Enhancing Multiview Synergy: Robust Learning by Exploiting the Wave Loss Function with Consensus and Complementarity Principles

0

Sign in to get full access
Overview
- Describes a novel loss function called the "Wave Loss Function" that exploits consensus and complementarity principles to enhance multiview learning
- Demonstrates improved robustness and performance over existing methods on various multiview learning tasks
- Introduces two key principles - Consensus and Complementarity - to guide the design of the Wave Loss Function
Plain English Explanation
The paper presents a new approach to multiview learning, which is the process of training machine learning models using data from multiple "views" or perspectives. The key innovation is a novel loss function called the "Wave Loss Function" that is designed to take advantage of two key principles:
-
Consensus: The model should aim to achieve consistent predictions across the different views of the data. This helps the model learn a more robust and generalizable representation.
-
Complementarity: The different views of the data should provide complementary information that the model can leverage to improve its overall performance.
By incorporating these Consensus and Complementarity principles into the loss function, the authors demonstrate that their Wave Loss Function leads to improved robustness and performance compared to existing multiview learning approaches, such as Adaptive Learning for Multi-View Stereo Reconstruction and RobustMVS: Single-Domain Generalized Deep Multi-View Stereo.
Technical Explanation
The key technical elements of the paper are:
-
Wave Loss Function: The authors propose a novel loss function that combines the Consensus and Complementarity principles. The Consensus term encourages the model to make consistent predictions across views, while the Complementarity term rewards the model for leveraging the unique information in each view to improve overall performance.
-
Multiview Learning Framework: The authors demonstrate the effectiveness of the Wave Loss Function within a multiview learning framework, where the model is trained on data from multiple views (e.g., different sensor modalities, camera angles, etc.).
-
Experiments: The authors evaluate their approach on a range of multiview learning tasks, including image classification, 3D reconstruction, and object detection. The results demonstrate the superior performance and robustness of the Wave Loss Function compared to existing multiview learning methods.
Critical Analysis
The paper presents a compelling approach to enhancing multiview learning, but there are a few potential limitations and areas for further research:
-
Computational Complexity: The Wave Loss Function may incur additional computational overhead compared to simpler loss functions, which could be a concern for real-time or resource-constrained applications.
-
Hyperparameter Sensitivity: The authors mention that the performance of the Wave Loss Function is sensitive to the choice of hyperparameters that control the relative importance of the Consensus and Complementarity terms. Developing more robust hyperparameter tuning strategies could be an area for future work.
-
Generalization to Other Domains: While the authors demonstrate the effectiveness of the Wave Loss Function on a range of multiview learning tasks, it would be valuable to explore its applicability to other domains, such as multimodal learning or domain adaptation.
Conclusion
The paper introduces a novel loss function, the Wave Loss Function, that exploits the Consensus and Complementarity principles to enhance the performance and robustness of multiview learning models. The authors demonstrate the effectiveness of their approach across a variety of tasks, and the proposed methodology has the potential to contribute to the ongoing advancements in the field of multiview learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Multiview Synergy: Robust Learning by Exploiting the Wave Loss Function with Consensus and Complementarity Principles
A. Quadir, Mushir Akhtar, M. Tanveer
Multiview learning (MvL) is an advancing domain in machine learning, leveraging multiple data perspectives to enhance model performance through view-consistency and view-discrepancy. Despite numerous successful multiview-based SVM models, existing frameworks predominantly focus on the consensus principle, often overlooking the complementarity principle. Furthermore, they exhibit limited robustness against noisy, error-prone, and view-inconsistent samples, prevalent in multiview datasets. To tackle the aforementioned limitations, this paper introduces Wave-MvSVM, a novel multiview support vector machine framework leveraging the wave loss (W-loss) function, specifically designed to harness both consensus and complementarity principles. Unlike traditional approaches that often overlook the complementary information among different views, the proposed Wave-MvSVM ensures a more comprehensive and resilient learning process by integrating both principles effectively. The W-loss function, characterized by its smoothness, asymmetry, and bounded nature, is particularly effective in mitigating the adverse effects of noisy and outlier data, thereby enhancing model stability. Theoretically, the W-loss function also exhibits a crucial classification-calibrated property, further boosting its effectiveness. Wave-MvSVM employs a between-view co-regularization term to enforce view consistency and utilizes an adaptive combination weight strategy to maximize the discriminative power of each view. The optimization problem is efficiently solved using a combination of GD and the ADMM, ensuring reliable convergence to optimal solutions. Theoretical analyses, grounded in Rademacher complexity, validate the generalization capabilities of the Wave-MvSVM model. Extensive empirical evaluations across diverse datasets demonstrate the superior performance of Wave-MvSVM in comparison to existing benchmark models.
Read more8/14/2024
👨🏫
0
Advancing Supervised Learning with the Wave Loss Function: A Robust and Smooth Approach
Mushir Akhtar, M. Tanveer, Mohd. Arshad
Loss function plays a vital role in supervised learning frameworks. The selection of the appropriate loss function holds the potential to have a substantial impact on the proficiency attained by the acquired model. The training of supervised learning algorithms inherently adheres to predetermined loss functions during the optimization process. In this paper, we present a novel contribution to the realm of supervised machine learning: an asymmetric loss function named wave loss. It exhibits robustness against outliers, insensitivity to noise, boundedness, and a crucial smoothness property. Theoretically, we establish that the proposed wave loss function manifests the essential characteristic of being classification-calibrated. Leveraging this breakthrough, we incorporate the proposed wave loss function into the least squares setting of support vector machines (SVM) and twin support vector machines (TSVM), resulting in two robust and smooth models termed Wave-SVM and Wave-TSVM, respectively. To address the optimization problem inherent in Wave-SVM, we utilize the adaptive moment estimation (Adam) algorithm. It is noteworthy that this paper marks the first instance of the Adam algorithm application to solve an SVM model. Further, we devise an iterative algorithm to solve the optimization problems of Wave-TSVM. To empirically showcase the effectiveness of the proposed Wave-SVM and Wave-TSVM, we evaluate them on benchmark UCI and KEEL datasets (with and without feature noise) from diverse domains. Moreover, to exemplify the applicability of Wave-SVM in the biomedical domain, we evaluate it on the Alzheimer Disease Neuroimaging Initiative (ADNI) dataset. The experimental outcomes unequivocally reveal the prowess of Wave-SVM and Wave-TSVM in achieving superior prediction accuracy against the baseline models.
Read more4/30/2024

0
Multiview learning with twin parametric margin SVM
A. Quadir, M. Tanveer
Multiview learning (MVL) seeks to leverage the benefits of diverse perspectives to complement each other, effectively extracting and utilizing the latent information within the dataset. Several twin support vector machine-based MVL (MvTSVM) models have been introduced and demonstrated outstanding performance in various learning tasks. However, MvTSVM-based models face significant challenges in the form of computational complexity due to four matrix inversions, the need to reformulate optimization problems in order to employ kernel-generated surfaces for handling non-linear cases, and the constraint of uniform noise assumption in the training data. Particularly in cases where the data possesses a heteroscedastic error structure, these challenges become even more pronounced. In view of the aforementioned challenges, we propose multiview twin parametric margin support vector machine (MvTPMSVM). MvTPMSVM constructs parametric margin hyperplanes corresponding to both classes, aiming to regulate and manage the impact of the heteroscedastic noise structure existing within the data. The proposed MvTPMSVM model avoids the explicit computation of matrix inversions in the dual formulation, leading to enhanced computational efficiency. We perform an extensive assessment of the MvTPMSVM model using benchmark datasets such as UCI, KEEL, synthetic, and Animals with Attributes (AwA). Our experimental results, coupled with rigorous statistical analyses, confirm the superior generalization capabilities of the proposed MvTPMSVM model compared to the baseline models. The source code of the proposed MvTPMSVM model is available at url{https://github.com/mtanveer1/MvTPMSVM}.
Read more8/13/2024
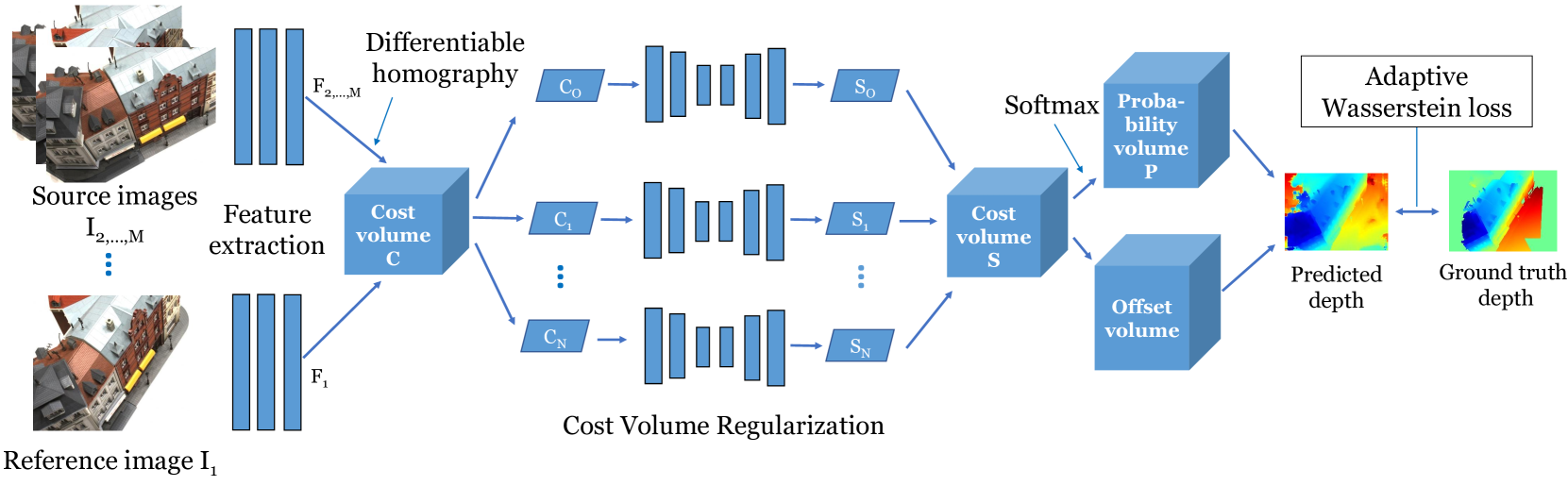
0
Adaptive Learning for Multi-view Stereo Reconstruction
Qinglu Min, Jie Zhao, Zhihao Zhang, Chen Min
Deep learning has recently demonstrated its excellent performance on the task of multi-view stereo (MVS). However, loss functions applied for deep MVS are rarely studied. In this paper, we first analyze existing loss functions' properties for deep depth based MVS approaches. Regression based loss leads to inaccurate continuous results by computing mathematical expectation, while classification based loss outputs discretized depth values. To this end, we then propose a novel loss function, named adaptive Wasserstein loss, which is able to narrow down the difference between the true and predicted probability distributions of depth. Besides, a simple but effective offset module is introduced to better achieve sub-pixel prediction accuracy. Extensive experiments on different benchmarks, including DTU, Tanks and Temples and BlendedMVS, show that the proposed method with the adaptive Wasserstein loss and the offset module achieves state-of-the-art performance.
Read more4/9/2024