Enhancing Large Language Model-based Speech Recognition by Contextualization for Rare and Ambiguous Words

0

Sign in to get full access
Overview
- This paper explores a method to enhance large language model-based speech recognition for rare and ambiguous words.
- The approach involves using contextualization to improve performance on these challenging cases.
- The architecture combines an automatic speech recognition (ASR) model with a large language model to leverage both acoustic and linguistic information.
Plain English Explanation
The paper describes a way to improve speech recognition, particularly for words that are uncommon or have multiple possible meanings. Speech recognition models often struggle with these types of words, but the researchers developed a new approach to address this challenge.
Their method combines two key components: an automatic speech recognition (ASR) model that analyzes the audio signal, and a large language model that uses the surrounding context to understand the meaning of the words. By bringing these two elements together, the system can leverage both the acoustic information from the speech as well as the linguistic context to make more accurate predictions, especially for rare or ambiguous terms.
This type of contextual adaptation is important because speech often contains words that are difficult for traditional speech recognition to handle well. The language model helps provide additional cues to resolve these ambiguities and improve the overall accuracy of the transcription.
Technical Explanation
The core of the proposed architecture is the integration of an ASR model with a large language model. The ASR component takes the audio input and generates initial word predictions, while the language model is used to refine and contextualize these outputs.
Specifically, the system first generates n-best hypotheses from the ASR model. These are the top N most likely transcriptions of the input audio. The language model then scores each of these hypotheses based on the contextual coherence, allowing the system to identify the most plausible interpretation.
This joint modeling of audio and text enables the system to leverage both acoustic and linguistic information to improve performance, especially for rare or ambiguous words that may be difficult for a standalone ASR model to handle accurately.
The researchers evaluated their approach on several benchmark datasets and found consistent improvements over baseline ASR systems, particularly for the more challenging cases involving low-frequency vocabulary. The contextualization provided by the language model was key to these gains.
Critical Analysis
The paper presents a compelling approach to enhancing speech recognition through the integration of ASR and language modeling. The authors demonstrate the effectiveness of this method, particularly for rare and ambiguous words, which is an important practical challenge in speech recognition.
One potential limitation is the reliance on generating n-best hypotheses from the ASR model, which could be computationally expensive and may not scale well to very large vocabulary sizes. An area for further research could be exploring more efficient ways to integrate the language model, such as directly incorporating it into the ASR model architecture.
Additionally, the paper does not delve deeply into the specific types of rare or ambiguous words that benefit most from this contextualization approach. Understanding these linguistic patterns could help guide further refinements and optimizations of the system.
Overall, the work represents a valuable contribution to the field of speech recognition, showcasing how the integration of complementary models can lead to tangible performance improvements on challenging real-world tasks.
Conclusion
This paper presents a novel technique for enhancing large language model-based speech recognition by leveraging contextual information to improve performance on rare and ambiguous words. The key innovation is the integration of an ASR model with a powerful language model, allowing the system to jointly leverage acoustic and linguistic cues to make more accurate transcriptions.
The results demonstrate the effectiveness of this approach, particularly for handling the types of low-frequency vocabulary and contextual ambiguities that can be problematic for standalone ASR systems. While some refinements may be possible, this work represents an important step forward in advancing the state-of-the-art in speech recognition technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Large Language Model-based Speech Recognition by Contextualization for Rare and Ambiguous Words
Kento Nozawa, Takashi Masuko, Toru Taniguchi
We develop a large language model (LLM) based automatic speech recognition (ASR) system that can be contextualized by providing keywords as prior information in text prompts. We adopt decoder-only architecture and use our in-house LLM, PLaMo-100B, pre-trained from scratch using datasets dominated by Japanese and English texts as the decoder. We adopt a pre-trained Whisper encoder as an audio encoder, and the audio embeddings from the audio encoder are projected to the text embedding space by an adapter layer and concatenated with text embeddings converted from text prompts to form inputs to the decoder. By providing keywords as prior information in the text prompts, we can contextualize our LLM-based ASR system without modifying the model architecture to transcribe ambiguous words in the input audio accurately. Experimental results demonstrate that providing keywords to the decoder can significantly improve the recognition performance of rare and ambiguous words.
Read more8/16/2024
0
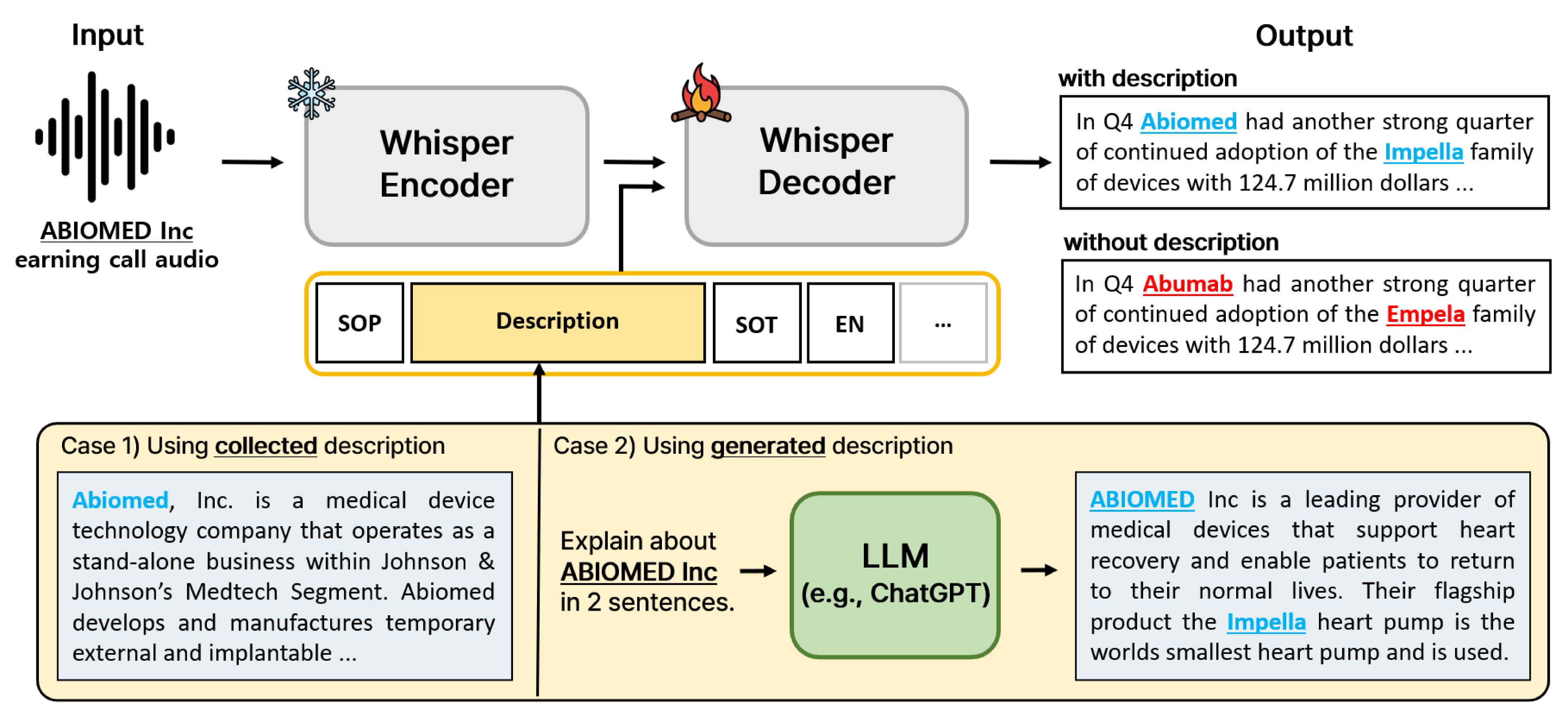
Improving Domain-Specific ASR with LLM-Generated Contextual Descriptions
Jiwon Suh, Injae Na, Woohwan Jung
End-to-end automatic speech recognition (E2E ASR) systems have significantly improved speech recognition through training on extensive datasets. Despite these advancements, they still struggle to accurately recognize domain specific words, such as proper nouns and technical terminologies. To address this problem, we propose a method to utilize the state-of-the-art Whisper without modifying its architecture, preserving its generalization performance while enabling it to leverage descriptions effectively. Moreover, we propose two additional training techniques to improve the domain specific ASR: decoder fine-tuning, and context perturbation. We also propose a method to use a Large Language Model (LLM) to generate descriptions with simple metadata, when descriptions are unavailable. Our experiments demonstrate that proposed methods notably enhance domain-specific ASR accuracy on real-life datasets, with LLM-generated descriptions outperforming human-crafted ones in effectiveness.
Read more7/26/2024

0
Keyword-Guided Adaptation of Automatic Speech Recognition
Aviv Shamsian, Aviv Navon, Neta Glazer, Gill Hetz, Joseph Keshet
Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
Read more6/6/2024

0
Improving Neural Biasing for Contextual Speech Recognition by Early Context Injection and Text Perturbation
Ruizhe Huang, Mahsa Yarmohammadi, Sanjeev Khudanpur, Daniel Povey
Existing research suggests that automatic speech recognition (ASR) models can benefit from additional contexts (e.g., contact lists, user specified vocabulary). Rare words and named entities can be better recognized with contexts. In this work, we propose two simple yet effective techniques to improve context-aware ASR models. First, we inject contexts into the encoders at an early stage instead of merely at their last layers. Second, to enforce the model to leverage the contexts during training, we perturb the reference transcription with alternative spellings so that the model learns to rely on the contexts to make correct predictions. On LibriSpeech, our techniques together reduce the rare word error rate by 60% and 25% relatively compared to no biasing and shallow fusion, making the new state-of-the-art performance. On SPGISpeech and a real-world dataset ConEC, our techniques also yield good improvements over the baselines.
Read more7/16/2024