Enhancing Large Language Model with Self-Controlled Memory Framework

1
💬
Sign in to get full access
Overview
- Large Language Models (LLMs) are powerful tools, but are limited by their inability to process lengthy inputs
- This paper proposes the Self-Controlled Memory (SCM) framework to enhance LLMs' long-term memory and recall
- SCM has three key components: an LLM-based agent, a memory stream, and a memory controller
- SCM can process ultra-long texts without modification or fine-tuning, integrating with any instruction-following LLM
Plain English Explanation
The paper addresses a key limitation of Large Language Models (LLMs) - their inability to process lengthy inputs. This results in the loss of critical historical information. To overcome this, the researchers propose the Self-Controlled Memory (SCM) framework.
SCM has three main components:
- LLM-based agent: The backbone of the framework, serving as the main language model.
- Memory stream: A storage system that keeps track of the agent's memories.
- Memory controller: Manages the memory stream, determining when and how to use the stored memories.
The key advantage of SCM is its ability to process ultra-long texts without any modifications or fine-tuning. This means it can be easily integrated with any instruction-following LLM in a "plug-and-play" fashion.
To evaluate the effectiveness of SCM, the researchers annotated a dataset covering three tasks: long-term dialogues, book summarization, and meeting summarization. The results show that SCM achieves better retrieval recall and generates more informative responses compared to other approaches.
Technical Explanation
The paper proposes the Self-Controlled Memory (SCM) framework to address the limitations of Large Language Models (LLMs) in processing lengthy inputs.
The SCM framework has three key components:
- LLM-based agent: The backbone of the framework, serving as the main language model.
- Memory stream: A storage system that keeps track of the agent's memories, allowing it to maintain long-term memory and recall relevant information.
- Memory controller: Manages the memory stream, determining when and how to utilize the stored memories to enhance the agent's performance.
The researchers annotated a dataset to evaluate the effectiveness of SCM. The dataset covers three tasks:
- Long-term dialogues: Assess the agent's ability to maintain context and recall relevant information over an extended conversation.
- Book summarization: Evaluate the agent's capacity to summarize lengthy texts, such as books.
- Meeting summarization: Examine the agent's performance in summarizing the key points from lengthy meeting transcripts.
The experimental results demonstrate that the proposed SCM framework achieves better retrieval recall and generates more informative responses compared to competitive baselines in the long-term dialogue task. This suggests that the SCM framework effectively leverages the stored memories to maintain context and provide more comprehensive responses.
Critical Analysis
The paper presents a promising approach to enhancing the long-term memory and recall capabilities of Large Language Models (LLMs) using the Self-Controlled Memory (SCM) framework.
One potential limitation of the research is the scope of the evaluation dataset. While the tasks covered (long-term dialogues, book summarization, and meeting summarization) are relevant, there may be other applications or scenarios where the SCM framework's performance could be further assessed.
Additionally, the paper does not delve into the specific architectural details or the training process of the SCM framework. Providing more information on these aspects could help researchers and practitioners better understand the inner workings of the system and potentially inspire further innovations.
Furthermore, the paper could have explored the scalability of the SCM framework, particularly in terms of its ability to handle increasingly longer inputs or maintain memory over extended periods. Investigating the computational and memory requirements of the system would also be valuable for understanding its practical limitations and potential areas for improvement.
Despite these minor limitations, the Self-Controlled Memory (SCM) framework presented in the paper represents a significant step forward in enhancing the long-term memory and recall capabilities of LLMs. The promising results suggest that the SCM framework could have a meaningful impact on various applications that require maintaining context and retrieving relevant information from lengthy inputs.
Conclusion
The paper introduces the Self-Controlled Memory (SCM) framework, which aims to address the limitations of Large Language Models (LLMs) in processing lengthy inputs. By integrating an LLM-based agent, a memory stream, and a memory controller, SCM demonstrates the ability to maintain long-term memory and recall relevant information more effectively.
The key strengths of the SCM framework are its plug-and-play compatibility with any instruction-following LLM and its performance in long-term dialogues, book summarization, and meeting summarization tasks. These capabilities suggest that the SCM framework could have a significant impact on applications that require maintaining context and retrieving relevant information from extensive textual inputs.
Overall, the Self-Controlled Memory (SCM) framework represents an important step forward in enhancing the long-term memory and recall capabilities of LLMs, with the potential to unlock new possibilities in natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
1
New!Enhancing Large Language Model with Self-Controlled Memory Framework
Bing Wang, Xinnian Liang, Jian Yang, Hui Huang, Shuangzhi Wu, Peihao Wu, Lu Lu, Zejun Ma, Zhoujun Li
Large Language Models (LLMs) are constrained by their inability to process lengthy inputs, resulting in the loss of critical historical information. To address this limitation, in this paper, we propose the Self-Controlled Memory (SCM) framework to enhance the ability of LLMs to maintain long-term memory and recall relevant information. Our SCM framework comprises three key components: an LLM-based agent serving as the backbone of the framework, a memory stream storing agent memories, and a memory controller updating memories and determining when and how to utilize memories from memory stream. Additionally, the proposed SCM is able to process ultra-long texts without any modification or fine-tuning, which can integrate with any instruction following LLMs in a plug-and-play paradigm. Furthermore, we annotate a dataset to evaluate the effectiveness of SCM for handling lengthy inputs. The annotated dataset covers three tasks: long-term dialogues, book summarization, and meeting summarization. Experimental results demonstrate that our method achieves better retrieval recall and generates more informative responses compared to competitive baselines in long-term dialogues. (https://github.com/wbbeyourself/SCM4LLMs)
Read more9/20/2024
💬
0
MEMORYLLM: Towards Self-Updatable Large Language Models
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, Julian McAuley
Existing Large Language Models (LLMs) usually remain static after deployment, which might make it hard to inject new knowledge into the model. We aim to build models containing a considerable portion of self-updatable parameters, enabling the model to integrate new knowledge effectively and efficiently. To this end, we introduce MEMORYLLM, a model that comprises a transformer and a fixed-size memory pool within the latent space of the transformer. MEMORYLLM can self-update with text knowledge and memorize the knowledge injected earlier. Our evaluations demonstrate the ability of MEMORYLLM to effectively incorporate new knowledge, as evidenced by its performance on model editing benchmarks. Meanwhile, the model exhibits long-term information retention capacity, which is validated through our custom-designed evaluations and long-context benchmarks. MEMORYLLM also shows operational integrity without any sign of performance degradation even after nearly a million memory updates. Our code and model are open-sourced at https://github.com/wangyu-ustc/MemoryLLM.
Read more5/28/2024
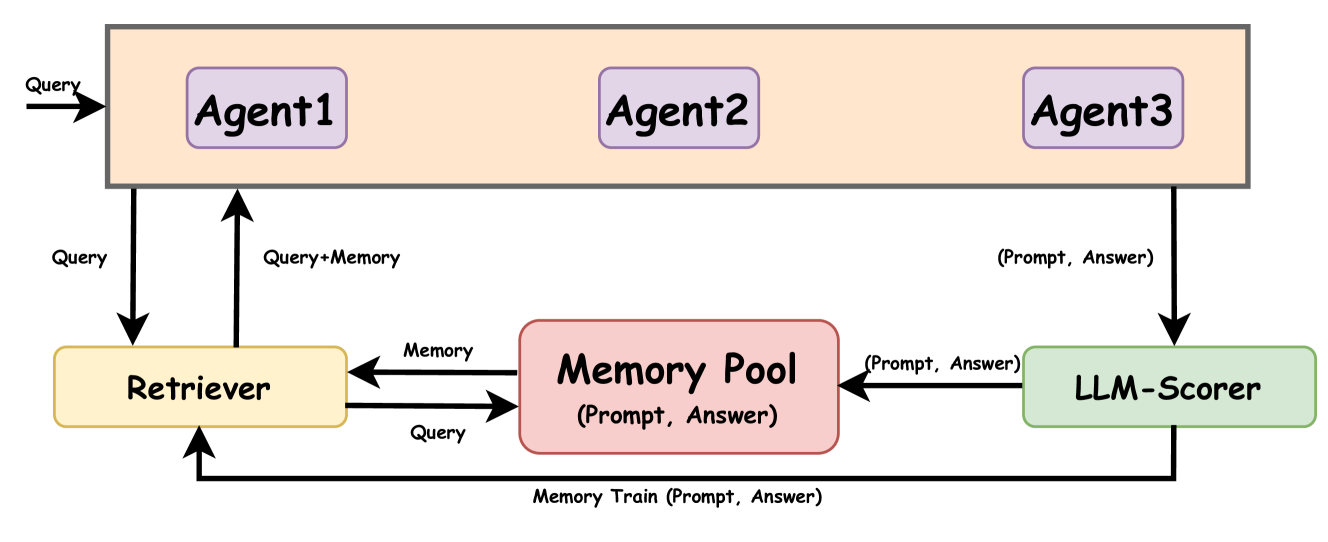
0
Memory Sharing for Large Language Model based Agents
Hang Gao, Yongfeng Zhang
The adaptation of Large Language Model (LLM)-based agents to execute tasks via natural language prompts represents a significant advancement, notably eliminating the need for explicit retraining or fine tuning, but are constrained by the comprehensiveness and diversity of the provided examples, leading to outputs that often diverge significantly from expected results, especially when it comes to the open-ended questions. This paper introduces the Memory Sharing, a framework which integrates the real-time memory filter, storage and retrieval to enhance the In-Context Learning process. This framework allows for the sharing of memories among multiple agents, whereby the interactions and shared memories between different agents effectively enhance the diversity of the memories. The collective self-enhancement through interactive learning among multiple agents facilitates the evolution from individual intelligence to collective intelligence. Besides, the dynamically growing memory pool is utilized not only to improve the quality of responses but also to train and enhance the retriever. We evaluated our framework across three distinct domains involving specialized tasks of agents. The experimental results demonstrate that the MS framework significantly improves the agents' performance in addressing open-ended questions.
Read more7/8/2024
💬
0
Empowering Working Memory for Large Language Model Agents
Jing Guo, Nan Li, Jianchuan Qi, Hang Yang, Ruiqiao Li, Yuzhen Feng, Si Zhang, Ming Xu
Large language models (LLMs) have achieved impressive linguistic capabilities. However, a key limitation persists in their lack of human-like memory faculties. LLMs exhibit constrained memory retention across sequential interactions, hindering complex reasoning. This paper explores the potential of applying cognitive psychology's working memory frameworks, to enhance LLM architecture. The limitations of traditional LLM memory designs are analyzed, including their isolation of distinct dialog episodes and lack of persistent memory links. To address this, an innovative model is proposed incorporating a centralized Working Memory Hub and Episodic Buffer access to retain memories across episodes. This architecture aims to provide greater continuity for nuanced contextual reasoning during intricate tasks and collaborative scenarios. While promising, further research is required into optimizing episodic memory encoding, storage, prioritization, retrieval, and security. Overall, this paper provides a strategic blueprint for developing LLM agents with more sophisticated, human-like memory capabilities, highlighting memory mechanisms as a vital frontier in artificial general intelligence.
Read more5/29/2024