Enhancing Label-efficient Medical Image Segmentation with Text-guided Diffusion Models

0

Sign in to get full access
Overview
- This paper explores using text-guided diffusion models to enhance label-efficient medical image segmentation.
- Diffusion models are a type of generative AI that can be used to segment medical images with limited labeled data.
- The key innovation is leveraging text descriptions to guide the diffusion process and improve segmentation performance.
Plain English Explanation
Medical image segmentation is the process of identifying and outlining different anatomical structures in medical scans like X-rays or MRIs. This is an important task for aiding diagnosis and treatment planning. Diffusion models are a powerful new AI technique that can perform segmentation without requiring large amounts of labeled training data.
The researchers in this paper wanted to see if they could further improve the performance of diffusion-based medical image segmentation by incorporating text-based guidance. The idea is that providing the model with descriptive text about the anatomical structures in the image could help it better understand what it's supposed to segment.
For example, if the model is given an X-ray image and a text description like "the heart is located in the center of the chest, surrounded by the lungs," it may be able to more accurately outline the heart and lungs in the image, even if it hasn't seen many labeled examples. This text-guided approach could make diffusion models more effective for medical image segmentation when only limited labeled data is available.
Technical Explanation
The key technical components of this work include:
-
Text-Guided Diffusion Model: The researchers developed a diffusion model architecture that takes both the input medical image and a text description as inputs. The text is used to condition the diffusion process, guiding the model towards generating a segmentation mask that aligns with the provided description.
-
Training Procedure: The model is trained in a two-stage process. First, it is pre-trained on a large corpus of image-text pairs to learn general associations between visual and textual concepts. Then, it is fine-tuned on the target medical image segmentation task using limited labeled data, with the text descriptions providing additional supervisory signal.
-
Evaluation: The researchers evaluated their text-guided diffusion model on several medical image segmentation benchmarks, including brain, heart, and abdomen MRI datasets. They compared its performance to baseline diffusion models as well as other state-of-the-art segmentation approaches.
The results showed that the text-guided diffusion model outperformed the baselines, particularly when only a small amount of labeled training data was available. This demonstrates the value of leveraging complementary text information to enhance the label efficiency of medical image segmentation.
Critical Analysis
One potential limitation of this approach is that it relies on having access to high-quality text descriptions for the medical images, which may not always be readily available. The researchers acknowledge this and suggest exploring ways to automatically generate suitable text prompts from the image data itself.
Additionally, the paper does not delve deeply into the specific mechanisms by which the text guidance improves the diffusion process. Further research could investigate the inner workings of the text-guided model to gain a better understanding of how the textual information is being utilized.
It would also be interesting to see how this approach performs on a broader range of medical imaging modalities and segmentation tasks, beyond the specific benchmarks evaluated in this paper. Expanding the scope of the evaluation could provide a more comprehensive assessment of the method's generalizability.
Conclusion
This paper presents a novel approach to enhancing label-efficient medical image segmentation using text-guided diffusion models. By leveraging complementary text information to guide the diffusion process, the researchers were able to improve segmentation performance compared to standard diffusion-based methods, particularly in low-data regimes.
The findings suggest that incorporating textual cues could be a promising direction for improving the sample efficiency of AI-based medical image analysis, which could have significant implications for clinical applications where labeled data is scarce. Further research is needed to fully understand the mechanisms behind this approach and explore its broader applicability across different medical imaging domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Label-efficient Medical Image Segmentation with Text-guided Diffusion Models
Chun-Mei Feng
Aside from offering state-of-the-art performance in medical image generation, denoising diffusion probabilistic models (DPM) can also serve as a representation learner to capture semantic information and potentially be used as an image representation for downstream tasks, e.g., segmentation. However, these latent semantic representations rely heavily on labor-intensive pixel-level annotations as supervision, limiting the usability of DPM in medical image segmentation. To address this limitation, we propose an enhanced diffusion segmentation model, called TextDiff, that improves semantic representation through inexpensive medical text annotations, thereby explicitly establishing semantic representation and language correspondence for diffusion models. Concretely, TextDiff extracts intermediate activations of the Markov step of the reverse diffusion process in a pretrained diffusion model on large-scale natural images and learns additional expert knowledge by combining them with complementary and readily available diagnostic text information. TextDiff freezes the dual-branch multi-modal structure and mines the latent alignment of semantic features in diffusion models with diagnostic descriptions by only training the cross-attention mechanism and pixel classifier, making it possible to enhance semantic representation with inexpensive text. Extensive experiments on public QaTa-COVID19 and MoNuSeg datasets show that our TextDiff is significantly superior to the state-of-the-art multi-modal segmentation methods with only a few training samples.
Read more7/9/2024

0
Denoising Diffusions in Latent Space for Medical Image Segmentation
Fahim Ahmed Zaman, Mathews Jacob, Amanda Chang, Kan Liu, Milan Sonka, Xiaodong Wu
Diffusion models (DPMs) have demonstrated remarkable performance in image generation, often times outperforming other generative models. Since their introduction, the powerful noise-to-image denoising pipeline has been extended to various discriminative tasks, including image segmentation. In case of medical imaging, often times the images are large 3D scans, where segmenting one image using DPMs become extremely inefficient due to large memory consumption and time consuming iterative sampling process. In this work, we propose a novel conditional generative modeling framework (LDSeg) that performs diffusion in latent space for medical image segmentation. Our proposed framework leverages the learned inherent low-dimensional latent distribution of the target object shapes and source image embeddings. The conditional diffusion in latent space not only ensures accurate n-D image segmentation for multi-label objects, but also mitigates the major underlying problems of the traditional DPM based segmentation: (1) large memory consumption, (2) time consuming sampling process and (3) unnatural noise injection in forward/reverse process. LDSeg achieved state-of-the-art segmentation accuracy on three medical image datasets with different imaging modalities. Furthermore, we show that our proposed model is significantly more robust to noises, compared to the traditional deterministic segmentation models, which can be potential in solving the domain shift problems in the medical imaging domain. Codes are available at: https://github.com/LDSeg/LDSeg.
Read more7/19/2024

0
Panoptic Segmentation of Mammograms with Text-To-Image Diffusion Model
Kun Zhao, Jakub Prokop, Javier Montalt Tordera, Sadegh Mohammadi
Mammography is crucial for breast cancer surveillance and early diagnosis. However, analyzing mammography images is a demanding task for radiologists, who often review hundreds of mammograms daily, leading to overdiagnosis and overtreatment. Computer-Aided Diagnosis (CAD) systems have been developed to assist in this process, but their capabilities, particularly in lesion segmentation, remained limited. With the contemporary advances in deep learning their performance may be improved. Recently, vision-language diffusion models emerged, demonstrating outstanding performance in image generation and transferability to various downstream tasks. We aim to harness their capabilities for breast lesion segmentation in a panoptic setting, which encompasses both semantic and instance-level predictions. Specifically, we propose leveraging pretrained features from a Stable Diffusion model as inputs to a state-of-the-art panoptic segmentation architecture, resulting in accurate delineation of individual breast lesions. To bridge the gap between natural and medical imaging domains, we incorporated a mammography-specific MAM-E diffusion model and BiomedCLIP image and text encoders into this framework. We evaluated our approach on two recently published mammography datasets, CDD-CESM and VinDr-Mammo. For the instance segmentation task, we noted 40.25 AP0.1 and 46.82 AP0.05, as well as 25.44 PQ0.1 and 26.92 PQ0.05. For the semantic segmentation task, we achieved Dice scores of 38.86 and 40.92, respectively.
Read more7/22/2024
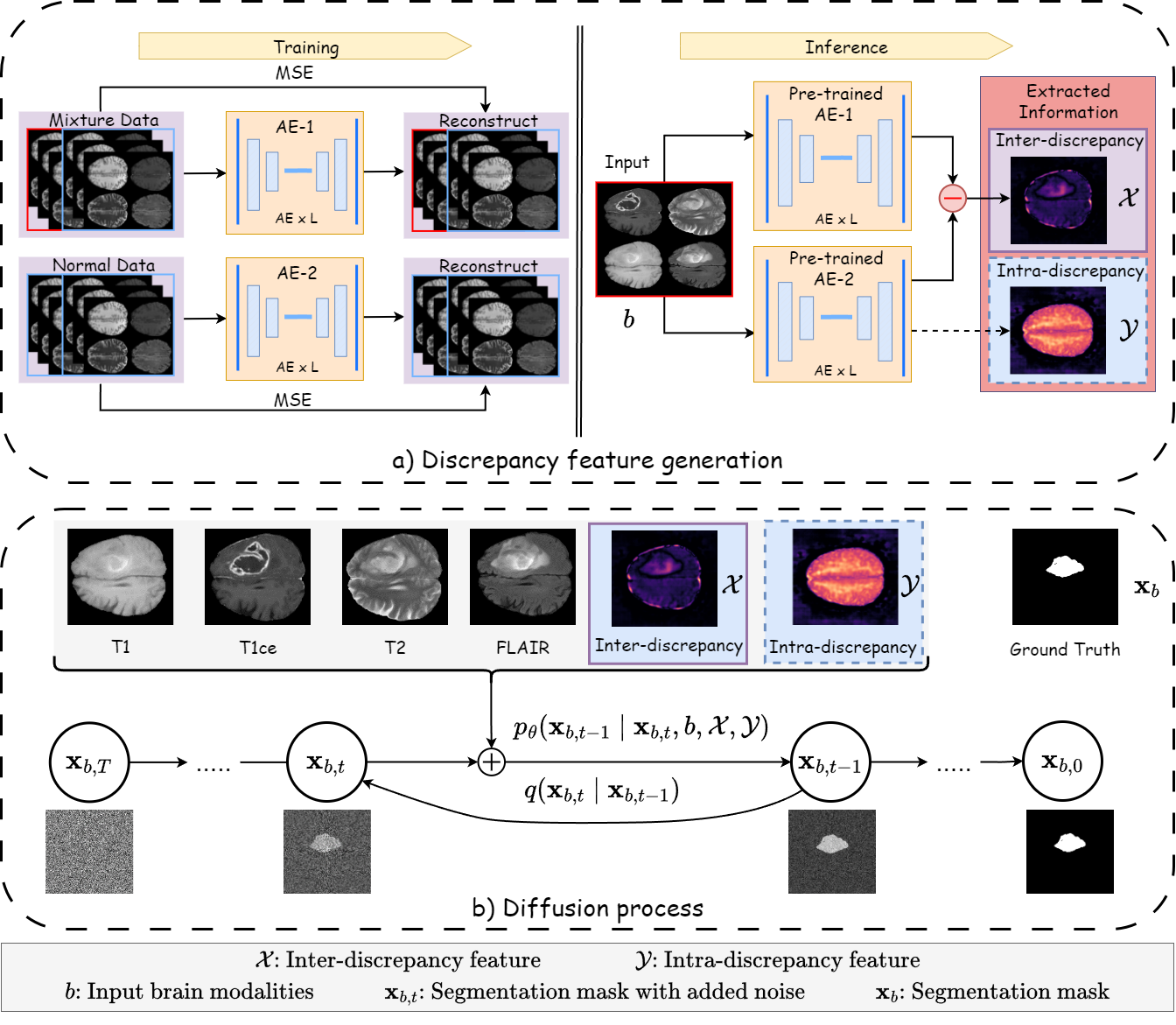
0
Discrepancy-based Diffusion Models for Lesion Detection in Brain MRI
Keqiang Fan, Xiaohao Cai, Mahesan Niranjan
Diffusion probabilistic models (DPMs) have exhibited significant effectiveness in computer vision tasks, particularly in image generation. However, their notable performance heavily relies on labelled datasets, which limits their application in medical images due to the associated high-cost annotations. Current DPM-related methods for lesion detection in medical imaging, which can be categorized into two distinct approaches, primarily rely on image-level annotations. The first approach, based on anomaly detection, involves learning reference healthy brain representations and identifying anomalies based on the difference in inference results. In contrast, the second approach, resembling a segmentation task, employs only the original brain multi-modalities as prior information for generating pixel-level annotations. In this paper, our proposed model - discrepancy distribution medical diffusion (DDMD) - for lesion detection in brain MRI introduces a novel framework by incorporating distinctive discrepancy features, deviating from the conventional direct reliance on image-level annotations or the original brain modalities. In our method, the inconsistency in image-level annotations is translated into distribution discrepancies among heterogeneous samples while preserving information within homogeneous samples. This property retains pixel-wise uncertainty and facilitates an implicit ensemble of segmentation, ultimately enhancing the overall detection performance. Thorough experiments conducted on the BRATS2020 benchmark dataset containing multimodal MRI scans for brain tumour detection demonstrate the great performance of our approach in comparison to state-of-the-art methods.
Read more5/9/2024