Enhancing HNSW Index for Real-Time Updates: Addressing Unreachable Points and Performance Degradation

0
Sign in to get full access
Overview
- This paper presents an enhanced version of the Hierarchical Navigable Small World (HNSW) index, a graph-based data structure used for approximate nearest neighbor (ANN) search.
- The authors address two key limitations of the original HNSW index: the inability to handle unreachable points and performance degradation over time.
- The proposed enhancements aim to improve the index's ability to handle real-time updates and maintain high search performance, even as the dataset grows and changes.
Plain English Explanation
The paper focuses on improving a powerful data structure called the Hierarchical Navigable Small World (HNSW) index, which is used for approximate nearest neighbor search. The HNSW index is a graph-based approach that allows for fast retrieval of similar items in a large dataset.
However, the original HNSW index had some limitations. First, it struggled to handle "unreachable" points - data points that were isolated from the rest of the graph and couldn't be easily found during searches. Second, the index's performance tended to degrade over time as the dataset grew and changed.
To address these issues, the researchers enhanced the HNSW index in two key ways:
- They developed a new mechanism to better handle unreachable points, ensuring they can be efficiently accessed during searches.
- They improved the index's ability to handle real-time updates, such as adding or removing data points, without seeing a significant drop in search performance.
These enhancements make the HNSW index more robust and practical for use in real-world applications that require quick access to large, dynamic datasets, such as recommendation systems or high-dimensional similarity search.
Technical Explanation
The paper proposes two key enhancements to the HNSW index:
-
Handling Unreachable Points: The authors introduce a new mechanism to deal with unreachable points, which are data points that become isolated from the main graph structure and are difficult to find during searches. They achieve this by maintaining a separate "overflow" layer in the index that stores these unreachable points and ensures they can still be accessed efficiently.
-
Improving Real-Time Update Performance: To address the issue of performance degradation over time, the researchers developed a new update strategy that better preserves the index's structure and search performance, even as new data is added or removed. This involved changes to the way the index's internal connections are managed and updated.
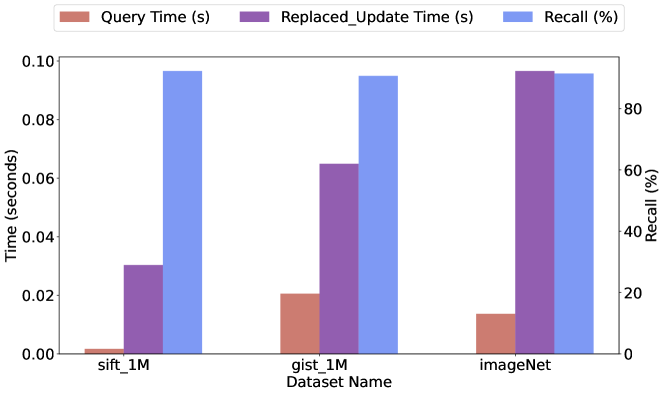
The paper presents a detailed experimental evaluation of the enhanced HNSW index, comparing its performance to the original version as well as other state-of-the-art ANN search approaches, such as FANNG and CAGRA. The results demonstrate significant improvements in both handling unreachable points and maintaining high search performance, even as the dataset grows and changes over time.
Critical Analysis
The paper provides a thorough and well-designed study of the enhanced HNSW index. The authors have clearly identified and addressed two important limitations of the original HNSW approach, which is a significant contribution to the field of approximate nearest neighbor search.
However, the paper does not discuss potential limitations or areas for further research in depth. For example, the authors do not explore how the enhanced HNSW index might perform in high-dimensional or extremely large-scale datasets, or how it compares to other ANN approaches in terms of memory usage and index construction time.
Additionally, while the experimental results are promising, the paper could benefit from a more robust analysis of the tradeoffs involved in the proposed enhancements, such as the impact on index size or the computational overhead of maintaining the overflow layer.
Overall, the paper makes a valuable contribution by enhancing the HNSW index, but there is still room for further research and analysis to fully understand the strengths, limitations, and practical implications of this approach.
Conclusion
This paper presents an enhanced version of the Hierarchical Navigable Small World (HNSW) index, a powerful graph-based data structure used for approximate nearest neighbor (ANN) search. The authors address two key limitations of the original HNSW index: the inability to handle unreachable points and performance degradation over time.
The proposed enhancements improve the index's ability to handle real-time updates and maintain high search performance, even as the dataset grows and changes. This makes the HNSW index more robust and practical for use in real-world applications that require fast access to large, dynamic datasets, such as recommendation systems or high-dimensional similarity search.
While the paper provides a thorough evaluation of the enhanced HNSW index, there are still opportunities for further research to fully understand its strengths, limitations, and potential tradeoffs. Nonetheless, this work represents an important step forward in improving the performance and versatility of graph-based ANN search approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing HNSW Index for Real-Time Updates: Addressing Unreachable Points and Performance Degradation
Wentao Xiao, Yueyang Zhan, Rui Xi, Mengshu Hou, Jianming Liao
The approximate nearest neighbor search (ANNS) is a fundamental and essential component in data mining and information retrieval, with graph-based methodologies demonstrating superior performance compared to alternative approaches. Extensive research efforts have been dedicated to improving search efficiency by developing various graph-based indices, such as HNSW (Hierarchical Navigable Small World). However, the performance of HNSW and most graph-based indices become unacceptable when faced with a large number of real-time deletions, insertions, and updates. Furthermore, during update operations, HNSW can result in some data points becoming unreachable, a situation we refer to as the `unreachable points phenomenon'. This phenomenon could significantly affect the search accuracy of the graph in certain situations. To address these issues, we present efficient measures to overcome the shortcomings of HNSW, specifically addressing poor performance over long periods of delete and update operations and resolving the issues caused by the unreachable points phenomenon. Our proposed MN-RU algorithm effectively improves update efficiency and suppresses the growth rate of unreachable points, ensuring better overall performance and maintaining the integrity of the graph. Our results demonstrate that our methods outperform existing approaches. Furthermore, since our methods are based on HNSW, they can be easily integrated with existing indices widely used in the industrial field, making them practical for future real-world applications. Code is available at url{https://github.com/xwt1/MN-RU.git}
Read more7/16/2024

0
The Impacts of Data, Ordering, and Intrinsic Dimensionality on Recall in Hierarchical Navigable Small Worlds
Owen Pendrigh Elliott, Jesse Clark
Vector search systems, pivotal in AI applications, often rely on the Hierarchical Navigable Small Worlds (HNSW) algorithm. However, the behaviour of HNSW under real-world scenarios using vectors generated with deep learning models remains under-explored. Existing Approximate Nearest Neighbours (ANN) benchmarks and research typically has an over-reliance on simplistic datasets like MNIST or SIFT1M and fail to reflect the complexity of current use-cases. Our investigation focuses on HNSW's efficacy across a spectrum of datasets, including synthetic vectors tailored to mimic specific intrinsic dimensionalities, widely-used retrieval benchmarks with popular embedding models, and proprietary e-commerce image data with CLIP models. We survey the most popular HNSW vector databases and collate their default parameters to provide a realistic fixed parameterisation for the duration of the paper. We discover that the recall of approximate HNSW search, in comparison to exact K Nearest Neighbours (KNN) search, is linked to the vector space's intrinsic dimensionality and significantly influenced by the data insertion sequence. Our methodology highlights how insertion order, informed by measurable properties such as the pointwise Local Intrinsic Dimensionality (LID) or known categories, can shift recall by up to 12 percentage points. We also observe that running popular benchmark datasets with HNSW instead of KNN can shift rankings by up to three positions for some models. This work underscores the need for more nuanced benchmarks and design considerations in developing robust vector search systems using approximate vector search algorithms. This study presents a number of scenarios with varying real world applicability which aim to better increase understanding and future development of ANN algorithms and embedding
Read more5/29/2024
🔄
0
Probabilistic Routing for Graph-Based Approximate Nearest Neighbor Search
Kejing Lu, Chuan Xiao, Yoshiharu Ishikawa
Approximate nearest neighbor search (ANNS) in high-dimensional spaces is a pivotal challenge in the field of machine learning. In recent years, graph-based methods have emerged as the superior approach to ANNS, establishing a new state of the art. Although various optimizations for graph-based ANNS have been introduced, they predominantly rely on heuristic methods that lack formal theoretical backing. This paper aims to enhance routing within graph-based ANNS by introducing a method that offers a probabilistic guarantee when exploring a node's neighbors in the graph. We formulate the problem as probabilistic routing and develop two baseline strategies by incorporating locality-sensitive techniques. Subsequently, we introduce PEOs, a novel approach that efficiently identifies which neighbors in the graph should be considered for exact distance calculation, thus significantly improving efficiency in practice. Our experiments demonstrate that equipping PEOs can increase throughput on commonly utilized graph indexes (HNSW and NSSG) by a factor of 1.6 to 2.5, and its efficiency consistently outperforms the leading-edge routing technique by 1.1 to 1.4 times.
Read more7/11/2024
🧪
0
CAGRA: Highly Parallel Graph Construction and Approximate Nearest Neighbor Search for GPUs
Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, Yong Wang
Approximate Nearest Neighbor Search (ANNS) plays a critical role in various disciplines spanning data mining and artificial intelligence, from information retrieval and computer vision to natural language processing and recommender systems. Data volumes have soared in recent years and the computational cost of an exhaustive exact nearest neighbor search is often prohibitive, necessitating the adoption of approximate techniques. The balanced performance and recall of graph-based approaches have more recently garnered significant attention in ANNS algorithms, however, only a few studies have explored harnessing the power of GPUs and multi-core processors despite the widespread use of massively parallel and general-purpose computing. To bridge this gap, we introduce a novel parallel computing hardware-based proximity graph and search algorithm. By leveraging the high-performance capabilities of modern hardware, our approach achieves remarkable efficiency gains. In particular, our method surpasses existing CPU and GPU-based methods in constructing the proximity graph, demonstrating higher throughput in both large- and small-batch searches while maintaining compatible accuracy. In graph construction time, our method, CAGRA, is 2.2~27x faster than HNSW, which is one of the CPU SOTA implementations. In large-batch query throughput in the 90% to 95% recall range, our method is 33~77x faster than HNSW, and is 3.8~8.8x faster than the SOTA implementations for GPU. For a single query, our method is 3.4~53x faster than HNSW at 95% recall.
Read more7/10/2024