OCTCube: A 3D foundation model for optical coherence tomography that improves cross-dataset, cross-disease, cross-device and cross-modality analysis

0
📈
Sign in to get full access
Overview
- Optical coherence tomography (OCT) is a critical tool for diagnosing retinal diseases as it enables 3D imaging of the retina and optic nerve.
- OCT imaging is fast, non-invasive, affordable, and scalable, leading to the accumulation of massive amounts of OCT data.
- This data can be used to train large-scale foundation models for various OCT-based diagnostic tasks.
- Existing foundation models only consider 2D OCT image slices, overlooking the rich 3D structure of the data.
Plain English Explanation
The paper presents OCTCube, a 3D foundation model pre-trained on over 26,000 3D OCT volumes, which encompass 1.62 million 2D OCT images. OCTCube is designed to better capture the 3D structure of the retina and optic nerve, unlike previous models that only used 2D slices.
The researchers developed OCTCube using a 3D masked autoencoder architecture and FlashAttention to reduce the large GPU memory requirements of working with 3D data. They found that OCTCube outperforms 2D models when predicting 8 different retinal diseases, both on the same dataset and when tested on new datasets. This suggests that using the 3D structure of the data leads to significant improvements in diagnostic accuracy.
Additionally, OCTCube shows strong generalization capabilities, performing well on cross-device prediction and in predicting systemic diseases like diabetes and hypertension. The researchers also propose a new pre-training framework called COIP, which uses OCTCube to enable accurate alignment between OCT and infrared retinal images.
Technical Explanation
The paper introduces OCTCube, a 3D foundation model for OCT imaging. OCTCube is pre-trained on a large-scale dataset of 26,605 3D OCT volumes, which contain a total of 1.62 million 2D OCT images.
The model is developed using a 3D masked autoencoder architecture, which allows it to capture the rich 3D structure of the retina and optic nerve. To address the high GPU memory requirements of 3D data, the researchers employ FlashAttention, a technique that reduces the memory footprint of attention operations.
The researchers evaluate OCTCube on 8 retinal disease prediction tasks, comparing its performance to 2D models. They find that OCTCube outperforms the 2D models in both inductive and cross-dataset settings, demonstrating the benefits of leveraging the 3D structure of the data.
Additionally, OCTCube exhibits strong generalization capabilities, performing well on cross-device prediction and in predicting systemic diseases like diabetes and hypertension.
The researchers also propose a contrastive-self-supervised-learning-based OCT-IR pre-training framework (COIP), which uses OCTCube to enable accurate alignment between OCT and infrared retinal (IR) images.
Critical Analysis
The paper presents a compelling approach to leveraging the 3D structure of OCT data for improved disease diagnosis. By developing OCTCube, a 3D foundation model, the researchers demonstrate significant performance gains over 2D models, which is a notable advancement in the field.
However, the paper does not address potential limitations of the OCTCube model, such as its computational efficiency or the time required for pre-training on large 3D datasets. Additionally, the authors do not compare OCTCube to other 3D modeling approaches, which could provide further insights into the relative merits of the proposed architecture.
The COIP framework for cross-modality analysis between OCT and IR images is an interesting direction, but the paper does not provide a thorough evaluation of its performance or potential limitations.
Overall, the paper presents a significant advancement in the use of 3D OCT data for disease diagnosis, but further research is needed to fully understand the capabilities and limitations of the OCTCube model and the COIP framework.
Conclusion
The paper introduces OCTCube, a 3D foundation model for OCT imaging that outperforms 2D models in predicting a range of retinal diseases. By leveraging the rich 3D structure of the data, OCTCube demonstrates significant improvements in diagnostic accuracy, as well as strong generalization capabilities.
The researchers also propose the COIP framework, which uses OCTCube to enable accurate alignment between OCT and infrared retinal images, opening up new possibilities for cross-modality analysis.
Overall, the development of OCTCube represents a significant step forward in the use of 3D OCT data for improved disease diagnosis and could have far-reaching implications for the field of ophthalmology and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
OCTCube: A 3D foundation model for optical coherence tomography that improves cross-dataset, cross-disease, cross-device and cross-modality analysis
Zixuan Liu, Hanwen Xu, Addie Woicik, Linda G. Shapiro, Marian Blazes, Yue Wu, Cecilia S. Lee, Aaron Y. Lee, Sheng Wang
Optical coherence tomography (OCT) has become critical for diagnosing retinal diseases as it enables 3D images of the retina and optic nerve. OCT acquisition is fast, non-invasive, affordable, and scalable. Due to its broad applicability, massive numbers of OCT images have been accumulated in routine exams, making it possible to train large-scale foundation models that can generalize to various diagnostic tasks using OCT images. Nevertheless, existing foundation models for OCT only consider 2D image slices, overlooking the rich 3D structure. Here, we present OCTCube, a 3D foundation model pre-trained on 26,605 3D OCT volumes encompassing 1.62 million 2D OCT images. OCTCube is developed based on 3D masked autoencoders and exploits FlashAttention to reduce the larger GPU memory usage caused by modeling 3D volumes. OCTCube outperforms 2D models when predicting 8 retinal diseases in both inductive and cross-dataset settings, indicating that utilizing the 3D structure in the model instead of 2D data results in significant improvement. OCTCube further shows superior performance on cross-device prediction and when predicting systemic diseases, such as diabetes and hypertension, further demonstrating its strong generalizability. Finally, we propose a contrastive-self-supervised-learning-based OCT-IR pre-training framework (COIP) for cross-modality analysis on OCT and infrared retinal (IR) images, where the OCT volumes are embedded using OCTCube. We demonstrate that COIP enables accurate alignment between OCT and IR en face images. Collectively, OCTCube, a 3D OCT foundation model, demonstrates significantly better performance against 2D models on 27 out of 29 tasks and comparable performance on the other two tasks, paving the way for AI-based retinal disease diagnosis.
Read more8/22/2024

0
The Quest for Early Detection of Retinal Disease: 3D CycleGAN-based Translation of Optical Coherence Tomography into Confocal Microscopy
Xin Tian, Nantheera Anantrasirichai, Lindsay Nicholson, Alin Achim
Optical coherence tomography (OCT) and confocal microscopy are pivotal in retinal imaging, offering distinct advantages and limitations. In vivo OCT offers rapid, non-invasive imaging but can suffer from clarity issues and motion artifacts, while ex vivo confocal microscopy, providing high-resolution, cellular-detailed color images, is invasive and raises ethical concerns. To bridge the benefits of both modalities, we propose a novel framework based on unsupervised 3D CycleGAN for translating unpaired in vivo OCT to ex vivo confocal microscopy images. This marks the first attempt to exploit the inherent 3D information of OCT and translate it into the rich, detailed color domain of confocal microscopy. We also introduce a unique dataset, OCT2Confocal, comprising mouse OCT and confocal retinal images, facilitating the development of and establishing a benchmark for cross-modal image translation research. Our model has been evaluated both quantitatively and qualitatively, achieving Fr'echet Inception Distance (FID) scores of 0.766 and Kernel Inception Distance (KID) scores as low as 0.153, and leading subjective Mean Opinion Scores (MOS). Our model demonstrated superior image fidelity and quality with limited data over existing methods. Our approach effectively synthesizes color information from 3D confocal images, closely approximating target outcomes and suggesting enhanced potential for diagnostic and monitoring applications in ophthalmology.
Read more8/9/2024
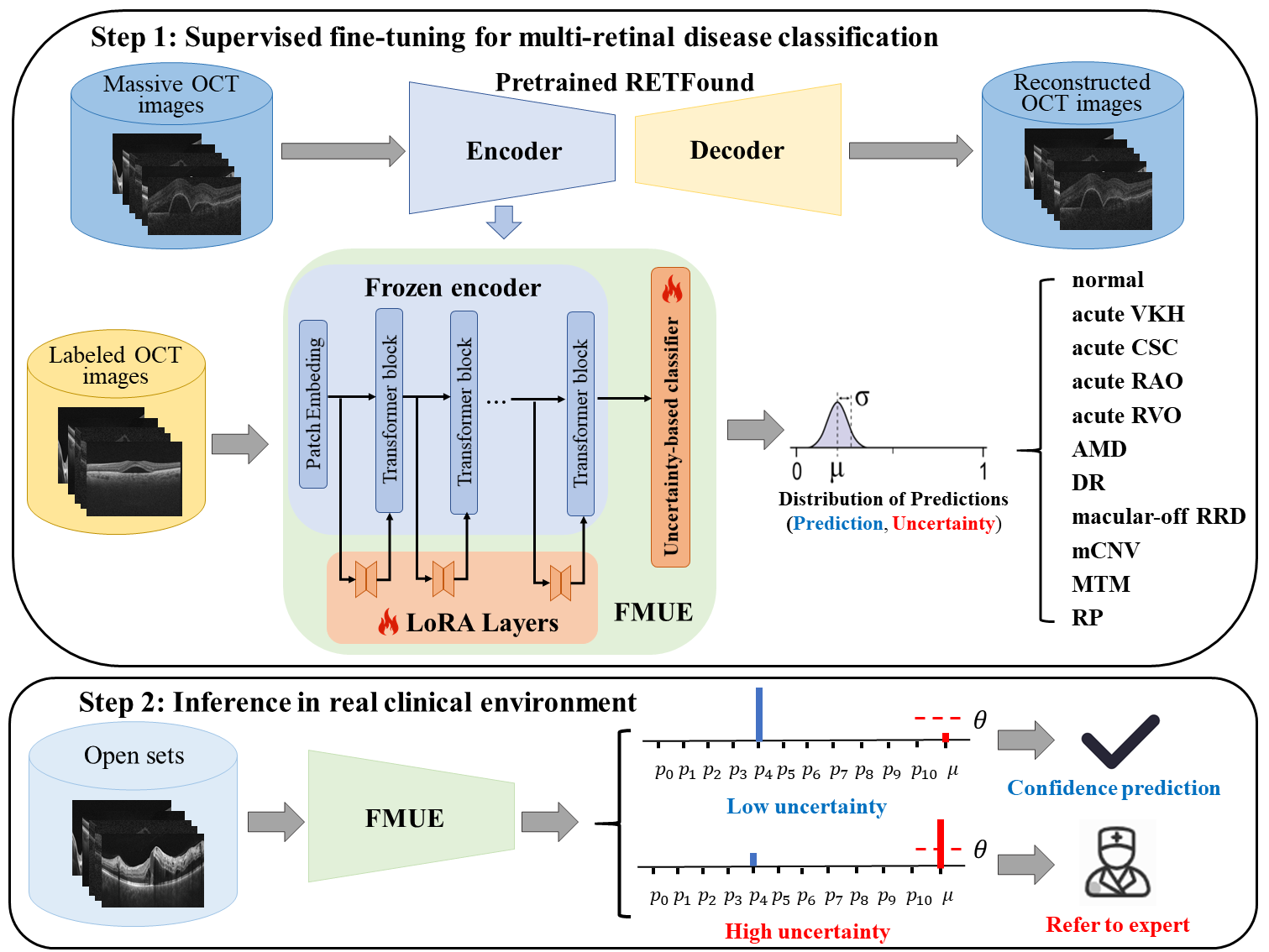
0
Enhancing Diagnostic Reliability of Foundation Model with Uncertainty Estimation in OCT Images
Yuanyuan Peng, Aidi Lin, Meng Wang, Tian Lin, Ke Zou, Yinglin Cheng, Tingkun Shi, Xulong Liao, Lixia Feng, Zhen Liang, Xinjian Chen, Huazhu Fu, Haoyu Chen
Inability to express the confidence level and detect unseen classes has limited the clinical implementation of artificial intelligence in the real-world. We developed a foundation model with uncertainty estimation (FMUE) to detect 11 retinal conditions on optical coherence tomography (OCT). In the internal test set, FMUE achieved a higher F1 score of 96.76% than two state-of-the-art algorithms, RETFound and UIOS, and got further improvement with thresholding strategy to 98.44%. In the external test sets obtained from other OCT devices, FMUE achieved an accuracy of 88.75% and 92.73% before and after thresholding. Our model is superior to two ophthalmologists with a higher F1 score (95.17% vs. 61.93% &71.72%). Besides, our model correctly predicts high uncertainty scores for samples with ambiguous features, of non-target-category diseases, or with low-quality to prompt manual checks and prevent misdiagnosis. FMUE provides a trustworthy method for automatic retinal anomalies detection in the real-world clinical open set environment.
Read more6/26/2024

0
Beyond the Eye: A Relational Model for Early Dementia Detection Using Retinal OCTA Images
Shouyue Liu, Jinkui Hao, Yonghuai Liu, Huazhu Fu, Xinyu Guo, Shuting Zhang, Yitian Zhao
Early detection of dementia, such as Alzheimer's disease (AD) or mild cognitive impairment (MCI), is essential to enable timely intervention and potential treatment. Accurate detection of AD/MCI is challenging due to the high complexity, cost, and often invasive nature of current diagnostic techniques, which limit their suitability for large-scale population screening. Given the shared embryological origins and physiological characteristics of the retina and brain, retinal imaging is emerging as a potentially rapid and cost-effective alternative for the identification of individuals with or at high risk of AD. In this paper, we present a novel PolarNet+ that uses retinal optical coherence tomography angiography (OCTA) to discriminate early-onset AD (EOAD) and MCI subjects from controls. Our method first maps OCTA images from Cartesian coordinates to polar coordinates, allowing approximate sub-region calculation to implement the clinician-friendly early treatment of diabetic retinopathy study (ETDRS) grid analysis. We then introduce a multi-view module to serialize and analyze the images along three dimensions for comprehensive, clinically useful information extraction. Finally, we abstract the sequence embedding into a graph, transforming the detection task into a general graph classification problem. A regional relationship module is applied after the multi-view module to excavate the relationship between the sub-regions. Such regional relationship analyses validate known eye-brain links and reveal new discriminative patterns.
Read more8/12/2024