Enhancing Diagnostic Reliability of Foundation Model with Uncertainty Estimation in OCT Images

0
Sign in to get full access
Overview
This paper focuses on enhancing the diagnostic reliability of a foundation model for analyzing optical coherence tomography (OCT) images of the eye. The key ideas include:
- Developing a model that can not only make predictions but also provide uncertainty estimates to indicate the confidence in those predictions.
- Leveraging large datasets to train a "foundation model" that can be fine-tuned for specific eye disease tasks.
- Incorporating uncertainty estimation to improve the model's reliability and identify areas where it may be less confident in its analysis.
Plain English Explanation
Doctors often use a medical imaging technique called optical coherence tomography (OCT) to examine the different layers of the eye. This can help them detect and diagnose eye diseases like macular degeneration or glaucoma. However, interpreting these OCT images can be challenging, even for experienced doctors.
The researchers in this paper wanted to create a powerful AI model that could analyze OCT images and provide reliable diagnoses. They started by training a "foundation model" - a large, general-purpose AI model - on a huge dataset of OCT images. This allowed the model to develop a deep understanding of the different structures and patterns in the eye.
But the researchers didn't just want the model to make predictions - they also wanted it to estimate how confident it was in those predictions. So they added a special component that could calculate the model's level of uncertainty for each diagnosis it made. This is like the model saying "I'm 90% sure this is macular degeneration, but there's a 10% chance I could be wrong."
By incorporating this uncertainty estimation, the model becomes more reliable and trustworthy. Doctors can use the model's predictions, but also consider the uncertainty levels to get a better sense of how much they can rely on the results. This helps improve the overall accuracy and usefulness of the AI system for diagnosing eye diseases from OCT images.
Technical Explanation
The researchers developed a foundation model architecture based on the Masked Image Modelling for Retinal OCT Understanding paper. This allowed them to leverage large datasets to train a generalist model that can be fine-tuned for specific eye disease tasks, similar to the approach in the Confidence-Aware Multi-modality Learning for Eye Disease work.
Crucially, the researchers also incorporated an uncertainty estimation component, drawing inspiration from techniques like Uncertainty Quantification for Birds-Eye View Semantic Segmentation. This allows the model to not only make predictions, but also provide a measure of how confident it is in those predictions.
The foundation model was trained on a large dataset of OCT images, building on the insights from Training High-Performance Retinal Foundation Model with Half the Data. This provided the model with a robust understanding of the visual patterns and structures in the eye, which could then be fine-tuned for specific eye disease tasks.
Critical Analysis
The paper presents a compelling approach to enhancing the diagnostic reliability of AI systems for analyzing OCT images. The incorporation of uncertainty estimation is a particularly valuable contribution, as it allows doctors to better understand the limitations and potential errors of the model's predictions.
However, the paper does not address potential biases or fairness issues that could arise from the training data or fine-tuning process. It would be important to evaluate the model's performance across diverse patient populations to ensure it does not exhibit any problematic biases.
Additionally, the paper does not delve into the potential challenges of deploying such a system in real-world clinical settings. Factors like interpretability, explainability, and seamless integration with existing workflows would need to be carefully considered to ensure successful adoption by healthcare providers.
Conclusion
This research represents an important step forward in developing AI-powered diagnostic tools for ophthalmology. By combining a powerful foundation model with uncertainty estimation, the proposed approach can provide doctors with more reliable and trustworthy analyses of OCT images, ultimately leading to improved patient outcomes.
As the field of multimodal generalist foundation models for ophthalmic imaging continues to evolve, this work highlights the value of incorporating uncertainty estimation to enhance the diagnostic reliability of these systems. Further research is needed to address the potential challenges and limitations, but the overall direction of this work is highly promising for the future of AI-assisted eye care.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Diagnostic Reliability of Foundation Model with Uncertainty Estimation in OCT Images
Yuanyuan Peng, Aidi Lin, Meng Wang, Tian Lin, Ke Zou, Yinglin Cheng, Tingkun Shi, Xulong Liao, Lixia Feng, Zhen Liang, Xinjian Chen, Huazhu Fu, Haoyu Chen
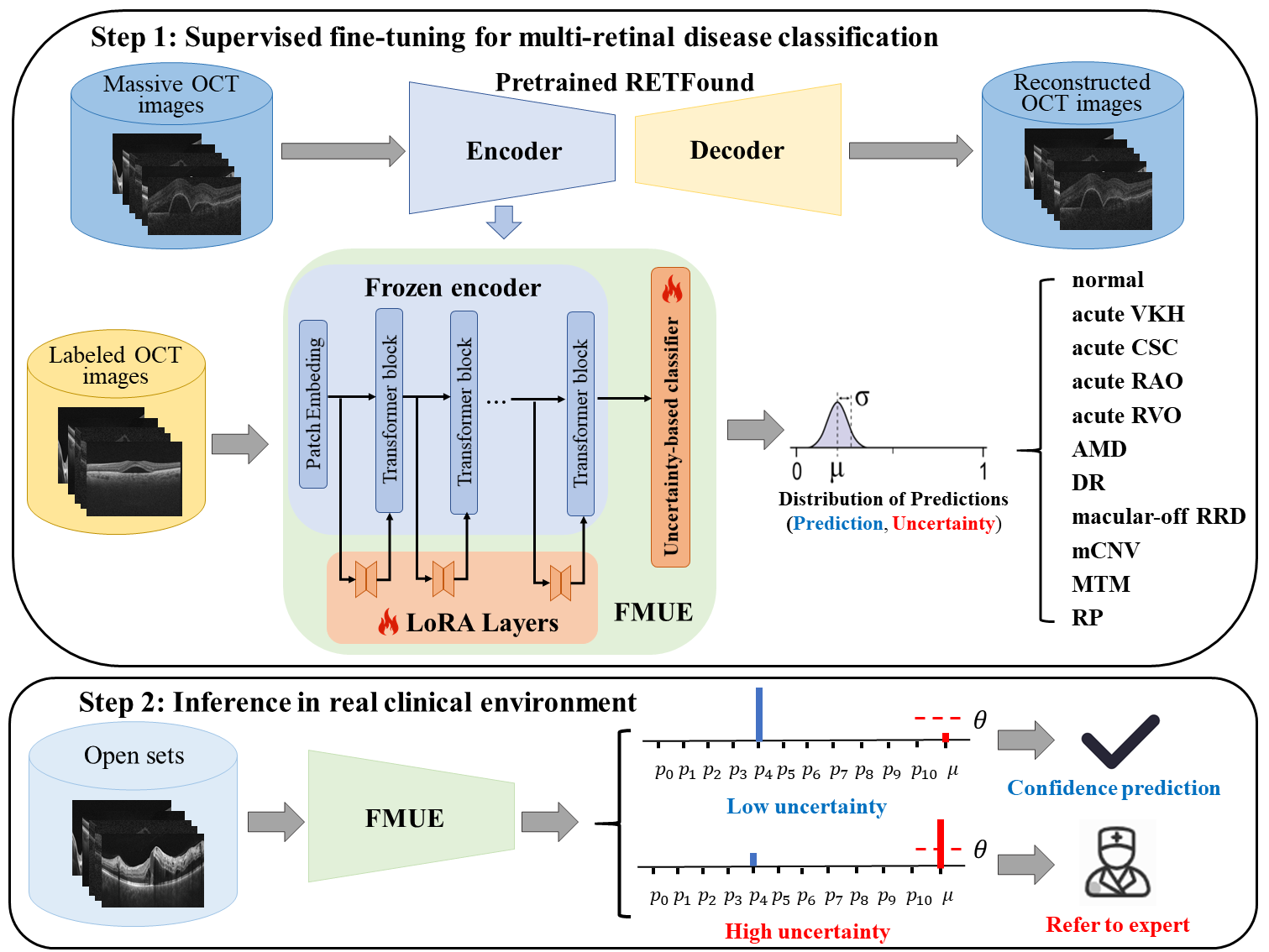
Inability to express the confidence level and detect unseen classes has limited the clinical implementation of artificial intelligence in the real-world. We developed a foundation model with uncertainty estimation (FMUE) to detect 11 retinal conditions on optical coherence tomography (OCT). In the internal test set, FMUE achieved a higher F1 score of 96.76% than two state-of-the-art algorithms, RETFound and UIOS, and got further improvement with thresholding strategy to 98.44%. In the external test sets obtained from other OCT devices, FMUE achieved an accuracy of 88.75% and 92.73% before and after thresholding. Our model is superior to two ophthalmologists with a higher F1 score (95.17% vs. 61.93% &71.72%). Besides, our model correctly predicts high uncertainty scores for samples with ambiguous features, of non-target-category diseases, or with low-quality to prompt manual checks and prevent misdiagnosis. FMUE provides a trustworthy method for automatic retinal anomalies detection in the real-world clinical open set environment.
Read more6/26/2024
📈
0
OCTCube: A 3D foundation model for optical coherence tomography that improves cross-dataset, cross-disease, cross-device and cross-modality analysis
Zixuan Liu, Hanwen Xu, Addie Woicik, Linda G. Shapiro, Marian Blazes, Yue Wu, Cecilia S. Lee, Aaron Y. Lee, Sheng Wang
Optical coherence tomography (OCT) has become critical for diagnosing retinal diseases as it enables 3D images of the retina and optic nerve. OCT acquisition is fast, non-invasive, affordable, and scalable. Due to its broad applicability, massive numbers of OCT images have been accumulated in routine exams, making it possible to train large-scale foundation models that can generalize to various diagnostic tasks using OCT images. Nevertheless, existing foundation models for OCT only consider 2D image slices, overlooking the rich 3D structure. Here, we present OCTCube, a 3D foundation model pre-trained on 26,605 3D OCT volumes encompassing 1.62 million 2D OCT images. OCTCube is developed based on 3D masked autoencoders and exploits FlashAttention to reduce the larger GPU memory usage caused by modeling 3D volumes. OCTCube outperforms 2D models when predicting 8 retinal diseases in both inductive and cross-dataset settings, indicating that utilizing the 3D structure in the model instead of 2D data results in significant improvement. OCTCube further shows superior performance on cross-device prediction and when predicting systemic diseases, such as diabetes and hypertension, further demonstrating its strong generalizability. Finally, we propose a contrastive-self-supervised-learning-based OCT-IR pre-training framework (COIP) for cross-modality analysis on OCT and infrared retinal (IR) images, where the OCT volumes are embedded using OCTCube. We demonstrate that COIP enables accurate alignment between OCT and IR en face images. Collectively, OCTCube, a 3D OCT foundation model, demonstrates significantly better performance against 2D models on 27 out of 29 tasks and comparable performance on the other two tasks, paving the way for AI-based retinal disease diagnosis.
Read more8/22/2024

0
A Disease-Specific Foundation Model Using Over 100K Fundus Images: Release and Validation for Abnormality and Multi-Disease Classification on Downstream Tasks
Boa Jang, Youngbin Ahn, Eun Kyung Choe, Chang Ki Yoon, Hyuk Jin Choi, Young-Gon Kim
Artificial intelligence applied to retinal images offers significant potential for recognizing signs and symptoms of retinal conditions and expediting the diagnosis of eye diseases and systemic disorders. However, developing generalized artificial intelligence models for medical data often requires a large number of labeled images representing various disease signs, and most models are typically task-specific, focusing on major retinal diseases. In this study, we developed a Fundus-Specific Pretrained Model (Image+Fundus), a supervised artificial intelligence model trained to detect abnormalities in fundus images. A total of 57,803 images were used to develop this pretrained model, which achieved superior performance across various downstream tasks, indicating that our proposed model outperforms other general methods. Our Image+Fundus model offers a generalized approach to improve model performance while reducing the number of labeled datasets required. Additionally, it provides more disease-specific insights into fundus images, with visualizations generated by our model. These disease-specific foundation models are invaluable in enhancing the performance and efficiency of deep learning models in the field of fundus imaging.
Read more8/19/2024

0
UrFound: Towards Universal Retinal Foundation Models via Knowledge-Guided Masked Modeling
Kai Yu, Yang Zhou, Yang Bai, Zhi Da Soh, Xinxing Xu, Rick Siow Mong Goh, Ching-Yu Cheng, Yong Liu
Retinal foundation models aim to learn generalizable representations from diverse retinal images, facilitating label-efficient model adaptation across various ophthalmic tasks. Despite their success, current retinal foundation models are generally restricted to a single imaging modality, such as Color Fundus Photography (CFP) or Optical Coherence Tomography (OCT), limiting their versatility. Moreover, these models may struggle to fully leverage expert annotations and overlook the valuable domain knowledge essential for domain-specific representation learning. To overcome these limitations, we introduce UrFound, a retinal foundation model designed to learn universal representations from both multimodal retinal images and domain knowledge. UrFound is equipped with a modality-agnostic image encoder and accepts either CFP or OCT images as inputs. To integrate domain knowledge into representation learning, we encode expert annotation in text supervision and propose a knowledge-guided masked modeling strategy for model pre-training. It involves reconstructing randomly masked patches of retinal images while predicting masked text tokens conditioned on the corresponding retinal image. This approach aligns multimodal images and textual expert annotations within a unified latent space, facilitating generalizable and domain-specific representation learning. Experimental results demonstrate that UrFound exhibits strong generalization ability and data efficiency when adapting to various tasks in retinal image analysis. By training on ~180k retinal images, UrFound significantly outperforms the state-of-the-art retinal foundation model trained on up to 1.6 million unlabelled images across 8 public retinal datasets. Our code and data are available at https://github.com/yukkai/UrFound.
Read more8/13/2024