SparseLLM: Towards Global Pruning for Pre-trained Language Models
2402.17946
0
0
Abstract
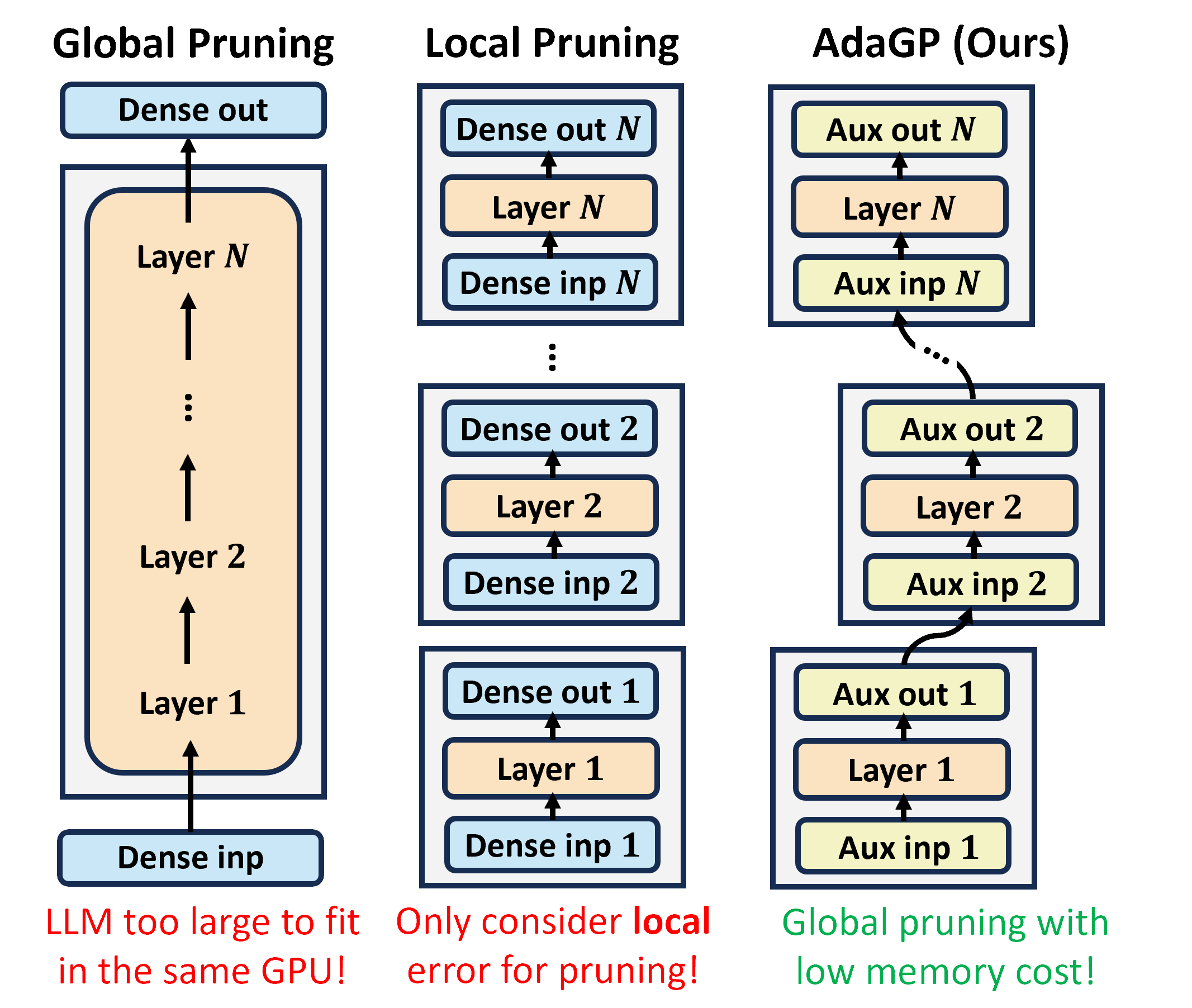
The transformative impact of large language models (LLMs) like LLaMA and GPT on natural language processing is countered by their prohibitive computational demands. Pruning has emerged as a pivotal compression strategy, introducing sparsity to enhance both memory and computational efficiency. Yet, traditional global pruning is impractical for LLMs due to scalability issues, while local pruning, despite its efficiency, leads to suboptimal solutions. Addressing these challenges, we propose SparseLLM, a novel framework that redefines the global pruning process into manageable, coordinated subproblems, allowing for resource-efficient optimization with global optimality. SparseLLM's approach, which conceptualizes LLMs as a chain of modular functions and leverages auxiliary variables for problem decomposition, not only facilitates a pragmatic application on LLMs but also demonstrates significant performance improvements, particularly in high-sparsity regimes where it surpasses current state-of-the-art methods.
Create account to get full access
Overview
- This paper presents a novel gradient-free pruning method for pre-trained language models that adaptively prunes model parameters to achieve high sparsity without significant performance degradation.
- The proposed approach, called Gradient-Free Adaptive Global Pruning (GFAGP), leverages a combination of gradient-free sensitivity analysis and adaptive global pruning to identify and remove less important model parameters.
- GFAGP aims to address the limitations of existing pruning techniques, which often struggle to maintain model performance at high sparsity levels or require costly gradient computations.
Plain English Explanation
The paper describes a new way to make pre-trained language models more efficient by selectively removing parts of the model that aren't contributing much to its performance. This is called "pruning," and the key innovation here is that it's done without needing to calculate the gradients of the model, which can be computationally expensive.
Instead, the method uses a "gradient-free" approach to figure out which parts of the model are less important and can be safely removed. It then adaptively prunes the model, gradually removing more and more parameters while carefully monitoring the model's performance to ensure it doesn't degrade too much.
The goal is to achieve high levels of sparsity (i.e., a lot of the model's parameters are removed) without significantly impacting the model's accuracy or capabilities. This can make the model much more efficient and easier to deploy, especially on resource-constrained devices.
Technical Explanation
The paper introduces a Gradient-Free Adaptive Global Pruning (GFAGP) method for pre-trained language models. GFAGP combines gradient-free sensitivity analysis and adaptive global pruning to identify and remove less important model parameters.
The gradient-free sensitivity analysis is based on the Beyond Size: How Gradients Shape Pruning Decisions approach, which uses a proxy for gradients to estimate the importance of individual parameters without actually computing the gradients.
The adaptive global pruning component of GFAGP builds on techniques like Enabling High Sparsity in Foundational LLAMA Models for Efficient Deployment and Sheared LLAMA: Accelerating Language Model Pre-Training, iteratively pruning the model while monitoring its performance to maintain accuracy at high sparsity levels.
The authors also compare GFAGP to other pruning techniques like One-Shot Sensitivity-Aware Mixed Sparsity Pruning and Efficient Pruning of Large Language Models with Adaptive Estimation, demonstrating GFAGP's advantages in terms of achieving high sparsity without significant accuracy degradation.
Critical Analysis
The paper presents a promising approach to pruning pre-trained language models, but it's important to consider some potential caveats and limitations:
- The authors only evaluate GFAGP on a few specific language models and tasks, so its generalizability to a wider range of models and applications remains to be seen.
- The gradient-free sensitivity analysis used in GFAGP may not capture all the nuances of a model's importance, and there could be room for further refinement of the sensitivity estimation.
- The adaptive pruning component of GFAGP relies on monitoring the model's performance during pruning, which could be computationally expensive, especially for larger models.
Additionally, while the paper does a good job of situating GFAGP within the broader context of language model pruning research, it would be interesting to see further exploration of how GFAGP compares to other emerging techniques in areas like efficient pruning and mixed sparsity.
Conclusion
The Gradient-Free Adaptive Global Pruning (GFAGP) method presented in this paper offers a promising approach to improving the efficiency of pre-trained language models. By leveraging gradient-free sensitivity analysis and adaptive pruning, GFAGP can achieve high levels of model sparsity without significant performance degradation.
This work has the potential to contribute to the ongoing efforts to develop more efficient and deployable language models, particularly for resource-constrained environments. As the field of language model optimization continues to evolve, techniques like GFAGP may play an important role in balancing model performance, size, and computational requirements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models
Rocktim Jyoti Das, Mingjie Sun, Liqun Ma, Zhiqiang Shen
0
0
Large Language Models (LLMs) with billions of parameters are prime targets for network pruning, removing some model weights without hurting performance. Prior approaches such as magnitude pruning, SparseGPT, and Wanda, either concentrated solely on weights or integrated weights with activations for sparsity. However, they overlooked the informative gradients derived from pretrained LLMs. In this paper, we present a novel sparsity-centric pruning method for pretrained LLMs, termed Gradient-based Language Model Pruner (GBLM-Pruner). GBLM-Pruner leverages the first-order term of the Taylor expansion, operating in a training-free manner by harnessing properly normalized gradients from a few calibration samples to determine the pruning metric, and substantially outperforms competitive counterparts like SparseGPT and Wanda in multiple benchmarks. Intriguingly, by incorporating gradients, unstructured pruning with our method tends to reveal some structural patterns, which mirrors the geometric interdependence inherent in the LLMs' parameter structure. Additionally, GBLM-Pruner functions without any subsequent retraining or weight updates to maintain its simplicity as other counterparts. Extensive evaluations on LLaMA-1 and LLaMA-2 across various benchmarks show that GBLM-Pruner surpasses magnitude pruning, Wanda and SparseGPT by significant margins. We further extend our approach on Vision Transformer. Our code and models are available at https://github.com/VILA-Lab/GBLM-Pruner.
4/10/2024
❗
Enabling High-Sparsity Foundational Llama Models with Efficient Pretraining and Deployment
Abhinav Agarwalla, Abhay Gupta, Alexandre Marques, Shubhra Pandit, Michael Goin, Eldar Kurtic, Kevin Leong, Tuan Nguyen, Mahmoud Salem, Dan Alistarh, Sean Lie, Mark Kurtz
0
0
Large language models (LLMs) have revolutionized Natural Language Processing (NLP), but their size creates computational bottlenecks. We introduce a novel approach to create accurate, sparse foundational versions of performant LLMs that achieve full accuracy recovery for fine-tuning tasks at up to 70% sparsity. We achieve this for the LLaMA-2 7B model by combining the SparseGPT one-shot pruning method and sparse pretraining of those models on a subset of the SlimPajama dataset mixed with a Python subset of The Stack dataset. We exhibit training acceleration due to sparsity on Cerebras CS-3 chips that closely matches theoretical scaling. In addition, we establish inference acceleration of up to 3x on CPUs by utilizing Neural Magic's DeepSparse engine and 1.7x on GPUs through Neural Magic's nm-vllm engine. The above gains are realized via sparsity alone, thus enabling further gains through additional use of quantization. Specifically, we show a total speedup on CPUs for sparse-quantized LLaMA models of up to 8.6x. We demonstrate these results across diverse, challenging tasks, including chat, instruction following, code generation, arithmetic reasoning, and summarization to prove their generality. This work paves the way for rapidly creating smaller and faster LLMs without sacrificing accuracy.
5/7/2024

Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
0
0
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
6/18/2024
🛠️
ALPS: Improved Optimization for Highly Sparse One-Shot Pruning for Large Language Models
Xiang Meng, Kayhan Behdin, Haoyue Wang, Rahul Mazumder
0
0
The impressive performance of Large Language Models (LLMs) across various natural language processing tasks comes at the cost of vast computational resources and storage requirements. One-shot pruning techniques offer a way to alleviate these burdens by removing redundant weights without the need for retraining. Yet, the massive scale of LLMs often forces current pruning approaches to rely on heuristics instead of optimization-based techniques, potentially resulting in suboptimal compression. In this paper, we introduce ALPS, an optimization-based framework that tackles the pruning problem using the operator splitting technique and a preconditioned conjugate gradient-based post-processing step. Our approach incorporates novel techniques to accelerate and theoretically guarantee convergence while leveraging vectorization and GPU parallelism for efficiency. ALPS substantially outperforms state-of-the-art methods in terms of the pruning objective and perplexity reduction, particularly for highly sparse models. On the OPT-30B model with 70% sparsity, ALPS achieves a 13% reduction in test perplexity on the WikiText dataset and a 19% improvement in zero-shot benchmark performance compared to existing methods.
6/13/2024