The Impacts of Data, Ordering, and Intrinsic Dimensionality on Recall in Hierarchical Navigable Small Worlds

0

Sign in to get full access
Overview
- This paper investigates the impacts of data, ordering, and intrinsic dimensionality on recall performance in hierarchical navigable small-world (HNSW) networks.
- HNSW networks are a type of approximate nearest neighbor search algorithm used for efficient retrieval in large-scale datasets.
- The authors explore how various factors like dataset characteristics, index construction, and intrinsic dimensionality affect the ability to accurately retrieve relevant items from the network.
Plain English Explanation
The paper looks at how different things can impact the performance of a certain type of search algorithm called hierarchical navigable small-world (HNSW) networks. HNSW networks are used to quickly find items that are similar to a given input, even in very large datasets.
The researchers examined how the characteristics of the data, the way the data is organized, and the inherent complexity of the data can affect how well the HNSW network is able to retrieve the most relevant items. For example, they looked at how the size and structure of the dataset, as well as the natural "dimensionality" or complexity of the data, can influence the accuracy of the search results.
By understanding these factors, the researchers hope to provide guidance on how to best set up and use HNSW networks to get the most reliable search results, especially for large and complex datasets. This could be useful in a variety of applications that rely on quickly finding similar items, like recommendation systems, image retrieval, and document search.
Technical Explanation
The paper examines how data characteristics, index construction, and intrinsic dimensionality impact the recall performance of hierarchical navigable small-world (HNSW) networks, a type of approximate nearest neighbor search algorithm.
The authors conduct extensive experiments on various synthetic and real-world datasets to assess the effects of:
- Dataset size and structure
- Data ordering during index construction
- Intrinsic dimensionality of the data
They find that dataset size and intrinsic dimensionality have a significant impact on recall, with larger and more complex datasets leading to decreased performance. The ordering of data during index construction is also shown to be an important factor, with certain strategies outperforming others.
The results provide insights into how to optimize HNSW networks for high-recall retrieval, particularly in the context of large-scale and complex datasets. The authors discuss the implications of their findings and suggest areas for future research.
Critical Analysis
The paper provides a thorough and well-designed empirical evaluation of the factors influencing recall performance in HNSW networks. The authors acknowledge several limitations, such as the use of synthetic datasets and the focus on recall rather than other metrics like precision or efficiency.
One potential issue is the reliance on a single type of approximate nearest neighbor algorithm (HNSW). It would be interesting to see how the findings compare to other ANN methods, such as IVFADC or LeanVec. Additionally, the paper does not explore the impact of hyperparameter tuning on HNSW performance, which could be an important factor in real-world applications.
Overall, the research provides valuable insights into the design and deployment of HNSW networks, but further investigation into the generalizability of the findings and the practical implications for different use cases would be beneficial.
Conclusion
This paper offers a detailed examination of the factors that can influence the recall performance of hierarchical navigable small-world (HNSW) networks, a popular approximate nearest neighbor search algorithm. The authors demonstrate that dataset characteristics, such as size and intrinsic dimensionality, as well as the ordering of data during index construction, can have a significant impact on the ability of HNSW networks to accurately retrieve relevant items.
These findings provide important guidance for practitioners seeking to utilize HNSW networks in large-scale and complex data environments, where efficient and reliable retrieval is crucial. By understanding the nuances of HNSW performance, researchers and engineers can make more informed decisions about algorithm selection, data preprocessing, and index construction to optimize search quality in a wide range of applications, from recommendation systems to document search.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Impacts of Data, Ordering, and Intrinsic Dimensionality on Recall in Hierarchical Navigable Small Worlds
Owen Pendrigh Elliott, Jesse Clark
Vector search systems, pivotal in AI applications, often rely on the Hierarchical Navigable Small Worlds (HNSW) algorithm. However, the behaviour of HNSW under real-world scenarios using vectors generated with deep learning models remains under-explored. Existing Approximate Nearest Neighbours (ANN) benchmarks and research typically has an over-reliance on simplistic datasets like MNIST or SIFT1M and fail to reflect the complexity of current use-cases. Our investigation focuses on HNSW's efficacy across a spectrum of datasets, including synthetic vectors tailored to mimic specific intrinsic dimensionalities, widely-used retrieval benchmarks with popular embedding models, and proprietary e-commerce image data with CLIP models. We survey the most popular HNSW vector databases and collate their default parameters to provide a realistic fixed parameterisation for the duration of the paper. We discover that the recall of approximate HNSW search, in comparison to exact K Nearest Neighbours (KNN) search, is linked to the vector space's intrinsic dimensionality and significantly influenced by the data insertion sequence. Our methodology highlights how insertion order, informed by measurable properties such as the pointwise Local Intrinsic Dimensionality (LID) or known categories, can shift recall by up to 12 percentage points. We also observe that running popular benchmark datasets with HNSW instead of KNN can shift rankings by up to three positions for some models. This work underscores the need for more nuanced benchmarks and design considerations in developing robust vector search systems using approximate vector search algorithms. This study presents a number of scenarios with varying real world applicability which aim to better increase understanding and future development of ANN algorithms and embedding
Read more5/29/2024
🌐
0
Operational Advice for Dense and Sparse Retrievers: HNSW, Flat, or Inverted Indexes?
Jimmy Lin
Practitioners working on dense retrieval today face a bewildering number of choices. Beyond selecting the embedding model, another consequential choice is the actual implementation of nearest-neighbor vector search. While best practices recommend HNSW indexes, flat vector indexes with brute-force search represent another viable option, particularly for smaller corpora and for rapid prototyping. In this paper, we provide experimental results on the BEIR dataset using the open-source Lucene search library that explicate the tradeoffs between HNSW and flat indexes (including quantized variants) from the perspectives of indexing time, query evaluation performance, and retrieval quality. With additional comparisons between dense and sparse retrievers, our results provide guidance for today's search practitioner in understanding the design space of dense and sparse retrievers. To our knowledge, we are the first to provide operational advice supported by empirical experiments in this regard.
Read more9/11/2024
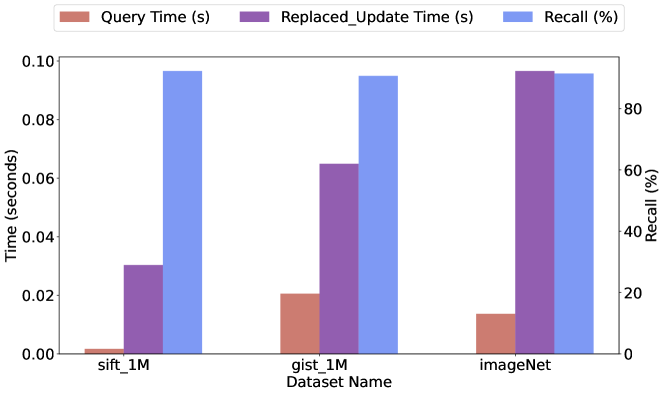
0
Enhancing HNSW Index for Real-Time Updates: Addressing Unreachable Points and Performance Degradation
Wentao Xiao, Yueyang Zhan, Rui Xi, Mengshu Hou, Jianming Liao
The approximate nearest neighbor search (ANNS) is a fundamental and essential component in data mining and information retrieval, with graph-based methodologies demonstrating superior performance compared to alternative approaches. Extensive research efforts have been dedicated to improving search efficiency by developing various graph-based indices, such as HNSW (Hierarchical Navigable Small World). However, the performance of HNSW and most graph-based indices become unacceptable when faced with a large number of real-time deletions, insertions, and updates. Furthermore, during update operations, HNSW can result in some data points becoming unreachable, a situation we refer to as the `unreachable points phenomenon'. This phenomenon could significantly affect the search accuracy of the graph in certain situations. To address these issues, we present efficient measures to overcome the shortcomings of HNSW, specifically addressing poor performance over long periods of delete and update operations and resolving the issues caused by the unreachable points phenomenon. Our proposed MN-RU algorithm effectively improves update efficiency and suppresses the growth rate of unreachable points, ensuring better overall performance and maintaining the integrity of the graph. Our results demonstrate that our methods outperform existing approaches. Furthermore, since our methods are based on HNSW, they can be easily integrated with existing indices widely used in the industrial field, making them practical for future real-world applications. Code is available at url{https://github.com/xwt1/MN-RU.git}
Read more7/16/2024

0
Hierarchical Structured Neural Network for Retrieval
Kaushik Rangadurai, Siyang Yuan, Minhui Huang, Yiqun Liu, Golnaz Ghasemiesfeh, Yunchen Pu, Xinfeng Xie, Xingfeng He, Fangzhou Xu, Andrew Cui, Vidhoon Viswanathan, Yan Dong, Liang Xiong, Lin Yang, Liang Wang, Jiyan Yang, Chonglin Sun
Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
Read more8/14/2024