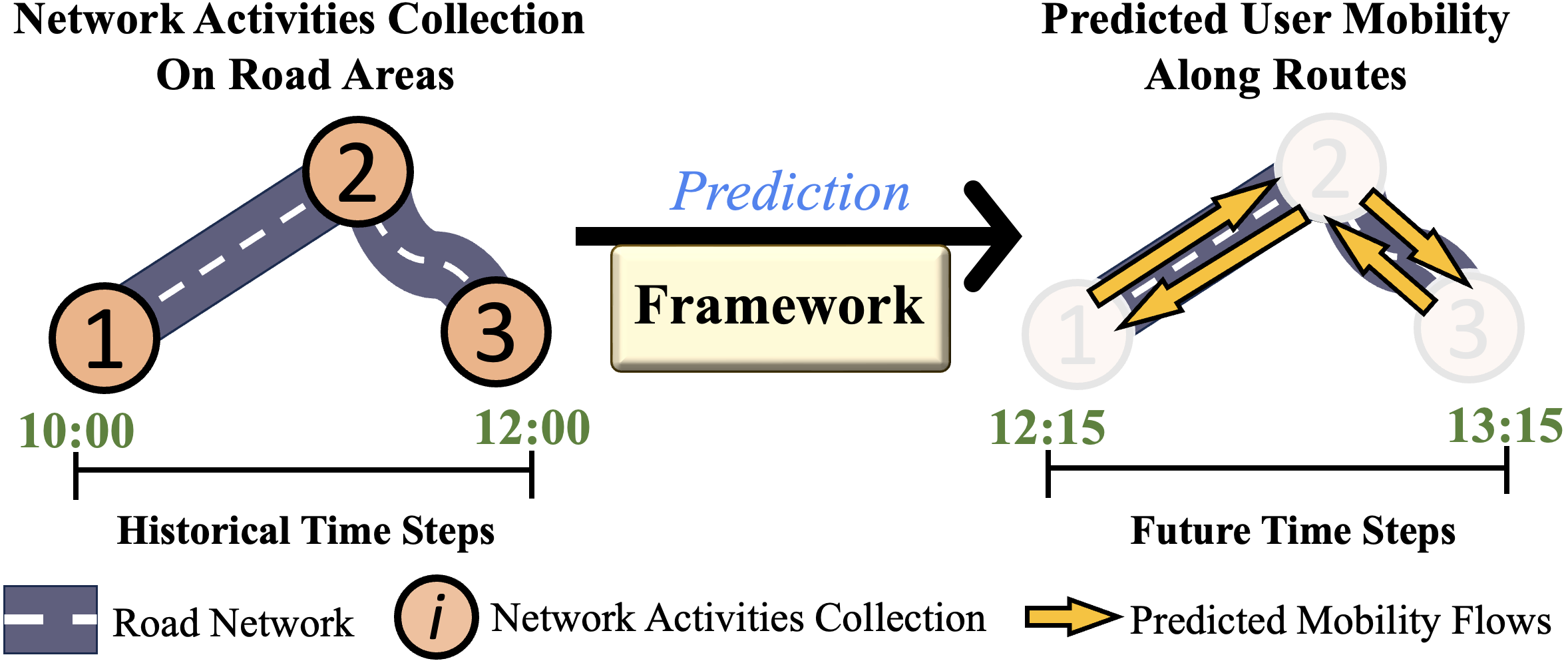
Enhancing Sustainable Urban Mobility Prediction with Telecom Data: A Spatio-Temporal Framework Approach
ChungYi Lin, Shen-Lung Tung, Hung-Ting Su, Winston H. Hsu
Traditional traffic prediction, limited by the scope of sensor data, falls short in comprehensive traffic management. Mobile networks offer a promising alternative using network activity counts, but these lack crucial directionality. Thus, we present the TeltoMob dataset, featuring undirected telecom counts and corresponding directional flows, to predict directional mobility flows on roadways. To address this, we propose a two-stage spatio-temporal graph neural network (STGNN) framework. The first stage uses a pre-trained STGNN to process telecom data, while the second stage integrates directional and geographic insights for accurate prediction. Our experiments demonstrate the framework's compatibility with various STGNN models and confirm its effectiveness. We also show how to incorporate the framework into real-world transportation systems, enhancing sustainable urban mobility.
Read more5/29/2024

0
Ensemble Method for System Failure Detection Using Large-Scale Telemetry Data
Priyanka Mudgal, Rita H. Wouhaybi
The growing reliance on computer systems, particularly personal computers (PCs), necessitates heightened reliability to uphold user satisfaction. This research paper presents an in-depth analysis of extensive system telemetry data, proposing an ensemble methodology for detecting system failures. Our approach entails scrutinizing various parameters of system metrics, encompassing CPU utilization, memory utilization, disk activity, CPU temperature, and pertinent system metadata such as system age, usage patterns, core count, and processor type. The proposed ensemble technique integrates a diverse set of algorithms, including Long Short-Term Memory (LSTM) networks, isolation forests, one-class support vector machines (OCSVM), and local outlier factors (LOF), to effectively discern system failures. Specifically, the LSTM network with other machine learning techniques is trained on Intel Computing Improvement Program (ICIP) telemetry software data to distinguish between normal and failed system patterns. Experimental evaluations demonstrate the remarkable efficacy of our models, achieving a notable detection rate in identifying system failures. Our research contributes to advancing the field of system reliability and offers practical insights for enhancing user experience in computing environments.
Read more7/2/2024