Enhancing One-shot Pruned Pre-trained Language Models through Sparse-Dense-Sparse Mechanism

0

Sign in to get full access
Overview
- The paper proposes a novel "Sparse-Dense-Sparse" mechanism to enhance one-shot pruned pre-trained language models.
- The approach aims to improve the performance of highly pruned language models by alternating between sparse and dense training phases.
- The authors demonstrate the effectiveness of their method on various language tasks, showing improved performance compared to standard one-shot pruning techniques.
Plain English Explanation
The researchers have developed a new technique called "Sparse-Dense-Sparse" to improve the performance of pre-trained language models that have been heavily compressed (or "pruned") to make them smaller and more efficient.
The key idea is to go through a cycle of three phases:
- Sparse: The model starts in a highly pruned, sparse state, where many of the connections between its neurons have been removed.
- Dense: The model is then trained in a dense state, where all the connections are restored, allowing the model to learn new information.
- Sparse: Finally, the model is pruned again, returning to a sparse state, but retaining the knowledge gained during the dense training phase.
By alternating between these sparse and dense states, the researchers found that the model could achieve better performance compared to standard one-shot pruning approaches, where the model is pruned only once. The Sparse-Dense-Sparse mechanism helps the model learn more efficiently and maintain its accuracy even after significant compression.
Technical Explanation
The paper introduces a novel "Sparse-Dense-Sparse" (SDS) framework for enhancing the performance of one-shot pruned pre-trained language models. The key elements of the approach are:
- Sparse Initialization: The pre-trained language model is first pruned using a one-shot pruning technique, resulting in a sparse, compressed model.
- Dense Training: The sparse model is then trained in a dense state, where all the connections are restored, allowing the model to learn new information and refine its knowledge.
- Sparse Fine-tuning: Finally, the model is pruned again, returning to a sparse state, but retaining the improvements gained during the dense training phase.
The authors demonstrate the effectiveness of the SDS framework on various language tasks, including text classification, natural language inference, and question answering. They show that the SDS-enhanced models outperform standard one-shot pruned models, achieving better performance while maintaining a high level of compression.
Critical Analysis
The paper presents a compelling approach to improving the performance of highly pruned pre-trained language models. The Sparse-Dense-Sparse mechanism addresses a key limitation of one-shot pruning, where the model's accuracy can suffer significantly after aggressive compression.
One potential caveat is that the additional training phases required by the SDS framework may increase the overall computational cost and training time compared to standard one-shot pruning. The authors do not provide a detailed analysis of the computational overhead, which could be an important consideration for real-world deployment.
Additionally, the paper does not extensively explore the impact of different pruning strategies or the initial pruning ratio on the final performance of the SDS-enhanced models. Further research in these areas could provide valuable insights and help refine the technique.
Conclusion
The Sparse-Dense-Sparse framework proposed in this paper offers a promising approach to enhancing the performance of one-shot pruned pre-trained language models. By alternating between sparse and dense training phases, the technique allows the model to maintain its accuracy while achieving a high level of compression, which is crucial for deploying these models in resource-constrained environments.
The findings of this research could have significant implications for the development of efficient and high-performing language models, potentially enabling their widespread adoption in a variety of applications, from chatbots and virtual assistants to text summarization and machine translation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing One-shot Pruned Pre-trained Language Models through Sparse-Dense-Sparse Mechanism
Guanchen Li, Xiandong Zhao, Lian Liu, Zeping Li, Dong Li, Lu Tian, Jie He, Ashish Sirasao, Emad Barsoum
Pre-trained language models (PLMs) are engineered to be robust in contextual understanding and exhibit outstanding performance in various natural language processing tasks. However, their considerable size incurs significant computational and storage costs. Modern pruning strategies employ one-shot techniques to compress PLMs without the need for retraining on task-specific or otherwise general data; however, these approaches often lead to an indispensable reduction in performance. In this paper, we propose SDS, a Sparse-Dense-Sparse pruning framework to enhance the performance of the pruned PLMs from a weight distribution optimization perspective. We outline the pruning process in three steps. Initially, we prune less critical connections in the model using conventional one-shot pruning methods. Next, we reconstruct a dense model featuring a pruning-friendly weight distribution by reactivating pruned connections with sparse regularization. Finally, we perform a second pruning round, yielding a superior pruned model compared to the initial pruning. Experimental results demonstrate that SDS outperforms the state-of-the-art pruning techniques SparseGPT and Wanda under an identical sparsity configuration. For instance, SDS reduces perplexity by 9.13 on Raw-Wikitext2 and improves accuracy by an average of 2.05% across multiple zero-shot benchmarks for OPT-125M with 2:4 sparsity.
Read more8/21/2024
0
SparseLLM: Towards Global Pruning for Pre-trained Language Models
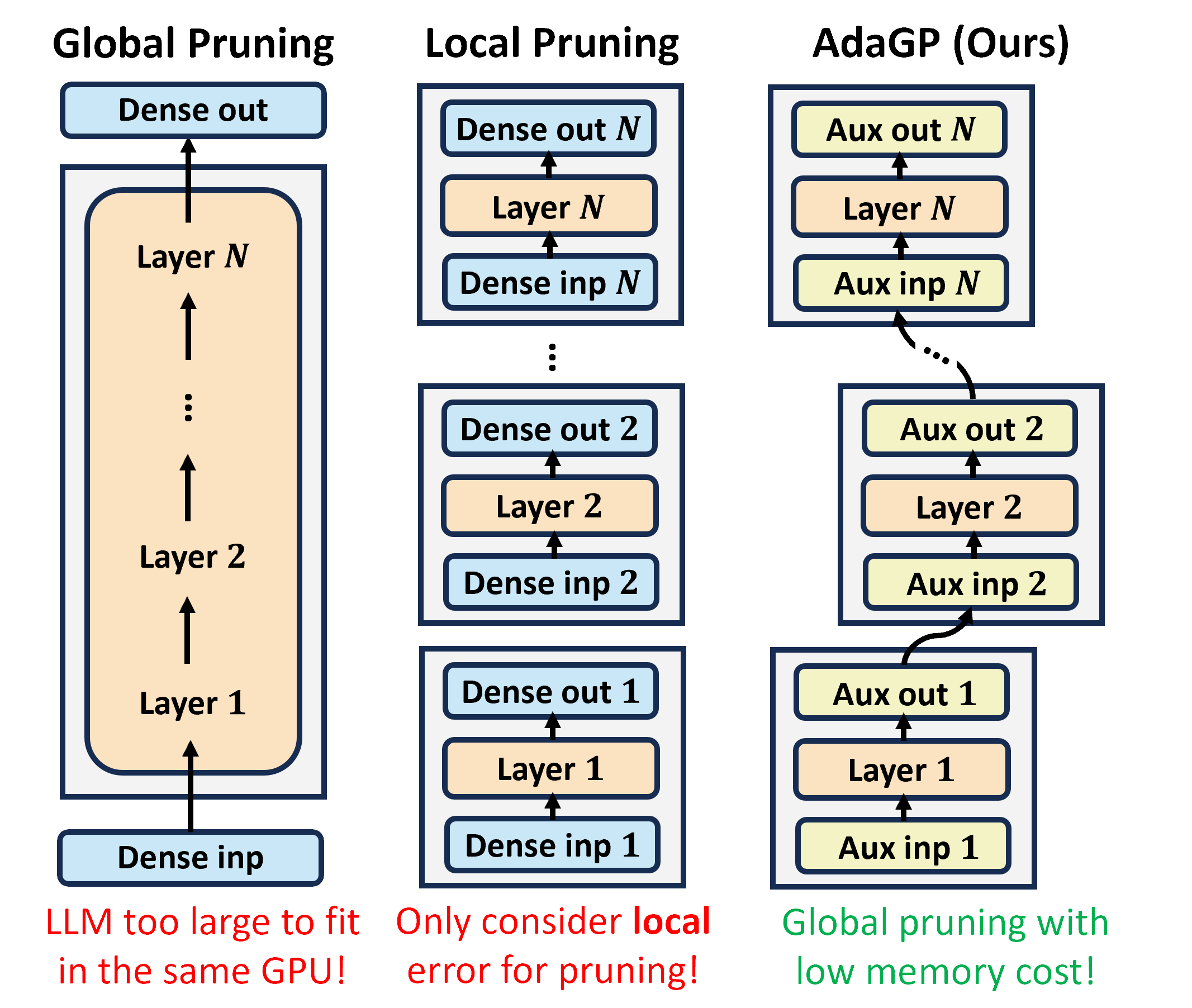
Guangji Bai, Yijiang Li, Chen Ling, Kibaek Kim, Liang Zhao
The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose SparseLLM, a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. SparseLLM's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
Read more5/27/2024
💬
0
One-Shot Sensitivity-Aware Mixed Sparsity Pruning for Large Language Models
Hang Shao, Bei Liu, Bo Xiao, Ke Zeng, Guanglu Wan, Yanmin Qian
Various Large Language Models~(LLMs) from the Generative Pretrained Transformer(GPT) family have achieved outstanding performances in a wide range of text generation tasks. However, the enormous model sizes have hindered their practical use in real-world applications due to high inference latency. Therefore, improving the efficiencies of LLMs through quantization, pruning, and other means has been a key issue in LLM studies. In this work, we propose a method based on Hessian sensitivity-aware mixed sparsity pruning to prune LLMs to at least 50% sparsity without the need of any retraining. It allocates sparsity adaptively based on sensitivity, allowing us to reduce pruning-induced error while maintaining the overall sparsity level. The advantages of the proposed method exhibit even more when the sparsity is extremely high. Furthermore, our method is compatible with quantization, enabling further compression of LLMs. We have released the available code.
Read more4/24/2024
🛠️
0
ALPS: Improved Optimization for Highly Sparse One-Shot Pruning for Large Language Models
Xiang Meng, Kayhan Behdin, Haoyue Wang, Rahul Mazumder
The impressive performance of Large Language Models (LLMs) across various natural language processing tasks comes at the cost of vast computational resources and storage requirements. One-shot pruning techniques offer a way to alleviate these burdens by removing redundant weights without the need for retraining. Yet, the massive scale of LLMs often forces current pruning approaches to rely on heuristics instead of optimization-based techniques, potentially resulting in suboptimal compression. In this paper, we introduce ALPS, an optimization-based framework that tackles the pruning problem using the operator splitting technique and a preconditioned conjugate gradient-based post-processing step. Our approach incorporates novel techniques to accelerate and theoretically guarantee convergence while leveraging vectorization and GPU parallelism for efficiency. ALPS substantially outperforms state-of-the-art methods in terms of the pruning objective and perplexity reduction, particularly for highly sparse models. On the OPT-30B model with 70% sparsity, ALPS achieves a 13% reduction in test perplexity on the WikiText dataset and a 19% improvement in zero-shot benchmark performance compared to existing methods.
Read more6/13/2024