Memory Sharing for Large Language Model based Agents
2404.09982
0
0
Abstract
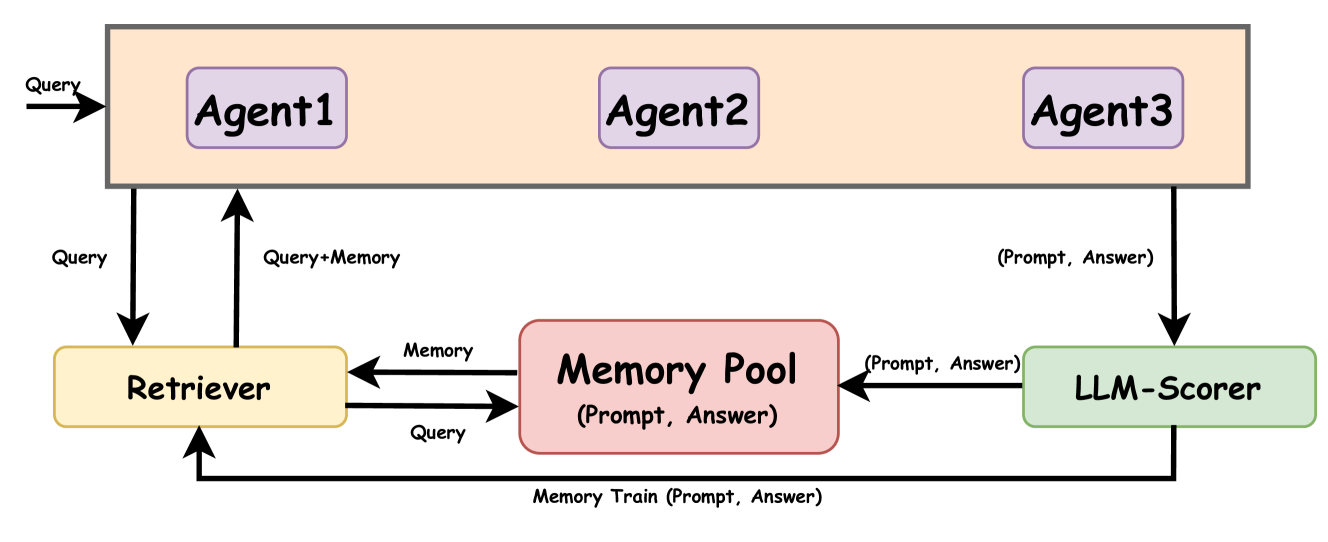
In the realm of artificial intelligence, the adaptation of Large Language Model (LLM)-based agents to execute tasks via natural language prompts represents a significant advancement, notably eliminating the need for explicit retraining or fine tuning for fixed-answer tasks such as common sense questions and yes/no queries. However, the application of In-context Learning to open-ended challenges, such as poetry creation, reveals substantial limitations due to the comprehensiveness of the provided examples and agent's ability to understand the content expressed in the problem, leading to outputs that often diverge significantly from expected results. Addressing this gap, our study introduces the Memory-Sharing (MS) framework for LLM multi-agents, which utilizes a real-time memory storage and retrieval system to enhance the In-context Learning process. Each memory within this system captures both the posed query and the corresponding real-time response from an LLM-based agent, aggregating these memories from a broad spectrum of similar agents to enrich the memory pool shared by all agents. This framework not only aids agents in identifying the most relevant examples for specific tasks but also evaluates the potential utility of their memories for future applications by other agents. Empirical validation across three distinct domains involving specialized functions of agents demonstrates that the MS framework significantly improve the agent's performance regrading the open-ended questions. Furthermore, we also discuss what type of memory pool and what retrieval strategy in MS can better help agents, offering a future develop direction of MS. The code and data are available at: https://github.com/GHupppp/MemorySharingLLM
Create account to get full access
Overview
- Explores a novel approach to enable large language model-based agents to share memory and experiences with each other
- Proposes a framework for memory sharing that allows agents to learn from and build upon each other's knowledge
- Demonstrates the potential of this approach to improve the performance and capabilities of AI agents in various domains
Plain English Explanation
The paper discusses a novel way for large language model-based AI agents to share memory and learn from each other's experiences. Traditional AI systems often operate in isolation, with each agent having its own limited set of knowledge and capabilities. The researchers behind this paper have developed a framework that allows these agents to pool their memories and insights, effectively creating a shared knowledge base that they can all draw from.
This memory sharing approach could be particularly useful in domains where AI agents need to collaborate or build upon each other's work, such as medical assistants or game agents. By giving agents the ability to learn from each other, the researchers hope to create more capable and adaptable AI systems that can tackle complex problems more effectively.
The key idea is to enable these agents to inject personalized memory into their language models, allowing them to build upon and refine their knowledge over time. This could lead to significant improvements in the agents' performance and the quality of their outputs, as they can draw on a broader range of experiences and insights.
Technical Explanation
The paper proposes a framework for enabling memory sharing among large language model-based agents. The core idea is to allow agents to inject personalized memory into their language models, which can then be shared with other agents to enhance their knowledge and capabilities.
The researchers describe a two-stage process for memory sharing. In the first stage, agents are trained on a base language model, which provides them with a foundation of general knowledge and skills. In the second stage, the agents are fine-tuned on specific tasks or domains, during which they can accumulate personalized memories and experiences.
These personalized memories are then encoded in a structured format and shared with other agents, who can incorporate them into their own language models. This memory injection process enables the agents to learn from each other's experiences and build upon their collective knowledge.
The researchers demonstrate the effectiveness of this approach through a series of experiments, showing that agents with access to shared memory perform better on a range of tasks compared to agents working in isolation. They also explore the scalability of their framework and discuss potential applications in domains such as medical assistance and game AI.
Critical Analysis
The paper presents a promising approach to enabling memory sharing among large language model-based agents, but it also acknowledges several key limitations and areas for further research.
One potential concern is the potential for "catastrophic forgetting," where agents may lose important knowledge or skills as they incorporate new memories from other agents. The researchers suggest that techniques like selective memory sharing and careful fine-tuning may help mitigate this issue, but more research is needed to fully understand and address this challenge.
Additionally, the paper does not explore the ethical implications of memory sharing, such as the potential for biases or inaccuracies to propagate through the shared knowledge base. As these AI systems become more sophisticated and widely deployed, it will be crucial to consider the societal impacts and ensure that they are developed and used responsibly.
Further research is also needed to understand the scalability and generalizability of the proposed framework. While the experiments demonstrate its effectiveness in specific scenarios, it remains to be seen how well it would perform in more complex, real-world applications involving large numbers of agents and diverse data sources.
Conclusion
The paper presents a novel approach to memory sharing among large language model-based agents, which has the potential to significantly enhance the capabilities and performance of AI systems in a wide range of domains. By enabling agents to learn from each other's experiences and build upon a collective knowledge base, the researchers aim to create more adaptable and effective AI agents that can tackle complex problems more efficiently.
While the proposed framework shows promising results, there are still several important challenges and limitations that need to be addressed through further research. As the development of large language models and multi-agent AI systems continues to advance, it will be crucial to consider the ethical and societal implications of these technologies and ensure that they are deployed in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on the Memory Mechanism of Large Language Model based Agents
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, Ji-Rong Wen
0
0
Large language model (LLM) based agents have recently attracted much attention from the research and industry communities. Compared with original LLMs, LLM-based agents are featured in their self-evolving capability, which is the basis for solving real-world problems that need long-term and complex agent-environment interactions. The key component to support agent-environment interactions is the memory of the agents. While previous studies have proposed many promising memory mechanisms, they are scattered in different papers, and there lacks a systematical review to summarize and compare these works from a holistic perspective, failing to abstract common and effective designing patterns for inspiring future studies. To bridge this gap, in this paper, we propose a comprehensive survey on the memory mechanism of LLM-based agents. In specific, we first discuss ''what is'' and ''why do we need'' the memory in LLM-based agents. Then, we systematically review previous studies on how to design and evaluate the memory module. In addition, we also present many agent applications, where the memory module plays an important role. At last, we analyze the limitations of existing work and show important future directions. To keep up with the latest advances in this field, we create a repository at url{https://github.com/nuster1128/LLM_Agent_Memory_Survey}.
4/23/2024
💬
Empowering Working Memory for Large Language Model Agents
Jing Guo, Nan Li, Jianchuan Qi, Hang Yang, Ruiqiao Li, Yuzhen Feng, Si Zhang, Ming Xu
0
0
Large language models (LLMs) have achieved impressive linguistic capabilities. However, a key limitation persists in their lack of human-like memory faculties. LLMs exhibit constrained memory retention across sequential interactions, hindering complex reasoning. This paper explores the potential of applying cognitive psychology's working memory frameworks, to enhance LLM architecture. The limitations of traditional LLM memory designs are analyzed, including their isolation of distinct dialog episodes and lack of persistent memory links. To address this, an innovative model is proposed incorporating a centralized Working Memory Hub and Episodic Buffer access to retain memories across episodes. This architecture aims to provide greater continuity for nuanced contextual reasoning during intricate tasks and collaborative scenarios. While promising, further research is required into optimizing episodic memory encoding, storage, prioritization, retrieval, and security. Overall, this paper provides a strategic blueprint for developing LLM agents with more sophisticated, human-like memory capabilities, highlighting memory mechanisms as a vital frontier in artificial general intelligence.
5/29/2024
💬
MEMORYLLM: Towards Self-Updatable Large Language Models
Yu Wang, Yifan Gao, Xiusi Chen, Haoming Jiang, Shiyang Li, Jingfeng Yang, Qingyu Yin, Zheng Li, Xian Li, Bing Yin, Jingbo Shang, Julian McAuley
0
0
Existing Large Language Models (LLMs) usually remain static after deployment, which might make it hard to inject new knowledge into the model. We aim to build models containing a considerable portion of self-updatable parameters, enabling the model to integrate new knowledge effectively and efficiently. To this end, we introduce MEMORYLLM, a model that comprises a transformer and a fixed-size memory pool within the latent space of the transformer. MEMORYLLM can self-update with text knowledge and memorize the knowledge injected earlier. Our evaluations demonstrate the ability of MEMORYLLM to effectively incorporate new knowledge, as evidenced by its performance on model editing benchmarks. Meanwhile, the model exhibits long-term information retention capacity, which is validated through our custom-designed evaluations and long-context benchmarks. MEMORYLLM also shows operational integrity without any sign of performance degradation even after nearly a million memory updates. Our code and model are open-sourced at https://github.com/wangyu-ustc/MemoryLLM.
5/28/2024

AI-native Memory: A Pathway from LLMs Towards AGI
Jingbo Shang, Zai Zheng, Xiang Ying, Felix Tao, Mindverse Team
0
0
Large language models (LLMs) have demonstrated the world with the sparks of artificial general intelligence (AGI). One opinion, especially from some startups working on LLMs, argues that an LLM with nearly unlimited context length can realize AGI. However, they might be too optimistic about the long-context capability of (existing) LLMs -- (1) Recent literature has shown that their effective context length is significantly smaller than their claimed context length; and (2) Our reasoning-in-a-haystack experiments further demonstrate that simultaneously finding the relevant information from a long context and conducting (simple) reasoning is nearly impossible. In this paper, we envision a pathway from LLMs to AGI through the integration of emph{memory}. We believe that AGI should be a system where LLMs serve as core processors. In addition to raw data, the memory in this system would store a large number of important conclusions derived from reasoning processes. Compared with retrieval-augmented generation (RAG) that merely processing raw data, this approach not only connects semantically related information closer, but also simplifies complex inferences at the time of querying. As an intermediate stage, the memory will likely be in the form of natural language descriptions, which can be directly consumed by users too. Ultimately, every agent/person should have its own large personal model, a deep neural network model (thus emph{AI-native}) that parameterizes and compresses all types of memory, even the ones cannot be described by natural languages. Finally, we discuss the significant potential of AI-native memory as the transformative infrastructure for (proactive) engagement, personalization, distribution, and social in the AGI era, as well as the incurred privacy and security challenges with preliminary solutions.
6/27/2024