NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
2403.02411
0
0
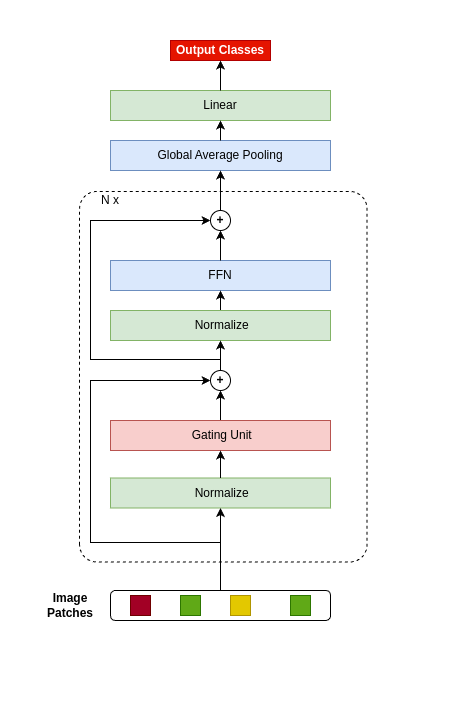
Abstract
The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a novel "NiNformer" model that combines a Network-in-Network (NiN) architecture with a Transformer-based design
- Introduces a token mixing generated gating function to enhance the model's efficiency and performance
- Evaluates the NiNformer on various computer vision tasks, demonstrating its effectiveness compared to other state-of-the-art models
Plain English Explanation
The NiNformer is a new type of deep learning model that combines two powerful concepts: the Network-in-Network (NiN) architecture and the Transformer design. The NiN approach allows the model to learn more complex and hierarchical features, while the Transformer component enables it to effectively capture long-range dependencies in the data.
A key innovation in the NiNformer is the introduction of a "token mixing generated gating function." This function helps the model selectively attend to the most relevant information, making it more efficient and accurate in tasks like image recognition and classification. The gating function is generated directly from the token mixing process, rather than being a separate component, which helps to streamline the model's architecture.
The researchers evaluate the NiNformer on several computer vision benchmarks and find that it outperforms other state-of-the-art models, including MLP-based Transformers and hierarchical Vision Transformers. This suggests that the combination of NiN and Transformer components, along with the novel gating function, can be a powerful approach for building efficient and high-performing computer vision models.
Technical Explanation
The NiNformer is a deep learning model that integrates the Network-in-Network (NiN) architecture with a Transformer-based design. NiN allows the model to learn more complex and hierarchical features by applying multiple convolutional layers within each stage of the network. The Transformer component, on the other hand, enables the model to effectively capture long-range dependencies in the input data.
A key contribution of the NiNformer is the introduction of a "token mixing generated gating function." This function is used to selectively attend to the most relevant information during the token mixing process, which is a crucial step in the Transformer architecture. The gating function is generated directly from the token mixing, rather than being a separate component, which helps to streamline the model's architecture and improve its efficiency.
The researchers evaluate the NiNformer on various computer vision tasks, including image classification, object detection, and semantic segmentation. They compare the NiNformer's performance to other state-of-the-art models, such as MLP-based Transformers, Efficient Transformers, and Hierarchical Vision Transformers. The results demonstrate that the NiNformer outperforms these models on multiple benchmarks, indicating the effectiveness of the proposed architecture and the token mixing generated gating function.
Critical Analysis
The NiNformer paper presents a novel and promising approach to combining the strengths of NiN and Transformer architectures for computer vision tasks. The authors have thoughtfully designed the model and conducted thorough experiments to validate its performance.
One potential limitation of the research is the lack of a comprehensive analysis of the model's performance on a wider range of computer vision tasks and datasets. While the results are promising on the evaluated benchmarks, it would be valuable to see how the NiNformer fares on more diverse and challenging datasets to better understand its generalization capabilities.
Additionally, the paper does not provide much insight into the interpretability of the NiNformer's internal workings. Understanding how the token mixing generated gating function operates and influences the model's decision-making process could offer valuable insights for researchers and practitioners interested in explainable AI.
Future work could also explore the NiNformer's performance in domains beyond computer vision, such as natural language processing or multimodal tasks, to assess the broader applicability of the proposed architecture and techniques.
Conclusion
The NiNformer represents a significant advancement in the field of computer vision by effectively combining the strengths of Network-in-Network and Transformer-based architectures. The introduction of the token mixing generated gating function is a particularly noteworthy contribution, as it enhances the model's efficiency and performance without increasing the overall complexity of the architecture.
The promising results demonstrated on various computer vision benchmarks suggest that the NiNformer could be a valuable tool for researchers and practitioners working on a wide range of computer vision applications, from image classification to object detection and beyond. As the field of deep learning continues to evolve, innovations like the NiNformer will play a crucial role in pushing the boundaries of what is possible in computer vision and related domains.
Related Papers
👀
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Moein Heidari, Reza Azad, Sina Ghorbani Kolahi, Ren'e Arimond, Leon Niggemeier, Alaa Sulaiman, Afshin Bozorgpour, Ehsan Khodapanah Aghdam, Amirhossein Kazerouni, Ilker Hacihaliloglu, Dorit Merhof
0
0
Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}footnote{url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
4/1/2024
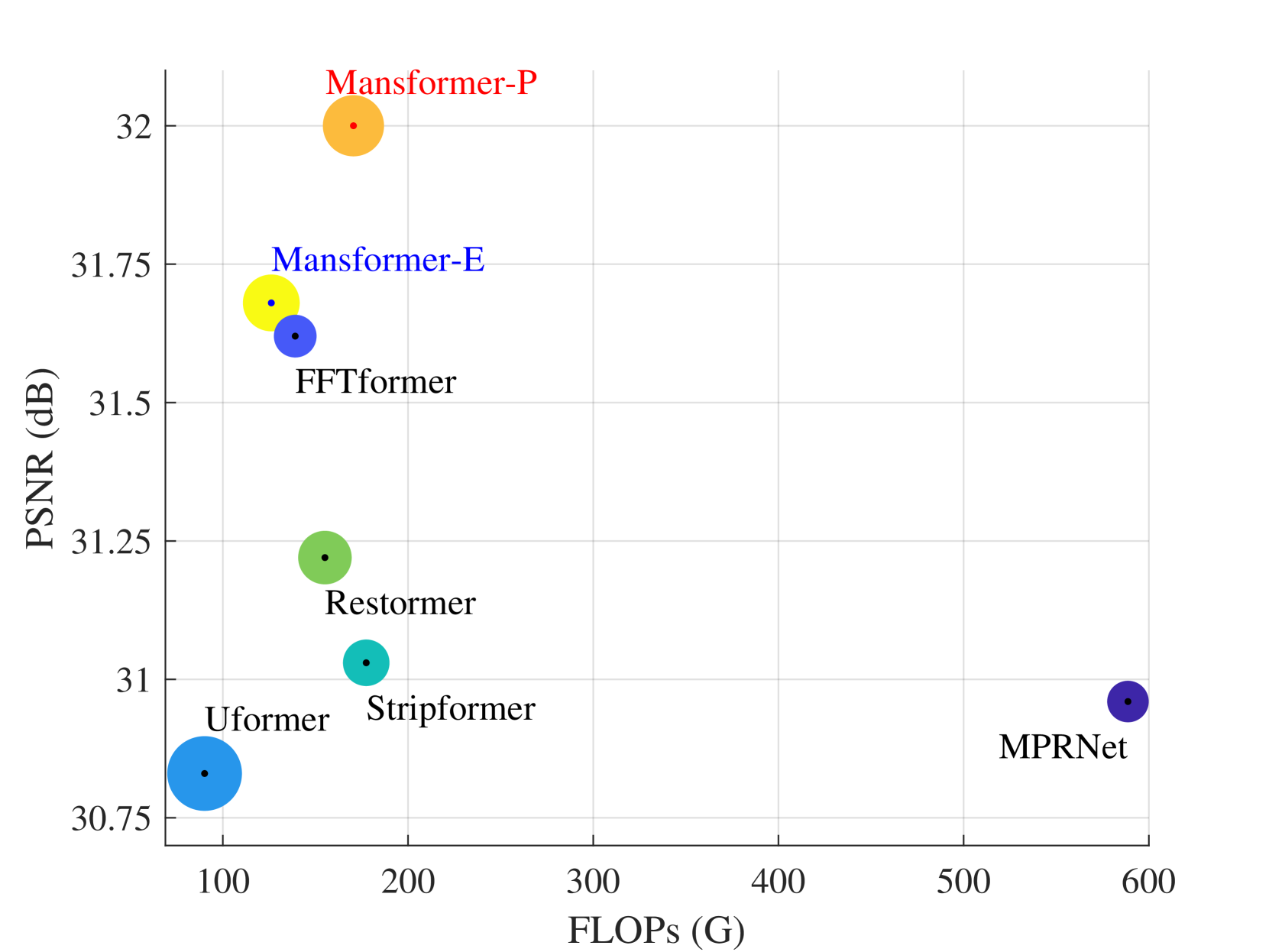
Mansformer: Efficient Transformer of Mixed Attention for Image Deblurring and Beyond
Pin-Hung Kuo, Jinshan Pan, Shao-Yi Chien, Ming-Hsuan Yang
0
0
Transformer has made an enormous success in natural language processing and high-level vision over the past few years. However, the complexity of self-attention is quadratic to the image size, which makes it infeasible for high-resolution vision tasks. In this paper, we propose the Mansformer, a Transformer of mixed attention that combines multiple self-attentions, gate, and multi-layer perceptions (MLPs), to explore and employ more possibilities of self-attention. Taking efficiency into account, we design four kinds of self-attention, whose complexities are all linear. By elaborate adjustment of the tensor shapes and dimensions for the dot product, we split the typical self-attention of quadratic complexity into four operations of linear complexity. To adaptively merge these different kinds of self-attention, we take advantage of an architecture similar to Squeeze-and-Excitation Networks. Furthermore, we make it to merge the two-staged Transformer design into one stage by the proposed gated-dconv MLP. Image deblurring is our main target, while extensive quantitative and qualitative evaluations show that this method performs favorably against the state-of-the-art methods far more than simply deblurring. The source codes and trained models will be made available to the public.
4/10/2024
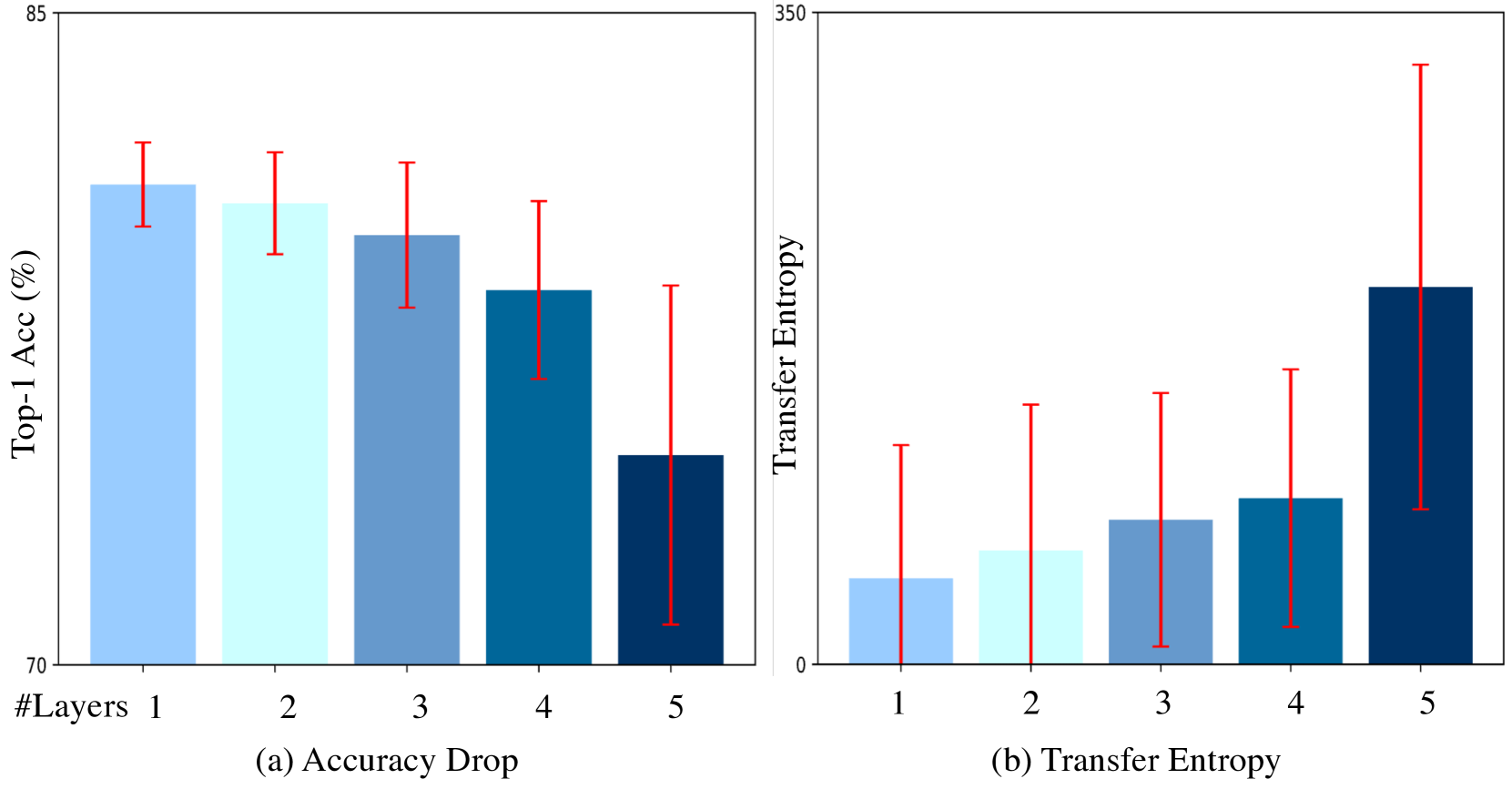
MLP Can Be A Good Transformer Learner
Sihao Lin, Pumeng Lyu, Dongrui Liu, Tao Tang, Xiaodan Liang, Andy Song, Xiaojun Chang
0
0
Self-attention mechanism is the key of the Transformer but often criticized for its computation demands. Previous token pruning works motivate their methods from the view of computation redundancy but still need to load the full network and require same memory costs. This paper introduces a novel strategy that simplifies vision transformers and reduces computational load through the selective removal of non-essential attention layers, guided by entropy considerations. We identify that regarding the attention layer in bottom blocks, their subsequent MLP layers, i.e. two feed-forward layers, can elicit the same entropy quantity. Meanwhile, the accompanied MLPs are under-exploited since they exhibit smaller feature entropy compared to those MLPs in the top blocks. Therefore, we propose to integrate the uninformative attention layers into their subsequent counterparts by degenerating them into identical mapping, yielding only MLP in certain transformer blocks. Experimental results on ImageNet-1k show that the proposed method can remove 40% attention layer of DeiT-B, improving throughput and memory bound without performance compromise. Code is available at https://github.com/sihaoevery/lambda_vit.
4/9/2024
👨🏫
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
0
0
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
5/3/2024