Enhancing Traffic Incident Management with Large Language Models: A Hybrid Machine Learning Approach for Severity Classification

0

Sign in to get full access
Overview
- This paper explores the use of large language models (LLMs) to classify the severity of traffic incidents for improved traffic management.
- The researchers developed a machine learning approach that integrates LLMs to analyze incident reports and predict incident severity levels.
- The goal is to enable more efficient and effective traffic incident response and mitigation.
Plain English Explanation
The paper describes a new way to use powerful AI language models to help manage traffic incidents more effectively. Traffic incidents like accidents or road closures can cause big delays and problems, so it's important for transportation agencies to respond quickly and appropriately.
The researchers developed a machine learning system that uses large language models - AI systems trained on massive amounts of text data - to analyze reports about traffic incidents. The system can then predict how serious or severe each incident is likely to be. This severity classification can help transportation managers decide the best way to respond, whether that's sending emergency crews, rerouting traffic, or other actions.
By integrating these advanced language models, the researchers aim to create a more automated and accurate way to assess traffic incidents in real-time. This could lead to faster response times, better resource allocation, and ultimately reduced congestion and delays for drivers. The core idea is to leverage the impressive text understanding capabilities of LLMs to enhance traffic incident management systems.
Technical Explanation
The paper presents a machine learning approach for integrating large language models (LLMs) to classify the severity of traffic incidents. The researchers developed a system that takes incident reports as input and predicts the severity level using an LLM-based classification model.
The system architecture includes several key components:
- Data preprocessing: Incident reports are collected and cleaned, with features like location, time, and textual descriptions extracted.
- LLM integration: A large pre-trained language model, such as BERT or GPT, is fine-tuned on the incident report data to learn patterns and extract relevant features.
- Severity classification: The LLM-derived features are used as input to a machine learning classifier (e.g., logistic regression, random forest) that predicts the incident severity level.
The researchers evaluated their approach on a real-world dataset of traffic incident reports. Their results demonstrate that the LLM-based system outperforms traditional text classification methods, highlighting the value of integrating advanced language understanding capabilities for this task.
Critical Analysis
The paper presents a compelling approach for leveraging LLMs to enhance traffic incident management systems. However, there are a few potential limitations and areas for further research:
- The dataset used for training and evaluation may not be representative of all types of traffic incidents. The researchers should consider expanding the dataset to capture a wider range of incident scenarios.
- The paper does not provide detailed analysis of the LLM's internal decision-making process. Further work is needed to understand how the language model is extracting and combining features to make severity predictions.
- The proposed system relies on textual incident reports as input. Incorporating additional data sources, such as sensor data or video footage, could potentially improve the accuracy and robustness of the severity classification.
Overall, the research demonstrates the potential of LLMs for enhancing traffic incident management and warrants further exploration in this domain.
Conclusion
This paper presents a novel approach for integrating large language models to classify the severity of traffic incidents. By leveraging the advanced text understanding capabilities of LLMs, the researchers have developed a machine learning system that can more accurately predict incident severity levels compared to traditional methods.
The proposed system has the potential to significantly improve traffic incident management, enabling transportation agencies to respond more efficiently and effectively to incidents. This could lead to reduced congestion, faster incident clearance, and ultimately better mobility for drivers and commuters.
While the research shows promising results, there are opportunities for further refinement and expansion of the approach. Continued exploration of LLM-powered solutions for transportation challenges could yield valuable insights and advancements in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Traffic Incident Management with Large Language Models: A Hybrid Machine Learning Approach for Severity Classification
Artur Grigorev, Khaled Saleh, Yuming Ou, Adriana-Simona Mihaita
This research showcases the innovative integration of Large Language Models into machine learning workflows for traffic incident management, focusing on the classification of incident severity using accident reports. By leveraging features generated by modern language models alongside conventional data extracted from incident reports, our research demonstrates improvements in the accuracy of severity classification across several machine learning algorithms. Our contributions are threefold. First, we present an extensive comparison of various machine learning models paired with multiple large language models for feature extraction, aiming to identify the optimal combinations for accurate incident severity classification. Second, we contrast traditional feature engineering pipelines with those enhanced by language models, showcasing the superiority of language-based feature engineering in processing unstructured text. Third, our study illustrates how merging baseline features from accident reports with language-based features can improve the severity classification accuracy. This comprehensive approach not only advances the field of incident management but also highlights the cross-domain application potential of our methodology, particularly in contexts requiring the prediction of event outcomes from unstructured textual data or features translated into textual representation. Specifically, our novel methodology was applied to three distinct datasets originating from the United States, the United Kingdom, and Queensland, Australia. This cross-continental application underlines the robustness of our approach, suggesting its potential for widespread adoption in improving incident management processes globally.
Read more5/1/2024

0
Leveraging Large Language Models with Chain-of-Thought and Prompt Engineering for Traffic Crash Severity Analysis and Inference
Hao Zhen, Yucheng Shi, Yongcan Huang, Jidong J. Yang, Ninghao Liu
Harnessing the power of Large Language Models (LLMs), this study explores the use of three state-of-the-art LLMs, specifically GPT-3.5-turbo, LLaMA3-8B, and LLaMA3-70B, for crash severity inference, framing it as a classification task. We generate textual narratives from original traffic crash tabular data using a pre-built template infused with domain knowledge. Additionally, we incorporated Chain-of-Thought (CoT) reasoning to guide the LLMs in analyzing the crash causes and then inferring the severity. This study also examine the impact of prompt engineering specifically designed for crash severity inference. The LLMs were tasked with crash severity inference to: (1) evaluate the models' capabilities in crash severity analysis, (2) assess the effectiveness of CoT and domain-informed prompt engineering, and (3) examine the reasoning abilities with the CoT framework. Our results showed that LLaMA3-70B consistently outperformed the other models, particularly in zero-shot settings. The CoT and Prompt Engineering techniques significantly enhanced performance, improving logical reasoning and addressing alignment issues. Notably, the CoT offers valuable insights into LLMs' reasoning processes, unleashing their capacity to consider diverse factors such as environmental conditions, driver behavior, and vehicle characteristics in severity analysis and inference.
Read more8/12/2024

0
Learning Traffic Crashes as Language: Datasets, Benchmarks, and What-if Causal Analyses
Zhiwen Fan, Pu Wang, Yang Zhao, Yibo Zhao, Boris Ivanovic, Zhangyang Wang, Marco Pavone, Hao Frank Yang
The increasing rate of road accidents worldwide results not only in significant loss of life but also imposes billions financial burdens on societies. Current research in traffic crash frequency modeling and analysis has predominantly approached the problem as classification tasks, focusing mainly on learning-based classification or ensemble learning methods. These approaches often overlook the intricate relationships among the complex infrastructure, environmental, human and contextual factors related to traffic crashes and risky situations. In contrast, we initially propose a large-scale traffic crash language dataset, named CrashEvent, summarizing 19,340 real-world crash reports and incorporating infrastructure data, environmental and traffic textual and visual information in Washington State. Leveraging this rich dataset, we further formulate the crash event feature learning as a novel text reasoning problem and further fine-tune various large language models (LLMs) to predict detailed accident outcomes, such as crash types, severity and number of injuries, based on contextual and environmental factors. The proposed model, CrashLLM, distinguishes itself from existing solutions by leveraging the inherent text reasoning capabilities of LLMs to parse and learn from complex, unstructured data, thereby enabling a more nuanced analysis of contributing factors. Our experiments results shows that our LLM-based approach not only predicts the severity of accidents but also classifies different types of accidents and predicts injury outcomes, all with averaged F1 score boosted from 34.9% to 53.8%. Furthermore, CrashLLM can provide valuable insights for numerous open-world what-if situational-awareness traffic safety analyses with learned reasoning features, which existing models cannot offer. We make our benchmark, datasets, and model public available for further exploration.
Read more6/18/2024
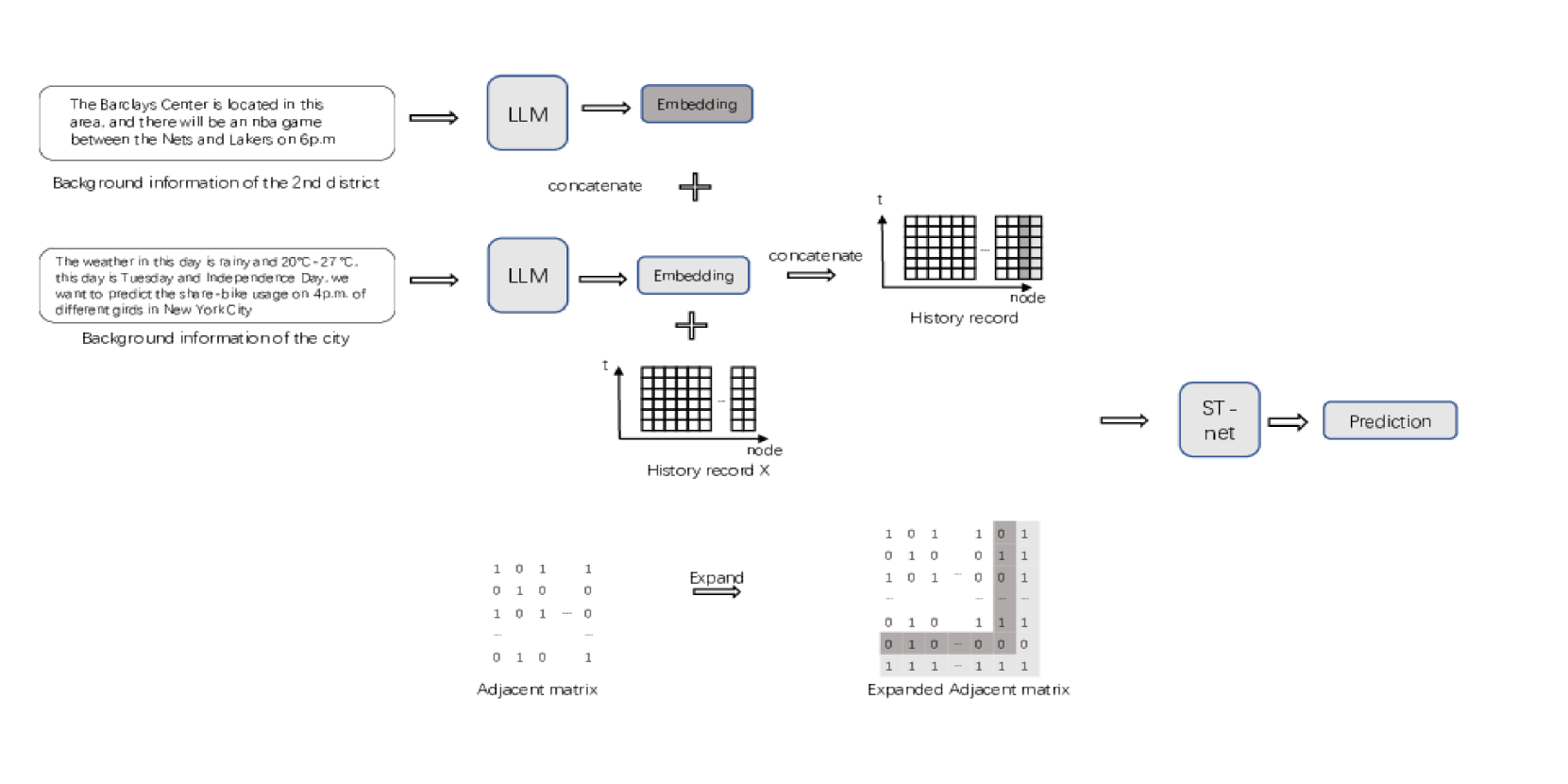
0
Enhancing Traffic Prediction with Textual Data Using Large Language Models
Xiannan Huang
Traffic prediction is pivotal for rational transportation supply scheduling and allocation. Existing researches into short-term traffic prediction, however, face challenges in adequately addressing exceptional circumstances and integrating non-numerical contextual information like weather into models. While, Large language models offer a promising solution due to their inherent world knowledge. However, directly using them for traffic prediction presents drawbacks such as high cost, lack of determinism, and limited mathematical capability. To mitigate these issues, this study proposes a novel approach. Instead of directly employing large models for prediction, it utilizes them to process textual information and obtain embeddings. These embeddings are then combined with historical traffic data and inputted into traditional spatiotemporal forecasting models. The study investigates two types of special scenarios: regional-level and node-level. For regional-level scenarios, textual information is represented as a node connected to the entire network. For node-level scenarios, embeddings from the large model represent additional nodes connected only to corresponding nodes. This approach shows a significant improvement in prediction accuracy according to our experiment of New York Bike dataset.
Read more5/14/2024