SRFNet: Monocular Depth Estimation with Fine-grained Structure via Spatial Reliability-oriented Fusion of Frames and Events

0
🔎
Sign in to get full access
Overview
- Monocular depth estimation is crucial for applications like robot navigation and self-driving
- Traditional frame-based methods suffer from performance drops due to limited dynamic range and motion blur
- Recent works leverage event cameras to complement or guide the frame modality
- Event streams have spatial sparsity, leaving some areas unperceived
- Direct fusion methods often ignore the contribution of the most confident regions of each modality, leading to structural ambiguity
Plain English Explanation
Monocular depth estimation is the task of measuring the distance to objects relative to a camera. This is important for applications like robot navigation and self-driving cars, where knowing the depth of the environment is crucial.
Traditional methods that use regular camera frames often struggle with depth estimation, especially in challenging lighting conditions or when there is a lot of motion blur. To address these limitations, researchers have started using a new type of camera called an event camera. Event cameras can capture rapid changes in light intensity, which can provide additional information to complement the regular camera frames.
However, event cameras have their own challenges - the data they capture is sparse, meaning there are gaps in the information, especially in areas where the light doesn't change much. This can lead to issues when trying to combine the event camera data with the regular camera frames to estimate depth.
The paper proposes a new method called SRFNet that aims to address these challenges. The key ideas are:
- Using an attention-based interactive fusion (AIF) module to learn the consensus regions between the event and frame data, and use that to guide the fusion of the features from the two modalities.
- Introducing a Reliability-oriented Depth Refinement (RDR) module to estimate dense depth with fine-grained structure based on the fused features and spatial priors.
The goal is to create a depth estimation system that works well in both daytime and nighttime conditions, by effectively leveraging the complementary strengths of the event and frame data.
Technical Explanation
The proposed SRFNet consists of two key technical components:
-
Attention-based Interactive Fusion (AIF) Module: This module applies spatial priors of events and frames as initial masks and learns the consensus regions to guide the inter-modal feature fusion. The fused features are then fed back to enhance the frame and event feature learning. The module also generates a fused mask, which is iteratively updated for learning consensual spatial priors.
-
Reliability-oriented Depth Refinement (RDR) Module: This module estimates dense depth with fine-grained structure based on the fused features and masks from the AIF module. It leverages the most confident regions from each modality to produce a high-quality depth estimate.
The authors evaluate their method on both synthetic and real-world datasets, and show that SRFNet outperforms prior methods, especially in nighttime scenes, without any pretraining.
Critical Analysis
The paper presents a novel approach to leveraging event cameras for monocular depth estimation, addressing some of the key challenges with direct fusion methods. The attention-based fusion and reliability-oriented refinement modules seem to be effective in producing high-quality depth estimates, even in challenging lighting conditions.
However, the paper does not discuss the computational cost or runtime of the proposed method, which could be an important consideration for real-world applications. Additionally, the authors could have explored the generalization capabilities of their method by evaluating it on a wider range of datasets or scenes.
Further research could investigate ways to make the depth estimation more robust to noise or outliers in the event data, or explore how the method could be adapted to work with other sensor modalities, such as lidar or radar, in a multi-modal depth estimation system.
Conclusion
The SRFNet proposed in this paper represents a significant advancement in monocular depth estimation using event cameras. By effectively fusing the event and frame data and leveraging the most reliable regions from each modality, the method can produce high-quality depth estimates in both daytime and nighttime conditions. This has important implications for a wide range of applications, such as robot navigation, autonomous driving, and augmented reality, where accurate depth perception is crucial for safety and functionality.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
SRFNet: Monocular Depth Estimation with Fine-grained Structure via Spatial Reliability-oriented Fusion of Frames and Events
Tianbo Pan, Zidong Cao, Lin Wang
Monocular depth estimation is a crucial task to measure distance relative to a camera, which is important for applications, such as robot navigation and self-driving. Traditional frame-based methods suffer from performance drops due to the limited dynamic range and motion blur. Therefore, recent works leverage novel event cameras to complement or guide the frame modality via frame-event feature fusion. However, event streams exhibit spatial sparsity, leaving some areas unperceived, especially in regions with marginal light changes. Therefore, direct fusion methods, e.g., RAMNet, often ignore the contribution of the most confident regions of each modality. This leads to structural ambiguity in the modality fusion process, thus degrading the depth estimation performance. In this paper, we propose a novel Spatial Reliability-oriented Fusion Network (SRFNet), that can estimate depth with fine-grained structure at both daytime and nighttime. Our method consists of two key technical components. Firstly, we propose an attention-based interactive fusion (AIF) module that applies spatial priors of events and frames as the initial masks and learns the consensus regions to guide the inter-modal feature fusion. The fused feature are then fed back to enhance the frame and event feature learning. Meanwhile, it utilizes an output head to generate a fused mask, which is iteratively updated for learning consensual spatial priors. Secondly, we propose the Reliability-oriented Depth Refinement (RDR) module to estimate dense depth with the fine-grained structure based on the fused features and masks. We evaluate the effectiveness of our method on the synthetic and real-world datasets, which shows that, even without pretraining, our method outperforms the prior methods, e.g., RAMNet, especially in night scenes. Our project homepage: https://vlislab22.github.io/SRFNet.
Read more7/25/2024

0
Embracing Events and Frames with Hierarchical Feature Refinement Network for Object Detection
Hu Cao, Zehua Zhang, Yan Xia, Xinyi Li, Jiahao Xia, Guang Chen, Alois Knoll
In frame-based vision, object detection faces substantial performance degradation under challenging conditions due to the limited sensing capability of conventional cameras. Event cameras output sparse and asynchronous events, providing a potential solution to solve these problems. However, effectively fusing two heterogeneous modalities remains an open issue. In this work, we propose a novel hierarchical feature refinement network for event-frame fusion. The core concept is the design of the coarse-to-fine fusion module, denoted as the cross-modality adaptive feature refinement (CAFR) module. In the initial phase, the bidirectional cross-modality interaction (BCI) part facilitates information bridging from two distinct sources. Subsequently, the features are further refined by aligning the channel-level mean and variance in the two-fold adaptive feature refinement (TAFR) part. We conducted extensive experiments on two benchmarks: the low-resolution PKU-DDD17-Car dataset and the high-resolution DSEC dataset. Experimental results show that our method surpasses the state-of-the-art by an impressive margin of $textbf{8.0}%$ on the DSEC dataset. Besides, our method exhibits significantly better robustness (textbf{69.5}% versus textbf{38.7}%) when introducing 15 different corruption types to the frame images. The code can be found at the link (https://github.com/HuCaoFighting/FRN).
Read more7/18/2024
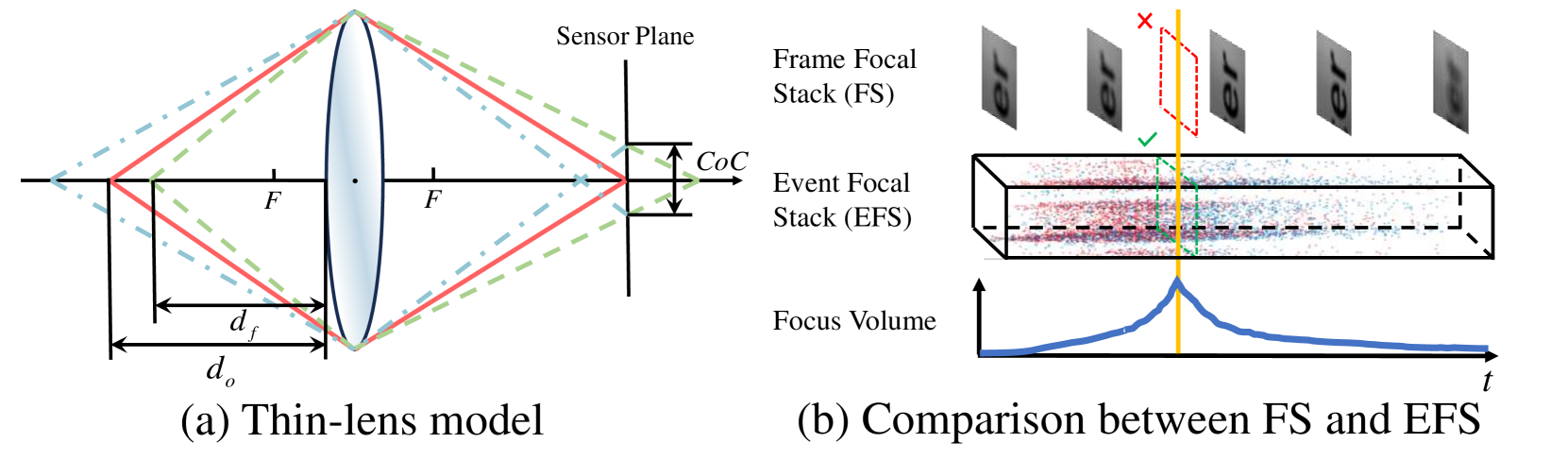
0
Learning Monocular Depth from Focus with Event Focal Stack
Chenxu Jiang, Mingyuan Lin, Chi Zhang, Zhenghai Wang, Lei Yu
Depth from Focus estimates depth by determining the moment of maximum focus from multiple shots at different focal distances, i.e. the Focal Stack. However, the limited sampling rate of conventional optical cameras makes it difficult to obtain sufficient focus cues during the focal sweep. Inspired by biological vision, the event camera records intensity changes over time in extremely low latency, which provides more temporal information for focus time acquisition. In this study, we propose the EDFF Network to estimate sparse depth from the Event Focal Stack. Specifically, we utilize the event voxel grid to encode intensity change information and project event time surface into the depth domain to preserve per-pixel focal distance information. A Focal-Distance-guided Cross-Modal Attention Module is presented to fuse the information mentioned above. Additionally, we propose a Multi-level Depth Fusion Block designed to integrate results from each level of a UNet-like architecture and produce the final output. Extensive experiments validate that our method outperforms existing state-of-the-art approaches.
Read more5/14/2024
🔎
0
New!Enhancing Traffic Object Detection in Variable Illumination with RGB-Event Fusion
Zhanwen Liu, Nan Yang, Yang Wang, Yuke Li, Xiangmo Zhao, Fei-Yue Wang
Traffic object detection under variable illumination is challenging due to the information loss caused by the limited dynamic range of conventional frame-based cameras. To address this issue, we introduce bio-inspired event cameras and propose a novel Structure-aware Fusion Network (SFNet) that extracts sharp and complete object structures from the event stream to compensate for the lost information in images through cross-modality fusion, enabling the network to obtain illumination-robust representations for traffic object detection. Specifically, to mitigate the sparsity or blurriness issues arising from diverse motion states of traffic objects in fixed-interval event sampling methods, we propose the Reliable Structure Generation Network (RSGNet) to generate Speed Invariant Frames (SIF), ensuring the integrity and sharpness of object structures. Next, we design a novel Adaptive Feature Complement Module (AFCM) which guides the adaptive fusion of two modality features to compensate for the information loss in the images by perceiving the global lightness distribution of the images, thereby generating illumination-robust representations. Finally, considering the lack of large-scale and high-quality annotations in the existing event-based object detection datasets, we build a DSEC-Det dataset, which consists of 53 sequences with 63,931 images and more than 208,000 labels for 8 classes. Extensive experimental results demonstrate that our proposed SFNet can overcome the perceptual boundaries of conventional cameras and outperform the frame-based method by 8.0% in mAP50 and 5.9% in mAP50:95. Our code and dataset will be available at https://github.com/YN-Yang/SFNet.
Read more9/17/2024