Enhancing Traffic Safety with Parallel Dense Video Captioning for End-to-End Event Analysis

0

Sign in to get full access
Overview
- Proposes a parallel dense video captioning approach to enhance traffic safety through end-to-end event analysis
- Combines object detection, tracking, and video captioning to provide detailed descriptions of traffic incidents
- Aims to improve traffic monitoring and incident response by providing rich, real-time information about events on the road
Plain English Explanation
This research paper presents a new method for analyzing video footage of traffic to enhance road safety. The approach uses parallel dense video captioning to automatically describe what is happening in the video, including the detection and tracking of vehicles, pedestrians, and other objects.
The goal is to provide detailed, real-time information about traffic incidents and events, such as collisions, traffic jams, or dangerous driver behavior. By combining object detection, tracking, and video captioning, the system can generate textual descriptions of the key elements and timeline of these events. This could help improve traffic monitoring and incident response by giving analysts and authorities a rich understanding of what is happening on the roads.
The researchers hope that this end-to-end approach to traffic event analysis will lead to enhanced safety, as the detailed information could support better decision-making and resource allocation by transportation agencies and emergency services. The internal links to related works highlight how this research builds on and differs from previous efforts in areas like crowd simulation and traffic scene analysis.
Technical Explanation
The proposed system takes a parallel approach to dense video captioning, combining object detection, tracking, and natural language generation to provide comprehensive descriptions of traffic events. The object detection component identifies vehicles, pedestrians, and other relevant entities in the video frames, while the tracking module links these detections across time to follow the movement of objects.
The video captioning model then generates textual descriptions of the detected events and their temporal evolution. This allows the system to provide a detailed, step-by-step account of the key occurrences in the video, such as a car running a red light, a pedestrian crossing the street, or a multi-car collision.
The parallel architecture ensures that the object detection, tracking, and captioning components operate simultaneously, enabling real-time processing and analysis of the video feed. The researchers evaluate their approach on a custom dataset of traffic surveillance footage, demonstrating its effectiveness in accurately identifying and describing a range of traffic events.
Critical Analysis
The paper presents a promising approach to enhancing traffic safety through advanced video analysis, but it also acknowledges several limitations and areas for further research. One key concern is the reliance on specialized traffic surveillance datasets, which may limit the generalizability of the system to more diverse real-world scenarios.
Additionally, the authors note that the performance of the video captioning model could potentially be improved by incorporating additional contextual information, such as weather conditions, road infrastructure, or driver behavior patterns.
Further research could also explore ways to integrate the system's outputs with existing traffic management and incident response workflows, ensuring that the detailed event descriptions are effectively utilized by transportation agencies and emergency services. Addressing these challenges could help unlock the full potential of this technology to improve road safety and efficiency.
Conclusion
This research paper introduces a novel parallel dense video captioning approach to enhance traffic safety through comprehensive, real-time analysis of traffic events. By combining object detection, tracking, and natural language generation, the system can provide detailed textual descriptions of incidents on the road, such as collisions, traffic jams, and dangerous driver behavior.
The researchers hope that this end-to-end event analysis capability will support improved traffic monitoring, incident response, and decision-making by transportation authorities and emergency services. While the approach shows promise, further work is needed to address limitations and integrate the technology into existing traffic management systems. Nonetheless, this research represents an important step towards leveraging advanced computer vision and natural language processing techniques to enhance road safety and efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Traffic Safety with Parallel Dense Video Captioning for End-to-End Event Analysis
Maged Shoman, Dongdong Wang, Armstrong Aboah, Mohamed Abdel-Aty
This paper introduces our solution for Track 2 in AI City Challenge 2024. The task aims to solve traffic safety description and analysis with the dataset of Woven Traffic Safety (WTS), a real-world Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding. Our solution mainly focuses on the following points: 1) To solve dense video captioning, we leverage the framework of dense video captioning with parallel decoding (PDVC) to model visual-language sequences and generate dense caption by chapters for video. 2) Our work leverages CLIP to extract visual features to more efficiently perform cross-modality training between visual and textual representations. 3) We conduct domain-specific model adaptation to mitigate domain shift problem that poses recognition challenge in video understanding. 4) Moreover, we leverage BDD-5K captioned videos to conduct knowledge transfer for better understanding WTS videos and more accurate captioning. Our solution has yielded on the test set, achieving 6th place in the competition. The open source code will be available at https://github.com/UCF-SST-Lab/AICity2024CVPRW
Read more4/15/2024
0
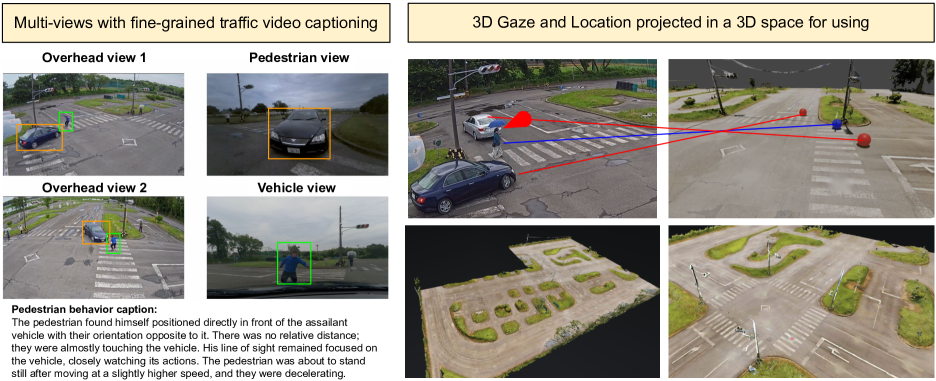
WTS: A Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding
Quan Kong, Yuki Kawana, Rajat Saini, Ashutosh Kumar, Jingjing Pan, Ta Gu, Yohei Ozao, Balazs Opra, David C. Anastasiu, Yoichi Sato, Norimasa Kobori
In this paper, we address the challenge of fine-grained video event understanding in traffic scenarios, vital for autonomous driving and safety. Traditional datasets focus on driver or vehicle behavior, often neglecting pedestrian perspectives. To fill this gap, we introduce the WTS dataset, highlighting detailed behaviors of both vehicles and pedestrians across over 1.2k video events in hundreds of traffic scenarios. WTS integrates diverse perspectives from vehicle ego and fixed overhead cameras in a vehicle-infrastructure cooperative environment, enriched with comprehensive textual descriptions and unique 3D Gaze data for a synchronized 2D/3D view, focusing on pedestrian analysis. We also pro-vide annotations for 5k publicly sourced pedestrian-related traffic videos. Additionally, we introduce LLMScorer, an LLM-based evaluation metric to align inference captions with ground truth. Using WTS, we establish a benchmark for dense video-to-text tasks, exploring state-of-the-art Vision-Language Models with an instance-aware VideoLLM method as a baseline. WTS aims to advance fine-grained video event understanding, enhancing traffic safety and autonomous driving development.
Read more7/23/2024
0
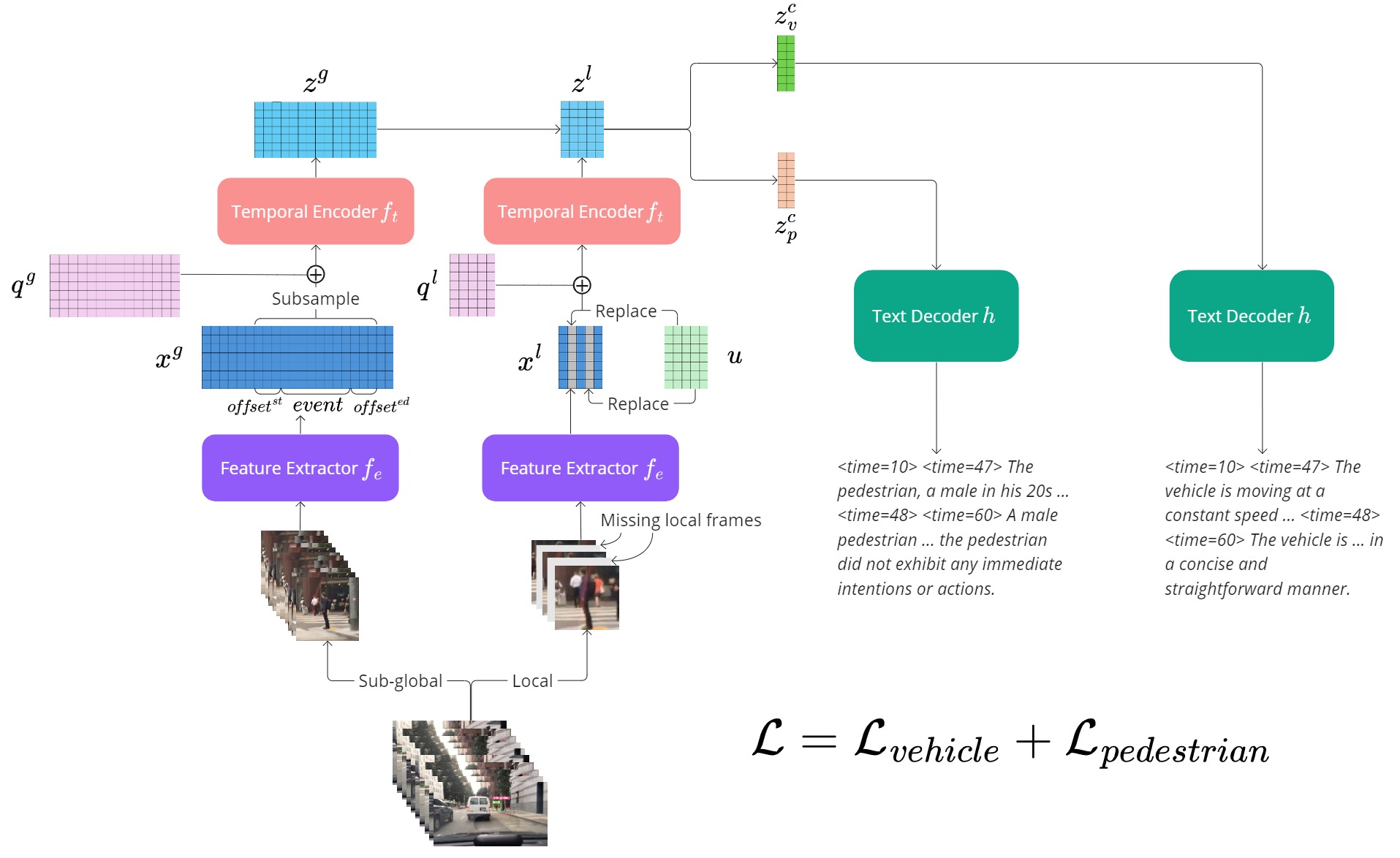
TrafficVLM: A Controllable Visual Language Model for Traffic Video Captioning
Quang Minh Dinh, Minh Khoi Ho, Anh Quan Dang, Hung Phong Tran
Traffic video description and analysis have received much attention recently due to the growing demand for efficient and reliable urban surveillance systems. Most existing methods only focus on locating traffic event segments, which severely lack descriptive details related to the behaviour and context of all the subjects of interest in the events. In this paper, we present TrafficVLM, a novel multi-modal dense video captioning model for vehicle ego camera view. TrafficVLM models traffic video events at different levels of analysis, both spatially and temporally, and generates long fine-grained descriptions for the vehicle and pedestrian at different phases of the event. We also propose a conditional component for TrafficVLM to control the generation outputs and a multi-task fine-tuning paradigm to enhance TrafficVLM's learning capability. Experiments show that TrafficVLM performs well on both vehicle and overhead camera views. Our solution achieved outstanding results in Track 2 of the AI City Challenge 2024, ranking us third in the challenge standings. Our code is publicly available at https://github.com/quangminhdinh/TrafficVLM.
Read more4/16/2024

0
Dense Video Object Captioning from Disjoint Supervision
Xingyi Zhou, Anurag Arnab, Chen Sun, Cordelia Schmid
We propose a new task and model for dense video object captioning -- detecting, tracking and captioning trajectories of objects in a video. This task unifies spatial and temporal localization in video, whilst also requiring fine-grained visual understanding that is best described by natural language. We propose a unified model, and demonstrate how our end-to-end approach is more accurate and temporally coherent than a multi-stage pipeline combining state-of-the-art detection, tracking, and captioning models. Moreover, we propose a training strategy based on a mixture of disjoint tasks, which allows us to leverage diverse, large-scale datasets which supervise different parts of our model. Although each pretraining task only provides weak supervision, they are complementary and, when combined, result in noteworthy zero-shot ability and serve as strong initialization for additional finetuning to further improve accuracy. We carefully design new metrics capturing all components of our task, and show how we can repurpose existing video grounding datasets (e.g. VidSTG and VLN) for our new task. We show that our model improves upon a number of strong baselines for this new task. Furthermore, we can apply our model to the task of spatial grounding, outperforming prior state-of-the-art on VidSTG and VLN, without explicitly training for it. Code is available at https://github.com/google-research/scenic/tree/main/scenic/projects/densevoc.
Read more4/10/2024