Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
2308.09372
0
0
👀
Abstract
Transformers come with a high computational cost, yet their effectiveness in addressing problems in language and vision has sparked extensive research aimed at enhancing their efficiency. However, diverse experimental conditions, spanning multiple input domains, prevent a fair comparison based solely on reported results, posing challenges for model selection. To address this gap in comparability, we design a comprehensive benchmark of more than 30 models for image classification, evaluating key efficiency aspects, including accuracy, speed, and memory usage. This benchmark provides a standardized baseline across the landscape of efficiency-oriented transformers and our framework of analysis, based on Pareto optimality, reveals surprising insights. Despite claims of other models being more efficient, ViT remains Pareto optimal across multiple metrics. We observe that hybrid attention-CNN models exhibit remarkable inference memory- and parameter-efficiency. Moreover, our benchmark shows that using a larger model in general is more efficient than using higher resolution images. Thanks to our holistic evaluation, we provide a centralized resource for practitioners and researchers, facilitating informed decisions when selecting transformers or measuring progress of the development of efficient transformers.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Transformers, a powerful deep learning model, come with high computational costs, but their effectiveness in language and vision tasks has driven extensive research to improve their efficiency.
- Diverse experimental conditions across multiple input domains make it challenging to compare model performance based solely on reported results, hindering model selection.
- To address this gap, the researchers designed a comprehensive benchmark of over 30 efficiency-oriented transformer models for image classification, evaluating key aspects like accuracy, speed, and memory usage.
- The benchmark provides a standardized baseline and uses Pareto optimality analysis to reveal surprising insights, challenging claims about other models being more efficient than the original Vision Transformer (ViT).
Plain English Explanation
Transformers are a type of deep learning model that have shown great success in language and vision tasks. However, they are computationally expensive to use, meaning they require a lot of computing power.
Researchers have been working hard to find ways to make transformers more efficient, so they can be used more widely. The problem is that different researchers have been testing transformers in different ways, using different datasets and evaluation methods. This makes it hard to compare the efficiency of different transformer models and decide which one to use.
To address this, the researchers in this paper created a standardized benchmark, or test, that evaluates over 30 different transformer models for image classification. They looked at key factors like accuracy, speed, and memory usage to get a comprehensive understanding of each model's efficiency.
Using a technique called Pareto optimality, the researchers were able to identify the most efficient transformer models. Surprisingly, they found that the original Vision Transformer (ViT) model remains one of the most efficient options, even though other models have been claimed to be more efficient. They also discovered that hybrid models that combine transformers with traditional convolutional neural networks (CNNs) can be remarkably efficient in terms of memory usage and the number of parameters.
Overall, this benchmark provides a valuable resource for researchers and practitioners to make informed decisions when selecting transformer models or measuring progress in developing more efficient transformers.
Technical Explanation
The researchers designed a comprehensive benchmark to evaluate the efficiency of over 30 transformer models for image classification. They measured key aspects such as accuracy, inference speed, and memory usage to provide a standardized baseline for comparison.
The benchmark utilized a Pareto optimality analysis, which identifies the set of models that are optimal across multiple performance metrics. This revealed surprising insights, challenging the claims that other models are more efficient than the original Vision Transformer (ViT).
The researchers found that ViT remained Pareto optimal across multiple efficiency metrics. They also observed that hybrid attention-CNN models exhibited remarkable memory and parameter efficiency during inference. Furthermore, the benchmark showed that using a larger transformer model is generally more efficient than using higher resolution images.
Critical Analysis
The researchers acknowledge that their benchmark is limited to image classification tasks and may not generalize to other domains. They also note that the performance of transformers can be sensitive to hyperparameter tuning, which was not extensively explored in this study.
Additionally, the benchmark only considers inference-time efficiency, and does not evaluate the training efficiency or energy consumption of the models. These factors may be important considerations for real-world deployment of transformer-based systems.
While the Pareto optimality analysis provides a valuable framework for understanding the trade-offs between different efficiency metrics, it does not capture the specific needs and constraints of different applications. Practitioners may need to carefully weigh these factors when selecting a transformer model for their use case.
Conclusion
This comprehensive benchmark on efficiency-oriented transformer models for image classification provides a valuable resource for both researchers and practitioners. By establishing a standardized baseline and using Pareto optimality analysis, the study challenges existing claims about the superiority of certain transformer models and reveals unexpected insights, such as the continued efficiency of the original ViT model.
The findings highlight the importance of holistic evaluation of model efficiency and the limitations of relying solely on reported results. The benchmark serves as a centralized reference point to facilitate informed decisions when selecting transformers or measuring progress in the development of more efficient transformer architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Comprehensive Survey of Model Compression and Speed up for Vision Transformers
Feiyang Chen, Ziqian Luo, Lisang Zhou, Xueting Pan, Ying Jiang
0
0
Vision Transformers (ViT) have marked a paradigm shift in computer vision, outperforming state-of-the-art models across diverse tasks. However, their practical deployment is hampered by high computational and memory demands. This study addresses the challenge by evaluating four primary model compression techniques: quantization, low-rank approximation, knowledge distillation, and pruning. We methodically analyze and compare the efficacy of these techniques and their combinations in optimizing ViTs for resource-constrained environments. Our comprehensive experimental evaluation demonstrates that these methods facilitate a balanced compromise between model accuracy and computational efficiency, paving the way for wider application in edge computing devices.
4/17/2024
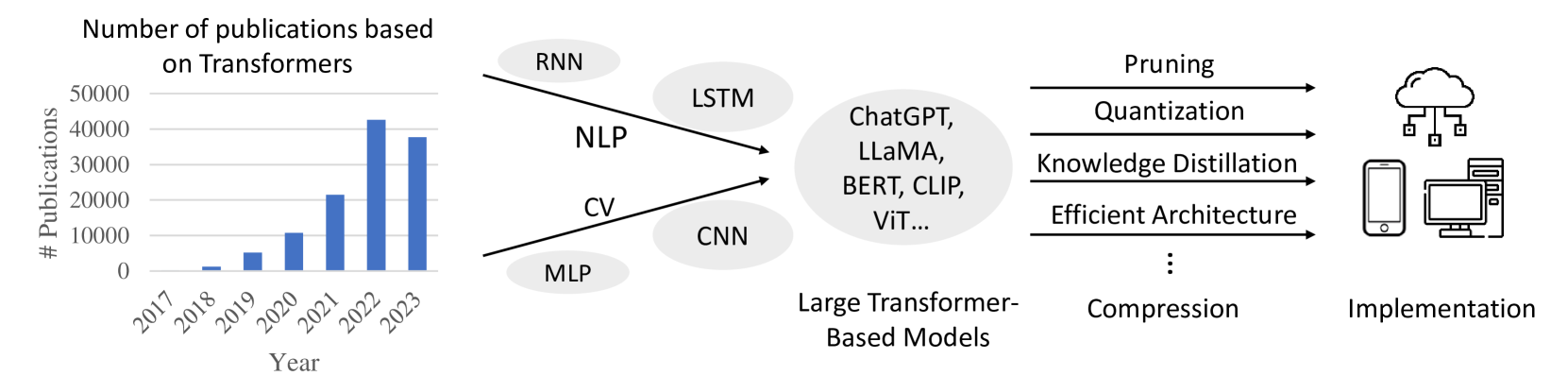
A Survey on Transformer Compression
Yehui Tang, Yunhe Wang, Jianyuan Guo, Zhijun Tu, Kai Han, Hailin Hu, Dacheng Tao
0
0
Transformer plays a vital role in the realms of natural language processing (NLP) and computer vision (CV), specially for constructing large language models (LLM) and large vision models (LVM). Model compression methods reduce the memory and computational cost of Transformer, which is a necessary step to implement large language/vision models on practical devices. Given the unique architecture of Transformer, featuring alternative attention and feedforward neural network (FFN) modules, specific compression techniques are usually required. The efficiency of these compression methods is also paramount, as retraining large models on the entire training dataset is usually impractical. This survey provides a comprehensive review of recent compression methods, with a specific focus on their application to Transformer-based models. The compression methods are primarily categorized into pruning, quantization, knowledge distillation, and efficient architecture design (Mamba, RetNet, RWKV, etc.). In each category, we discuss compression methods for both language and vision tasks, highlighting common underlying principles. Finally, we delve into the relation between various compression methods, and discuss further directions in this domain.
4/9/2024
What matters when building vision-language models?
Hugo Laurenc{c}on, L'eo Tronchon, Matthieu Cord, Victor Sanh
0
0
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
5/6/2024
👀
Vision Transformer Computation and Resilience for Dynamic Inference
Kavya Sreedhar, Jason Clemons, Rangharajan Venkatesan, Stephen W. Keckler, Mark Horowitz
0
0
State-of-the-art deep learning models for computer vision tasks are based on the transformer architecture and often deployed in real-time applications. In this scenario, the resources available for every inference can vary, so it is useful to be able to dynamically adapt execution to trade accuracy for efficiency. To create dynamic models, we leverage the resilience of vision transformers to pruning and switch between different scaled versions of a model. Surprisingly, we find that most FLOPs are generated by convolutions, not attention. These relative FLOP counts are not a good predictor of GPU performance since GPUs have special optimizations for convolutions. Some models are fairly resilient and their model execution can be adapted without retraining, while all models achieve better accuracy with retraining alternative execution paths. These insights mean that we can leverage CNN accelerators and these alternative execution paths to enable efficient and dynamic vision transformer inference. Our analysis shows that leveraging this type of dynamic execution can lead to saving 28% of energy with a 1.4% accuracy drop for SegFormer (63 GFLOPs), with no additional training, and 53% of energy for ResNet-50 (4 GFLOPs) with a 3.3% accuracy drop by switching between pretrained Once-For-All models.
4/17/2024