Improving Domain-Specific ASR with LLM-Generated Contextual Descriptions

0
Sign in to get full access
Overview
- This paper presents a method to improve domain-specific automatic speech recognition (ASR) by generating contextual descriptions using large language models (LLMs).
- The approach aims to enhance the accuracy of ASR systems by providing relevant context to the models.
- The paper describes the architecture and experimental design, as well as the key insights and potential implications of the proposed method.
Plain English Explanation
Speech recognition systems can struggle to accurately transcribe speech, especially in specialized domains with technical terminology or unique contexts. This paper explores a way to improve the performance of these systems by using powerful language models to generate descriptions that provide relevant context.
The key idea is to take the audio input and use a large language model, like GPT, to generate a concise summary or description of the context. This contextual information is then fed back into the speech recognition model, helping it better understand the content and terminology being used. The authors tested this approach on several domain-specific speech datasets and found significant improvements in transcription accuracy compared to using the speech recognition model alone.
The benefit of this approach is that it leverages the capabilities of large language models, which are trained on vast amounts of text data, to supplement the information available to the speech recognition system. By providing this additional contextual "grounding," the speech recognition model is better equipped to handle the specialized vocabulary and nuanced language use that can occur in domain-specific conversations or presentations.
Technical Explanation
The paper introduces a method to improve the performance of domain-specific automatic speech recognition (ASR) systems by incorporating contextual information generated by large language models (LLMs).
The proposed architecture consists of two main components:
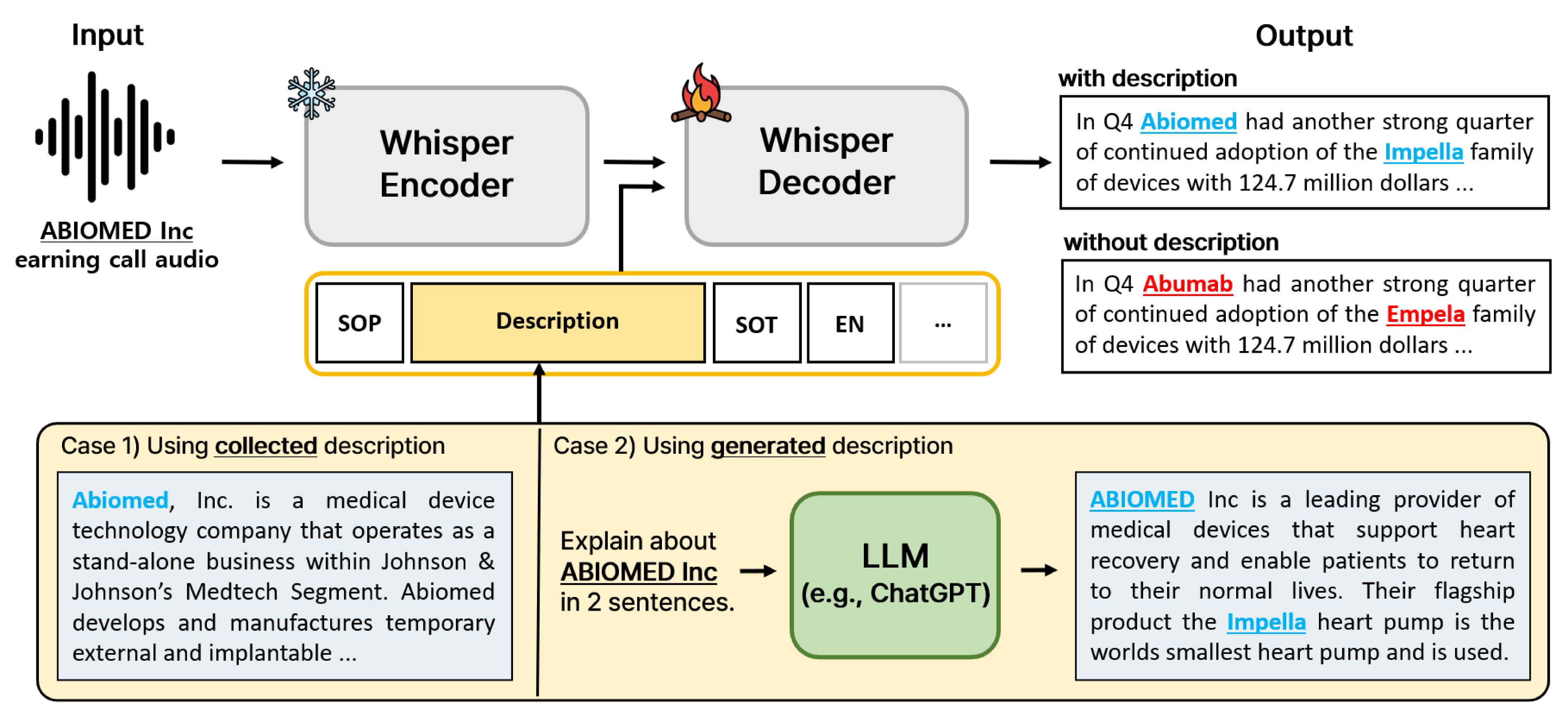
- LLM-based Contextual Description Generator: This module takes the audio input and generates a concise textual description of the context using a pre-trained LLM, such as GPT.
- ASR Model with Contextual Input: The ASR model receives the audio input as well as the contextual description generated by the LLM and uses this combined information to produce the final transcription.
The authors evaluate their approach on several domain-specific speech datasets, including medical, legal, and technical presentations. They compare the performance of the ASR model with and without the LLM-generated contextual descriptions, and find significant improvements in transcription accuracy across the different domains.
The key insight is that the LLM-generated contextual information helps the ASR model better understand the specialized vocabulary, technical concepts, and conversational patterns present in the domain-specific speech data. By providing this additional context, the ASR model can make more informed decisions during the transcription process, leading to more accurate results.
Critical Analysis
The paper presents a promising approach to enhancing the performance of domain-specific ASR systems, but it also acknowledges several limitations and areas for further research:
- The method relies on the availability of high-quality, domain-specific speech data for training the LLM-based contextual description generator. In practice, such data may not always be easily accessible.
- The paper does not explore the impact of potential errors or inaccuracies in the LLM-generated contextual descriptions on the overall ASR performance. Further research is needed to understand the robustness of the approach to such issues.
- The authors note that the proposed method may not be as effective for domains with highly specialized or technical language that is not well-covered in the LLM's training data. Exploring ways to address this limitation could be an area for future work.
- The paper focuses on improving transcription accuracy but does not discuss potential implications for downstream tasks, such as information extraction or task-oriented dialogue systems. Investigating these broader applications could be a valuable direction for further research.
Conclusion
This paper presents a novel approach to improving the performance of domain-specific automatic speech recognition systems by leveraging the contextual understanding capabilities of large language models. The key idea is to generate concise textual descriptions of the relevant context and feed this information back into the ASR model, helping it better handle specialized vocabulary and nuanced language use.
The experimental results demonstrate significant improvements in transcription accuracy across various domain-specific speech datasets, highlighting the potential of this approach to enhance the robustness and applicability of ASR systems in real-world, specialized settings. While the method has some limitations, the paper's insights and the proposed architecture offer a promising direction for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Domain-Specific ASR with LLM-Generated Contextual Descriptions
Jiwon Suh, Injae Na, Woohwan Jung
End-to-end automatic speech recognition (E2E ASR) systems have significantly improved speech recognition through training on extensive datasets. Despite these advancements, they still struggle to accurately recognize domain specific words, such as proper nouns and technical terminologies. To address this problem, we propose a method to utilize the state-of-the-art Whisper without modifying its architecture, preserving its generalization performance while enabling it to leverage descriptions effectively. Moreover, we propose two additional training techniques to improve the domain specific ASR: decoder fine-tuning, and context perturbation. We also propose a method to use a Large Language Model (LLM) to generate descriptions with simple metadata, when descriptions are unavailable. Our experiments demonstrate that proposed methods notably enhance domain-specific ASR accuracy on real-life datasets, with LLM-generated descriptions outperforming human-crafted ones in effectiveness.
Read more7/26/2024

0
Enhancing Large Language Model-based Speech Recognition by Contextualization for Rare and Ambiguous Words
Kento Nozawa, Takashi Masuko, Toru Taniguchi
We develop a large language model (LLM) based automatic speech recognition (ASR) system that can be contextualized by providing keywords as prior information in text prompts. We adopt decoder-only architecture and use our in-house LLM, PLaMo-100B, pre-trained from scratch using datasets dominated by Japanese and English texts as the decoder. We adopt a pre-trained Whisper encoder as an audio encoder, and the audio embeddings from the audio encoder are projected to the text embedding space by an adapter layer and concatenated with text embeddings converted from text prompts to form inputs to the decoder. By providing keywords as prior information in the text prompts, we can contextualize our LLM-based ASR system without modifying the model architecture to transcribe ambiguous words in the input audio accurately. Experimental results demonstrate that providing keywords to the decoder can significantly improve the recognition performance of rare and ambiguous words.
Read more8/16/2024

0
Keyword-Guided Adaptation of Automatic Speech Recognition
Aviv Shamsian, Aviv Navon, Neta Glazer, Gill Hetz, Joseph Keshet
Automatic Speech Recognition (ASR) technology has made significant progress in recent years, providing accurate transcription across various domains. However, some challenges remain, especially in noisy environments and specialized jargon. In this paper, we propose a novel approach for improved jargon word recognition by contextual biasing Whisper-based models. We employ a keyword spotting model that leverages the Whisper encoder representation to dynamically generate prompts for guiding the decoder during the transcription process. We introduce two approaches to effectively steer the decoder towards these prompts: KG-Whisper, which is aimed at fine-tuning the Whisper decoder, and KG-Whisper-PT, which learns a prompt prefix. Our results show a significant improvement in the recognition accuracy of specified keywords and in reducing the overall word error rates. Specifically, in unseen language generalization, we demonstrate an average WER improvement of 5.1% over Whisper.
Read more6/6/2024
0
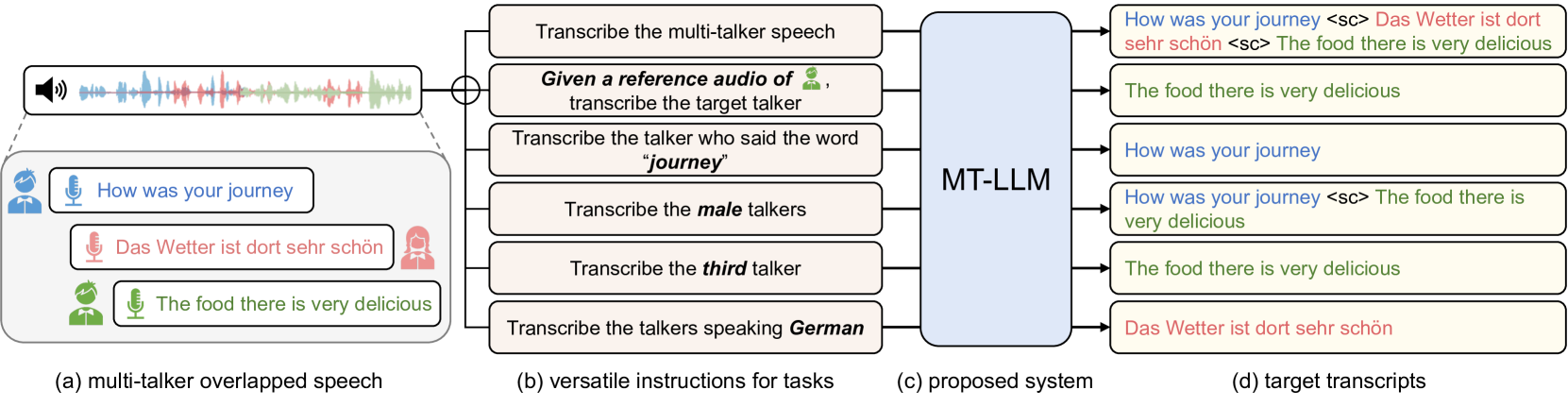
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024