Learning Traffic Crashes as Language: Datasets, Benchmarks, and What-if Causal Analyses

0

Sign in to get full access
Overview
- This research paper explores the use of natural language processing (NLP) techniques to understand and analyze traffic crashes, with the goal of improving traffic incident management and transportation safety.
- The paper introduces several novel datasets for traffic crash analysis, as well as benchmark tasks and evaluation metrics to advance the field.
- It also presents a "what-if" causal analysis framework to investigate the factors contributing to traffic crashes and their potential mitigation strategies.
Plain English Explanation
The paper focuses on using language models and other NLP techniques to better understand traffic crashes. This is an important area of research, as traffic incidents can have significant impacts on safety, mobility, and the environment.
The researchers have created new datasets of traffic crash reports and narratives, which can be used to train and evaluate NLP models. These datasets cover a range of crash scenarios and provide rich textual information about the circumstances and causes of the incidents.
Using these datasets, the researchers have defined benchmark tasks and metrics to assess the performance of NLP models in areas like crash type classification, causal factor extraction, and crash report summarization. This will help drive progress in the field and enable more meaningful comparisons between different approaches.
The paper also introduces a "what-if" causal analysis framework, which allows researchers to explore how changes to various factors (e.g., road conditions, driver behavior) could affect the probability and severity of traffic crashes. This type of analysis can provide valuable insights to transportation planners and policymakers as they work to improve road safety.
Overall, this research represents an important step forward in using advanced language understanding techniques to gain deeper insights into traffic crashes and how they can be prevented. By making new datasets available and defining clear benchmarks, the authors are helping to advance the state of the art in this crucial area of transportation research.
Technical Explanation
The paper begins by highlighting the importance of understanding traffic crashes, as they have significant societal and economic impacts. The authors argue that natural language processing (NLP) techniques can provide valuable insights into the underlying causes and contributing factors of traffic incidents, which can inform better intervention strategies.
To support this line of research, the paper introduces several novel datasets for traffic crash analysis:
- Link to "Enhancing Traffic Incident Management with Large Language Models"
- Link to "Enhancing Traffic Prediction using Textual Data with Large Language Models"
- Link to "Exploring Traffic Crash Narratives in Jordan using Text Mining"
These datasets include textual crash reports, narratives, and other relevant information that can be used to train and evaluate NLP models. The authors define a set of benchmark tasks, such as crash type classification, causal factor extraction, and crash report summarization, along with corresponding evaluation metrics.
To further advance the understanding of traffic crashes, the paper introduces a "what-if" causal analysis framework. This approach allows researchers to investigate how changes to various factors (e.g., road conditions, driver behavior) could impact the probability and severity of traffic incidents. The authors demonstrate the use of this framework on the provided datasets, offering insights into potential mitigation strategies.
The paper also discusses related work in the area of transportation safety and incident management, including efforts to extract scenarios from traffic incident data and use language models to enhance trajectory prediction.
Critical Analysis
The research presented in this paper is a promising step towards leveraging natural language processing for traffic crash analysis and prevention. The introduction of novel datasets and benchmark tasks is particularly valuable, as it can drive progress in the field and enable more meaningful comparisons between different approaches.
However, the paper does not address several potential limitations and areas for further research. For example, the datasets may not be representative of all types of traffic crashes, or they may be biased towards certain geographic regions or demographic groups. Additionally, the "what-if" causal analysis framework, while insightful, may oversimplify the complex factors that contribute to traffic incidents and their outcomes.
Furthermore, the paper does not discuss the practical challenges of deploying these NLP-based techniques in real-world transportation management systems, such as integrating the models with existing infrastructure, ensuring data privacy and security, and addressing ethical concerns around the use of AI in transportation decision-making.
Despite these limitations, the overall approach and findings presented in the paper are valuable and could have significant implications for transportation safety and incident management. By continued research and refinement of these techniques, researchers and practitioners may be able to develop more effective strategies for reducing the frequency and severity of traffic crashes.
Conclusion
This research paper introduces a novel approach to understanding and analyzing traffic crashes using natural language processing techniques. By creating new datasets, defining benchmark tasks, and developing a "what-if" causal analysis framework, the authors have made important contributions to the field of transportation safety and incident management.
The findings presented in the paper have the potential to inform better decision-making and intervention strategies for improving road safety, reducing congestion, and mitigating the environmental impacts of traffic incidents. As the field of NLP continues to advance, the techniques developed in this research may become increasingly valuable tools for transportation professionals and policymakers.
Overall, this work represents a significant step forward in the use of language models and other NLP technologies to gain deeper insights into the complex factors that contribute to traffic crashes, and to explore potential solutions for making our roads safer and more efficient.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Learning Traffic Crashes as Language: Datasets, Benchmarks, and What-if Causal Analyses
Zhiwen Fan, Pu Wang, Yang Zhao, Yibo Zhao, Boris Ivanovic, Zhangyang Wang, Marco Pavone, Hao Frank Yang
The increasing rate of road accidents worldwide results not only in significant loss of life but also imposes billions financial burdens on societies. Current research in traffic crash frequency modeling and analysis has predominantly approached the problem as classification tasks, focusing mainly on learning-based classification or ensemble learning methods. These approaches often overlook the intricate relationships among the complex infrastructure, environmental, human and contextual factors related to traffic crashes and risky situations. In contrast, we initially propose a large-scale traffic crash language dataset, named CrashEvent, summarizing 19,340 real-world crash reports and incorporating infrastructure data, environmental and traffic textual and visual information in Washington State. Leveraging this rich dataset, we further formulate the crash event feature learning as a novel text reasoning problem and further fine-tune various large language models (LLMs) to predict detailed accident outcomes, such as crash types, severity and number of injuries, based on contextual and environmental factors. The proposed model, CrashLLM, distinguishes itself from existing solutions by leveraging the inherent text reasoning capabilities of LLMs to parse and learn from complex, unstructured data, thereby enabling a more nuanced analysis of contributing factors. Our experiments results shows that our LLM-based approach not only predicts the severity of accidents but also classifies different types of accidents and predicts injury outcomes, all with averaged F1 score boosted from 34.9% to 53.8%. Furthermore, CrashLLM can provide valuable insights for numerous open-world what-if situational-awareness traffic safety analyses with learned reasoning features, which existing models cannot offer. We make our benchmark, datasets, and model public available for further exploration.
Read more6/18/2024

0
When, Where, and What? An Novel Benchmark for Accident Anticipation and Localization with Large Language Models
Haicheng Liao, Yongkang Li, Chengyue Wang, Yanchen Guan, KaHou Tam, Chunlin Tian, Li Li, Chengzhong Xu, Zhenning Li
As autonomous driving systems increasingly become part of daily transportation, the ability to accurately anticipate and mitigate potential traffic accidents is paramount. Traditional accident anticipation models primarily utilizing dashcam videos are adept at predicting when an accident may occur but fall short in localizing the incident and identifying involved entities. Addressing this gap, this study introduces a novel framework that integrates Large Language Models (LLMs) to enhance predictive capabilities across multiple dimensions--what, when, and where accidents might occur. We develop an innovative chain-based attention mechanism that dynamically adjusts to prioritize high-risk elements within complex driving scenes. This mechanism is complemented by a three-stage model that processes outputs from smaller models into detailed multimodal inputs for LLMs, thus enabling a more nuanced understanding of traffic dynamics. Empirical validation on the DAD, CCD, and A3D datasets demonstrates superior performance in Average Precision (AP) and Mean Time-To-Accident (mTTA), establishing new benchmarks for accident prediction technology. Our approach not only advances the technological framework for autonomous driving safety but also enhances human-AI interaction, making predictive insights generated by autonomous systems more intuitive and actionable.
Read more7/29/2024

0
Enhancing Traffic Incident Management with Large Language Models: A Hybrid Machine Learning Approach for Severity Classification
Artur Grigorev, Khaled Saleh, Yuming Ou, Adriana-Simona Mihaita
This research showcases the innovative integration of Large Language Models into machine learning workflows for traffic incident management, focusing on the classification of incident severity using accident reports. By leveraging features generated by modern language models alongside conventional data extracted from incident reports, our research demonstrates improvements in the accuracy of severity classification across several machine learning algorithms. Our contributions are threefold. First, we present an extensive comparison of various machine learning models paired with multiple large language models for feature extraction, aiming to identify the optimal combinations for accurate incident severity classification. Second, we contrast traditional feature engineering pipelines with those enhanced by language models, showcasing the superiority of language-based feature engineering in processing unstructured text. Third, our study illustrates how merging baseline features from accident reports with language-based features can improve the severity classification accuracy. This comprehensive approach not only advances the field of incident management but also highlights the cross-domain application potential of our methodology, particularly in contexts requiring the prediction of event outcomes from unstructured textual data or features translated into textual representation. Specifically, our novel methodology was applied to three distinct datasets originating from the United States, the United Kingdom, and Queensland, Australia. This cross-continental application underlines the robustness of our approach, suggesting its potential for widespread adoption in improving incident management processes globally.
Read more5/1/2024
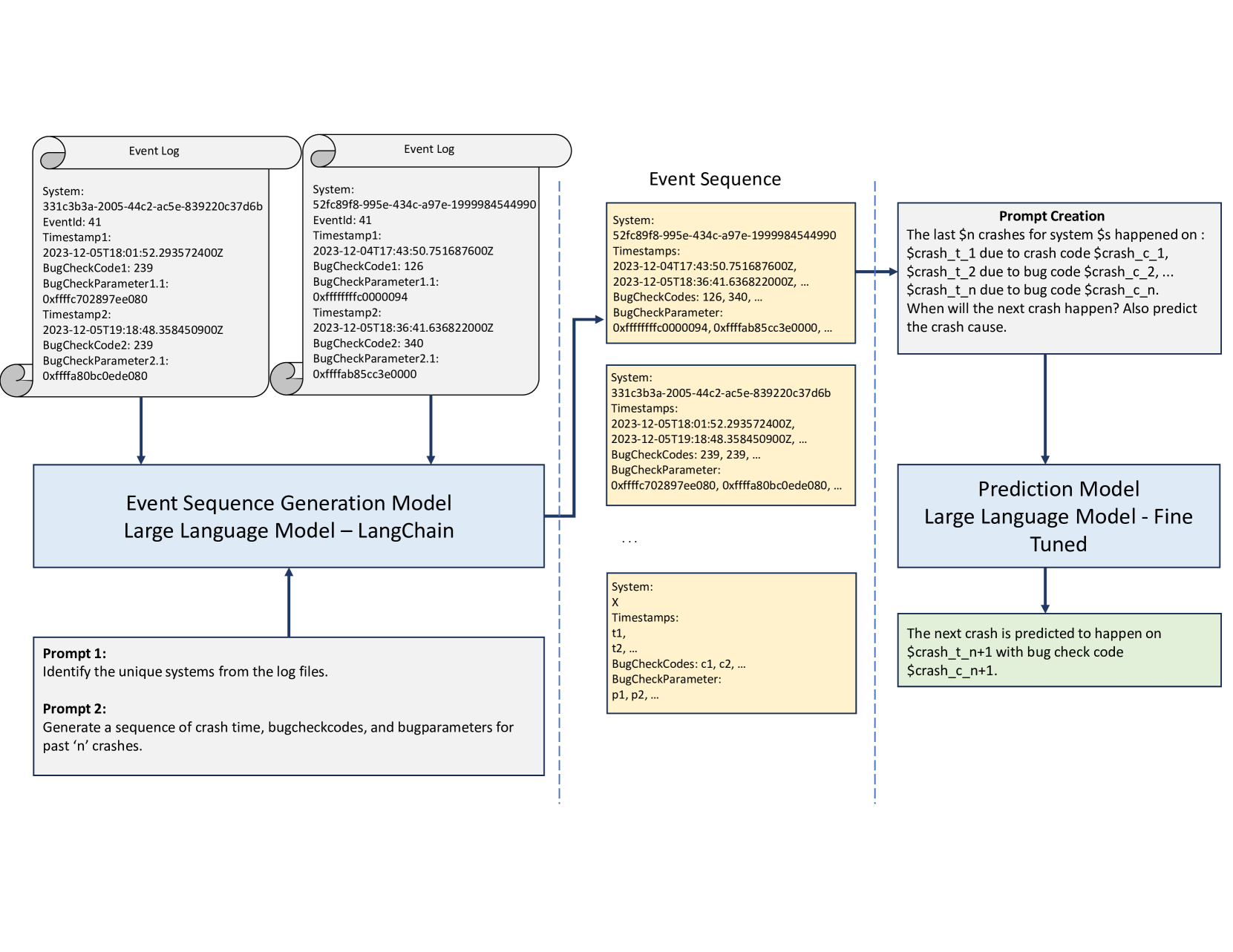
0
CrashEventLLM: Predicting System Crashes with Large Language Models
Priyanka Mudgal, Bijan Arbab, Swaathi Sampath Kumar
As the dependence on computer systems expands across various domains, focusing on personal, industrial, and large-scale applications, there arises a compelling need to enhance their reliability to sustain business operations seamlessly and ensure optimal user satisfaction. System logs generated by these devices serve as valuable repositories of historical trends and past failures. The use of machine learning techniques for failure prediction has become commonplace, enabling the extraction of insights from past data to anticipate future behavior patterns. Recently, large language models have demonstrated remarkable capabilities in tasks including summarization, reasoning, and event prediction. Therefore, in this paper, we endeavor to investigate the potential of large language models in predicting system failures, leveraging insights learned from past failure behavior to inform reasoning and decision-making processes effectively. Our approach involves leveraging data from the Intel Computing Improvement Program (ICIP) system crash logs to identify significant events and develop CrashEventLLM. This model, built upon a large language model framework, serves as our foundation for crash event prediction. Specifically, our model utilizes historical data to forecast future crash events, informed by expert annotations. Additionally, it goes beyond mere prediction, offering insights into potential causes for each crash event. This work provides the preliminary insights into prompt-based large language models for the log-based event prediction task.
Read more7/30/2024