Ensemble Method for System Failure Detection Using Large-Scale Telemetry Data

0

Sign in to get full access
Overview
- This paper presents an ensemble method for detecting system failures using large-scale telemetry data.
- The approach combines multiple machine learning models to improve the accuracy and robustness of failure prediction.
- The researchers tested their method on real-world data from a large-scale cloud computing system and found it outperformed individual models.
Plain English Explanation
The paper describes a way to predict when computer systems might fail using a combination of different machine learning models. Large companies that run lots of computers, like cloud providers, collect a huge amount of data about how their systems are performing. This data, called telemetry, can provide clues about when a system might be about to fail.
The researchers developed an "ensemble" approach, which means they used multiple machine learning models together instead of just one. This helps make the predictions more accurate and reliable. They tested their method on real data from a large cloud computing system and found it worked better than using a single model alone.
The key idea is that by combining the strengths of different machine learning techniques, you can get better results for predicting system failures. This is important because catching problems early can help companies avoid costly downtime or data loss. The significance of latent data divergence for predicting system degradation is another related area of research in this space.
Technical Explanation
The paper presents an ensemble method for detecting system failures using large-scale telemetry data. The approach combines multiple machine learning models, including deep learning and anomaly detection techniques, to improve the accuracy and robustness of failure prediction.
The ensemble model first extracts features from the telemetry data, then uses several different classifiers to make predictions about potential failures. These include a long short-term memory (LSTM) network, a one-class support vector machine (OC-SVM), and a k-nearest neighbors (KNN) algorithm. The outputs of these individual models are then combined using a weighted voting scheme to produce the final prediction.
The researchers evaluated their approach using real-world data from a large-scale cloud computing system. They found that the ensemble method outperformed individual models, achieving higher accuracy and lower false positive rates in detecting system failures. The self-supervised learning framework for dual ensemble is another related technique that could complement this approach.
Critical Analysis
The paper provides a thorough evaluation of the ensemble method and demonstrates its effectiveness on real-world data. However, the authors acknowledge several limitations and areas for future research.
One potential issue is the reliance on labeled failure data, which may not always be available or accurate. The researchers suggest exploring unsupervised anomaly detection techniques to address this challenge. Additionally, the ensemble model may not be able to capture all the complex dependencies and interactions within the telemetry data, and further work is needed to improve the feature engineering and model selection processes.
Another concern is the scalability of the approach, as ensemble methods can be computationally intensive, especially when dealing with large-scale telemetry data. The researchers mention the need to investigate more efficient ensemble architectures and optimization techniques to make the method practical for real-world deployment.
Overall, the paper presents a promising approach for improving system failure detection, but further research is necessary to address the identified limitations and make the solution more robust and scalable for large-scale deployments. Lightweight multi-system multivariate interconnection divergence discovery is another area that could complement this work.
Conclusion
This paper introduces an ensemble method for detecting system failures using large-scale telemetry data. By combining multiple machine learning models, the approach can improve the accuracy and robustness of failure prediction compared to individual models. The researchers demonstrated the effectiveness of their method on real-world data from a cloud computing system, and they discussed potential avenues for future research to address the identified limitations.
The significance of this work lies in its practical applications for improving the reliability and availability of large-scale computing systems. By catching potential failures early, companies can reduce the risk of costly downtime and data loss, leading to better service for their customers. The techniques presented in this paper could have broader implications for other domains that rely on complex, high-dimensional sensor data, such as industrial automation, infrastructure monitoring, and predictive maintenance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ensemble Method for System Failure Detection Using Large-Scale Telemetry Data
Priyanka Mudgal, Rita H. Wouhaybi
The growing reliance on computer systems, particularly personal computers (PCs), necessitates heightened reliability to uphold user satisfaction. This research paper presents an in-depth analysis of extensive system telemetry data, proposing an ensemble methodology for detecting system failures. Our approach entails scrutinizing various parameters of system metrics, encompassing CPU utilization, memory utilization, disk activity, CPU temperature, and pertinent system metadata such as system age, usage patterns, core count, and processor type. The proposed ensemble technique integrates a diverse set of algorithms, including Long Short-Term Memory (LSTM) networks, isolation forests, one-class support vector machines (OCSVM), and local outlier factors (LOF), to effectively discern system failures. Specifically, the LSTM network with other machine learning techniques is trained on Intel Computing Improvement Program (ICIP) telemetry software data to distinguish between normal and failed system patterns. Experimental evaluations demonstrate the remarkable efficacy of our models, achieving a notable detection rate in identifying system failures. Our research contributes to advancing the field of system reliability and offers practical insights for enhancing user experience in computing environments.
Read more7/2/2024
🏅
0
Root Cause Analysis Of Productivity Losses In Manufacturing Systems Utilizing Ensemble Machine Learning
Jonas Gram, Brandon K. Sai, Thomas Bauernhansl
In today's rapidly evolving landscape of automation and manufacturing systems, the efficient resolution of productivity losses is paramount. This study introduces a data-driven ensemble approach, utilizing the cyclic multivariate time series data from binary sensors and signals from Programmable Logic Controllers (PLCs) within these systems. The objective is to automatically analyze productivity losses per cycle and pinpoint their root causes by assigning the loss to a system element. The ensemble approach introduced in this publication integrates various methods, including information theory and machine learning behavior models, to provide a robust analysis for each production cycle. To expedite the resolution of productivity losses and ensure short response times, stream processing becomes a necessity. Addressing this, the approach is implemented as data-stream analysis and can be transferred to batch processing, seamlessly integrating into existing systems without the need for extensive historical data analysis. This method has two positive effects. Firstly, the result of the analysis ensures that the period of lower productivity is reduced by identifying the likely root cause of the productivity loss. Secondly, these results are more reliable due to the ensemble approach and therefore avoid dependency on technical experts. The approach is validated using a semi-automated welding manufacturing system, an injection molding automation system, and a synthetically generated test PLC dataset. The results demonstrate the method's efficacy in offering a data-driven understanding of process behavior and mark an advancement in autonomous manufacturing system analysis.
Read more8/1/2024
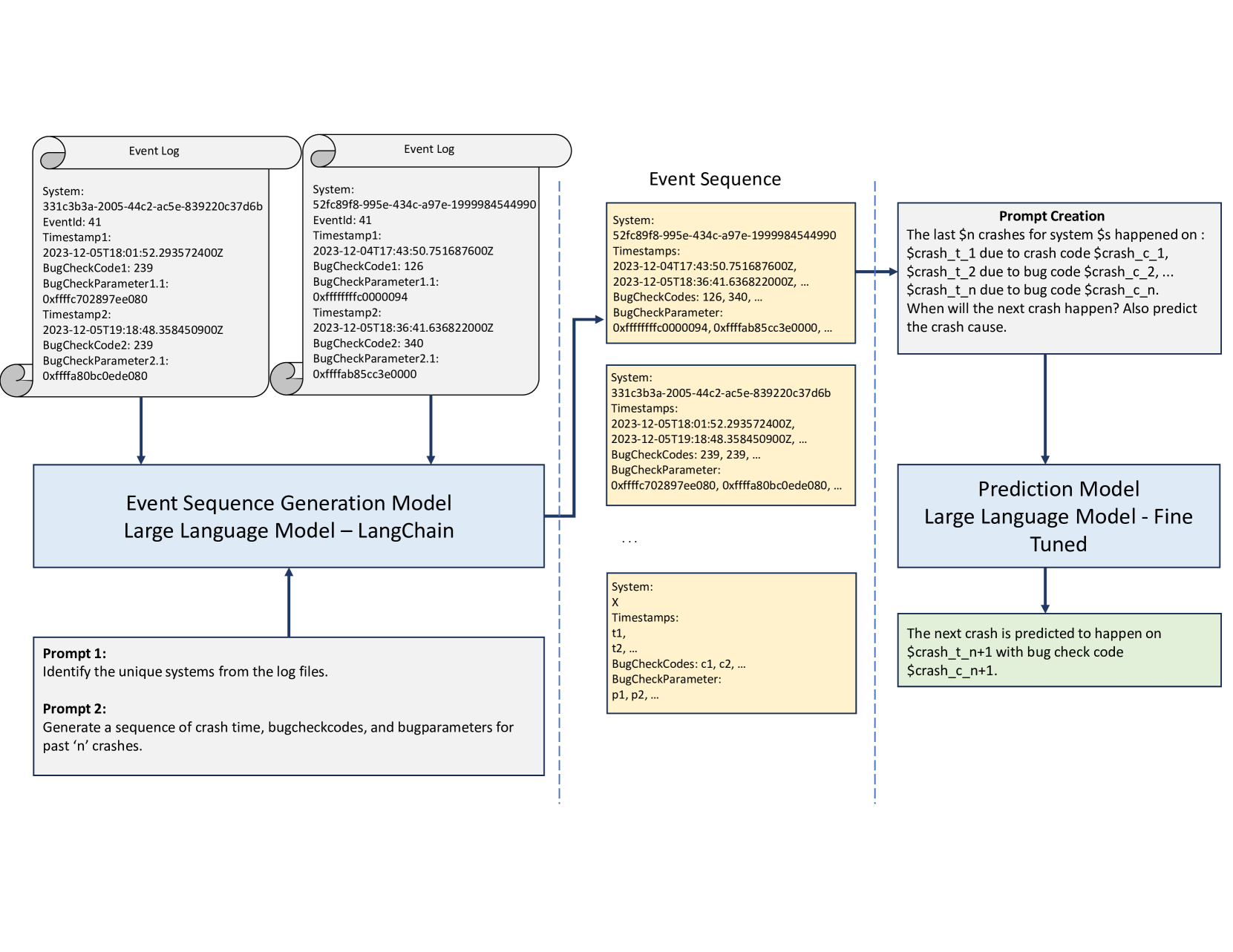
0
CrashEventLLM: Predicting System Crashes with Large Language Models
Priyanka Mudgal, Bijan Arbab, Swaathi Sampath Kumar
As the dependence on computer systems expands across various domains, focusing on personal, industrial, and large-scale applications, there arises a compelling need to enhance their reliability to sustain business operations seamlessly and ensure optimal user satisfaction. System logs generated by these devices serve as valuable repositories of historical trends and past failures. The use of machine learning techniques for failure prediction has become commonplace, enabling the extraction of insights from past data to anticipate future behavior patterns. Recently, large language models have demonstrated remarkable capabilities in tasks including summarization, reasoning, and event prediction. Therefore, in this paper, we endeavor to investigate the potential of large language models in predicting system failures, leveraging insights learned from past failure behavior to inform reasoning and decision-making processes effectively. Our approach involves leveraging data from the Intel Computing Improvement Program (ICIP) system crash logs to identify significant events and develop CrashEventLLM. This model, built upon a large language model framework, serves as our foundation for crash event prediction. Specifically, our model utilizes historical data to forecast future crash events, informed by expert annotations. Additionally, it goes beyond mere prediction, offering insights into potential causes for each crash event. This work provides the preliminary insights into prompt-based large language models for the log-based event prediction task.
Read more7/30/2024

0
Anomaly Detection Within Mission-Critical Call Processing
Sean Doris, Iosif Salem, Stefan Schmid
With increasingly larger and more complex telecommunication networks, there is a need for improved monitoring and reliability. Requirements increase further when working with mission-critical systems requiring stable operations to meet precise design and client requirements while maintaining high availability. This paper proposes a novel methodology for developing a machine learning model that can assist in maintaining availability (through anomaly detection) for client-server communications in mission-critical systems. To that end, we validate our methodology for training models based on data classified according to client performance. The proposed methodology evaluates the use of machine learning to perform anomaly detection of a single virtualized server loaded with simulated network traffic (using SIPp) with media calls. The collected data for the models are classified based on the round trip time performance experienced on the client side to determine if the trained models can detect anomalous client side performance only using key performance indicators available on the server. We compared the performance of seven different machine learning models by testing different trained and untrained test stressor scenarios. In the comparison, five models achieved an F1-score above 0.99 for the trained test scenarios. Random Forest was the only model able to attain an F1-score above 0.9 for all untrained test scenarios with the lowest being 0.980. The results suggest that it is possible to generate accurate anomaly detection to evaluate degraded client-side performance.
Read more8/28/2024