Enhancing Traffic Object Detection in Variable Illumination with RGB-Event Fusion

0
🔎
Sign in to get full access
Overview
- Traffic object detection under varying illumination is challenging due to information loss in conventional cameras
- This paper introduces event cameras and proposes a novel Structure-aware Fusion Network (SFNet) to address this issue
- SFNet extracts sharp and complete object structures from event streams to compensate for lost information in images
- The network obtains illumination-robust representations for traffic object detection through cross-modality fusion
Plain English Explanation
Detecting objects like vehicles in traffic can be difficult when lighting conditions change, as regular cameras have a limited range of brightness they can capture. To address this, the researchers introduce event cameras, which work differently than standard cameras.
The key idea is to use the information from these event cameras to supplement the image data and create more robust object detection. The Structure-aware Fusion Network (SFNet) extracts clear and complete outlines of objects from the event stream. It then fuses this structural information with the image data to generate illumination-invariant representations that enable accurate object detection even in challenging lighting conditions.
To ensure the object structures extracted from the event data are sharp and intact, the researchers propose the Reliable Structure Generation Network (RSGNet). This generates "Speed Invariant Frames" that preserve object details despite varying motion. An Adaptive Feature Complement Module (AFCM) then adaptively fuses the image and event features, guided by the overall brightness of the scene, to compensate for information loss in the images.
Finally, the researchers built a new DSEC-Det dataset with high-quality annotations to train and evaluate their system. Their experiments show the SFNet outperforms standard camera-based methods, improving object detection performance by 8% in mAP50 and 6% in mAP50:95.
Technical Explanation
The proposed Structure-aware Fusion Network (SFNet) addresses the challenge of traffic object detection under variable illumination by leveraging event cameras to extract sharp and complete object structures. These structures compensate for information loss in traditional image data through cross-modality fusion, enabling the network to obtain illumination-robust representations.
To mitigate the sparsity or blurriness issues arising from diverse motion states of traffic objects in fixed-interval event sampling methods, the researchers introduce the Reliable Structure Generation Network (RSGNet). RSGNet generates "Speed Invariant Frames" (SIF) that preserve the integrity and sharpness of object structures.
The Adaptive Feature Complement Module (AFCM) then guides the adaptive fusion of image and event features. It does this by perceiving the global lightness distribution of the images, allowing the system to compensate for information loss in the images and generate illumination-robust representations.
To address the lack of large-scale, high-quality annotations in existing event-based object detection datasets, the researchers built the DSEC-Det dataset. This dataset consists of 53 sequences with 63,931 images and more than 208,000 labels for 8 classes.
Extensive experiments demonstrate that the proposed SFNet can overcome the perceptual boundaries of conventional cameras, outperforming frame-based methods by 8.0% in mAP50 and 5.9% in mAP50:95.
Critical Analysis
The paper presents a compelling approach to improving traffic object detection under variable illumination by leveraging event cameras and cross-modality fusion. The researchers have carefully designed their network architecture and training dataset to address key challenges in this domain.
However, one potential limitation is the reliance on event cameras, which may not be as widely available or affordable as standard RGB cameras. The performance gains demonstrated may not justify the additional hardware requirements for all applications.
Additionally, the researchers only evaluated their system on the DSEC-Det dataset, which they created themselves. While this dataset appears to be of high quality, it would be valuable to see how the SFNet performs on other established benchmarks to better understand its generalization capabilities.
Further research could explore ways to make the event camera technology more accessible or investigate alternative fusion strategies that do not rely on specialized hardware. Additionally, testing the SFNet on a broader range of datasets and real-world scenarios could provide deeper insights into its strengths and limitations.
Conclusion
This paper introduces a novel Structure-aware Fusion Network (SFNet) that leverages event cameras to enable robust traffic object detection under variable illumination conditions. By extracting sharp and complete object structures from the event stream and fusing them with image data, the SFNet can generate illumination-invariant representations that outperform conventional camera-based methods.
The researchers have made significant contributions to this field, including the Reliable Structure Generation Network (RSGNet) for preserving object details and the Adaptive Feature Complement Module (AFCM) for adaptive fusion. The introduction of the DSEC-Det dataset also provides a valuable resource for further research and development in this area.
While the event camera requirement may limit the immediate widespread adoption of this approach, the significant performance gains demonstrated by the SFNet suggest that further advancements in event-based sensing and fusion techniques could have a transformative impact on traffic object detection and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Enhancing Traffic Object Detection in Variable Illumination with RGB-Event Fusion
Zhanwen Liu, Nan Yang, Yang Wang, Yuke Li, Xiangmo Zhao, Fei-Yue Wang
Traffic object detection under variable illumination is challenging due to the information loss caused by the limited dynamic range of conventional frame-based cameras. To address this issue, we introduce bio-inspired event cameras and propose a novel Structure-aware Fusion Network (SFNet) that extracts sharp and complete object structures from the event stream to compensate for the lost information in images through cross-modality fusion, enabling the network to obtain illumination-robust representations for traffic object detection. Specifically, to mitigate the sparsity or blurriness issues arising from diverse motion states of traffic objects in fixed-interval event sampling methods, we propose the Reliable Structure Generation Network (RSGNet) to generate Speed Invariant Frames (SIF), ensuring the integrity and sharpness of object structures. Next, we design a novel Adaptive Feature Complement Module (AFCM) which guides the adaptive fusion of two modality features to compensate for the information loss in the images by perceiving the global lightness distribution of the images, thereby generating illumination-robust representations. Finally, considering the lack of large-scale and high-quality annotations in the existing event-based object detection datasets, we build a DSEC-Det dataset, which consists of 53 sequences with 63,931 images and more than 208,000 labels for 8 classes. Extensive experimental results demonstrate that our proposed SFNet can overcome the perceptual boundaries of conventional cameras and outperform the frame-based method by 8.0% in mAP50 and 5.9% in mAP50:95. Our code and dataset will be available at https://github.com/YN-Yang/SFNet.
Read more9/17/2024
🔎
0
SRFNet: Monocular Depth Estimation with Fine-grained Structure via Spatial Reliability-oriented Fusion of Frames and Events
Tianbo Pan, Zidong Cao, Lin Wang
Monocular depth estimation is a crucial task to measure distance relative to a camera, which is important for applications, such as robot navigation and self-driving. Traditional frame-based methods suffer from performance drops due to the limited dynamic range and motion blur. Therefore, recent works leverage novel event cameras to complement or guide the frame modality via frame-event feature fusion. However, event streams exhibit spatial sparsity, leaving some areas unperceived, especially in regions with marginal light changes. Therefore, direct fusion methods, e.g., RAMNet, often ignore the contribution of the most confident regions of each modality. This leads to structural ambiguity in the modality fusion process, thus degrading the depth estimation performance. In this paper, we propose a novel Spatial Reliability-oriented Fusion Network (SRFNet), that can estimate depth with fine-grained structure at both daytime and nighttime. Our method consists of two key technical components. Firstly, we propose an attention-based interactive fusion (AIF) module that applies spatial priors of events and frames as the initial masks and learns the consensus regions to guide the inter-modal feature fusion. The fused feature are then fed back to enhance the frame and event feature learning. Meanwhile, it utilizes an output head to generate a fused mask, which is iteratively updated for learning consensual spatial priors. Secondly, we propose the Reliability-oriented Depth Refinement (RDR) module to estimate dense depth with the fine-grained structure based on the fused features and masks. We evaluate the effectiveness of our method on the synthetic and real-world datasets, which shows that, even without pretraining, our method outperforms the prior methods, e.g., RAMNet, especially in night scenes. Our project homepage: https://vlislab22.github.io/SRFNet.
Read more7/25/2024

0
Embracing Events and Frames with Hierarchical Feature Refinement Network for Object Detection
Hu Cao, Zehua Zhang, Yan Xia, Xinyi Li, Jiahao Xia, Guang Chen, Alois Knoll
In frame-based vision, object detection faces substantial performance degradation under challenging conditions due to the limited sensing capability of conventional cameras. Event cameras output sparse and asynchronous events, providing a potential solution to solve these problems. However, effectively fusing two heterogeneous modalities remains an open issue. In this work, we propose a novel hierarchical feature refinement network for event-frame fusion. The core concept is the design of the coarse-to-fine fusion module, denoted as the cross-modality adaptive feature refinement (CAFR) module. In the initial phase, the bidirectional cross-modality interaction (BCI) part facilitates information bridging from two distinct sources. Subsequently, the features are further refined by aligning the channel-level mean and variance in the two-fold adaptive feature refinement (TAFR) part. We conducted extensive experiments on two benchmarks: the low-resolution PKU-DDD17-Car dataset and the high-resolution DSEC dataset. Experimental results show that our method surpasses the state-of-the-art by an impressive margin of $textbf{8.0}%$ on the DSEC dataset. Besides, our method exhibits significantly better robustness (textbf{69.5}% versus textbf{38.7}%) when introducing 15 different corruption types to the frame images. The code can be found at the link (https://github.com/HuCaoFighting/FRN).
Read more7/18/2024
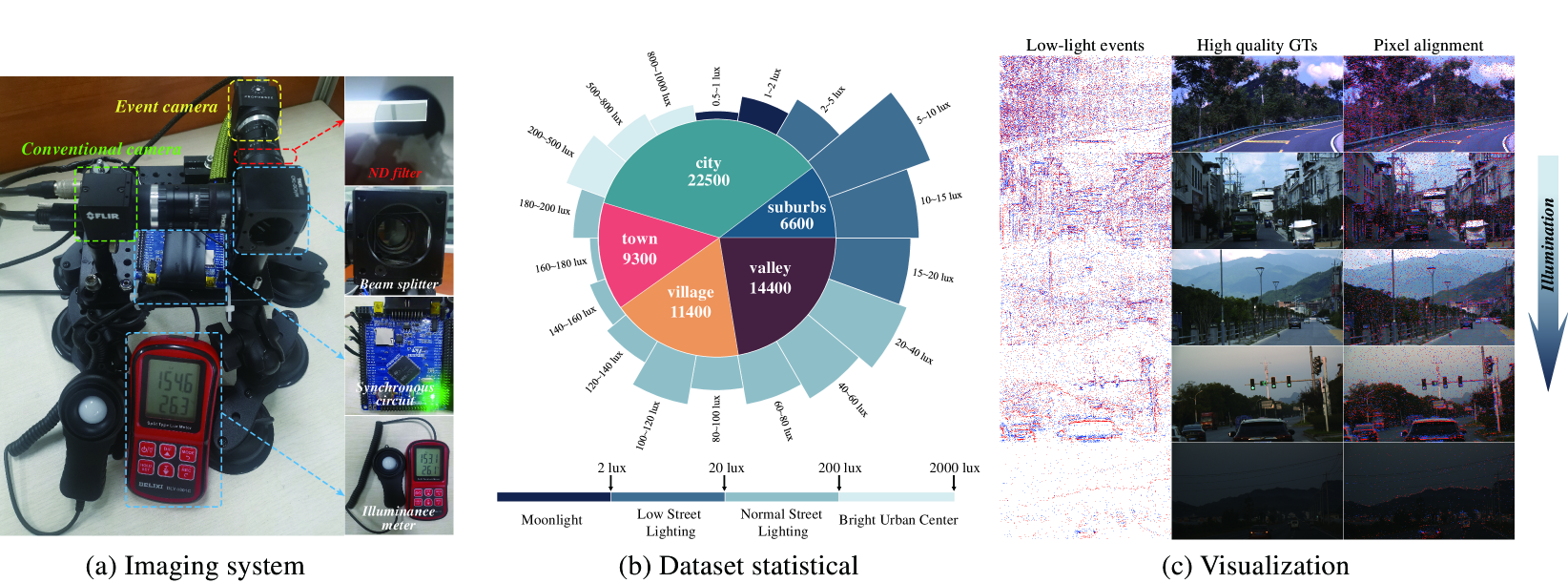
0
Seeing Motion at Nighttime with an Event Camera
Haoyue Liu, Shihan Peng, Lin Zhu, Yi Chang, Hanyu Zhou, Luxin Yan
We focus on a very challenging task: imaging at nighttime dynamic scenes. Most previous methods rely on the low-light enhancement of a conventional RGB camera. However, they would inevitably face a dilemma between the long exposure time of nighttime and the motion blur of dynamic scenes. Event cameras react to dynamic changes with higher temporal resolution (microsecond) and higher dynamic range (120dB), offering an alternative solution. In this work, we present a novel nighttime dynamic imaging method with an event camera. Specifically, we discover that the event at nighttime exhibits temporal trailing characteristics and spatial non-stationary distribution. Consequently, we propose a nighttime event reconstruction network (NER-Net) which mainly includes a learnable event timestamps calibration module (LETC) to align the temporal trailing events and a non-uniform illumination aware module (NIAM) to stabilize the spatiotemporal distribution of events. Moreover, we construct a paired real low-light event dataset (RLED) through a co-axial imaging system, including 64,200 spatially and temporally aligned image GTs and low-light events. Extensive experiments demonstrate that the proposed method outperforms state-of-the-art methods in terms of visual quality and generalization ability on real-world nighttime datasets. The project are available at: https://github.com/Liu-haoyue/NER-Net.
Read more4/19/2024