Visual-information-driven model for crowd simulation using temporal convolutional network

0
📈
Sign in to get full access
Overview
- Crowd simulations are crucial for building design, affecting both user experience and public safety.
- Traditional knowledge-driven models have limitations, while data-driven models promise more realism.
- Existing data-driven models often struggle with adaptability and applicability across different geometries.
- Incorporating visual information, including scenario geometry and pedestrian locomotion, could enhance the adaptability and realism of data-driven crowd simulation models.
Plain English Explanation
Crowd simulations are computer models that help designers and planners understand how large groups of people might move and behave in different settings, like buildings or public spaces. These simulations are important because they can inform the design process, ensuring that buildings are safe and comfortable for the people who use them.
Traditional crowd simulation models rely on expert knowledge, which can be useful but may not fully capture the complexity of real-world human behavior. In contrast, data-driven crowd simulation models, which use machine learning techniques to analyze real-world data on pedestrian movement, have the potential to create more realistic simulations.
However, most existing data-driven models are designed for specific building layouts or geometries, which means they may not work well in different settings. To address this, the researchers in this paper propose a new approach that incorporates visual information, such as the shape of the space and how people move through it, to create a more adaptable and realistic data-driven crowd simulation model.
Technical Explanation
The researchers developed a Visual-Information-Driven (VID) crowd simulation model that predicts pedestrian velocity based on the social and visual information about an individual, as well as their past motion data. To extract the visual information, the researchers used a radar-geometry-locomotion method that considers the scenario geometry and pedestrian locomotion.
The core of the VID model is a temporal convolutional network (TCN)-based deep learning model, called the social-visual TCN, which is used for velocity prediction. The researchers tested the VID model on three public pedestrian motion datasets with different geometric scenarios: corridor, corner, and T-junction.
Both qualitative and quantitative metrics were used to evaluate the VID model, and the results showed that it had improved adaptability across all three geometric scenarios compared to previous data-driven models. This demonstrates the effectiveness of the proposed visual-information-driven approach in enhancing the adaptability of data-driven crowd simulation models.
Critical Analysis
The researchers acknowledge that their VID model has some limitations, such as the need for extensive training data and the potential for performance degradation in complex or crowded scenarios. Additionally, the model may not fully capture the influence of external factors, such as social and cultural norms, on pedestrian behavior.
Further research could explore ways to integrate more diverse data sources, such as sensor data or qualitative observations, to improve the model's adaptability and realism. Exploring alternative deep learning architectures or incorporating additional contextual information may also help to address the model's limitations.
Overall, the proposed VID model represents a promising step forward in enhancing the adaptability and realism of data-driven crowd simulation models, with potential applications in urban planning, building design, and public safety.
Conclusion
The VID crowd simulation model developed in this paper demonstrates the value of incorporating visual information, including scenario geometry and pedestrian locomotion, to create more adaptable and realistic data-driven crowd simulations. By leveraging a temporal convolutional network-based deep learning approach, the researchers were able to improve the model's performance across a variety of geometric scenarios, highlighting the potential of this visual-information-driven approach for enhancing the state of the art in crowd simulation technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Visual-information-driven model for crowd simulation using temporal convolutional network
Xuanwen Liang, Eric Wai Ming Lee
Crowd simulations play a pivotal role in building design, influencing both user experience and public safety. While traditional knowledge-driven models have their merits, data-driven crowd simulation models promise to bring a new dimension of realism to these simulations. However, most of the existing data-driven models are designed for specific geometries, leading to poor adaptability and applicability. A promising strategy for enhancing the adaptability and realism of data-driven crowd simulation models is to incorporate visual information, including the scenario geometry and pedestrian locomotion. Consequently, this paper proposes a novel visual-information-driven (VID) crowd simulation model. The VID model predicts the pedestrian velocity at the next time step based on the prior social-visual information and motion data of an individual. A radar-geometry-locomotion method is established to extract the visual information of pedestrians. Moreover, a temporal convolutional network (TCN)-based deep learning model, named social-visual TCN, is developed for velocity prediction. The VID model is tested on three public pedestrian motion datasets with distinct geometries, i.e., corridor, corner, and T-junction. Both qualitative and quantitative metrics are employed to evaluate the VID model, and the results highlight the improved adaptability of the model across all three geometric scenarios. Overall, the proposed method demonstrates effectiveness in enhancing the adaptability of data-driven crowd models.
Read more4/10/2024

0
Probabilistic Image-Driven Traffic Modeling via Remote Sensing
Scott Workman, Armin Hadzic
This work addresses the task of modeling spatiotemporal traffic patterns directly from overhead imagery, which we refer to as image-driven traffic modeling. We extend this line of work and introduce a multi-modal, multi-task transformer-based segmentation architecture that can be used to create dense city-scale traffic models. Our approach includes a geo-temporal positional encoding module for integrating geo-temporal context and a probabilistic objective function for estimating traffic speeds that naturally models temporal variations. We evaluate our method extensively using the Dynamic Traffic Speeds (DTS) benchmark dataset and significantly improve the state-of-the-art. Finally, we introduce the DTS++ dataset to support mobility-related location adaptation experiments.
Read more7/19/2024
🚀
0
HabiCrowd: A High Performance Simulator for Crowd-Aware Visual Navigation
An Dinh Vuong, Toan Tien Nguyen, Minh Nhat VU, Baoru Huang, Dzung Nguyen, Huynh Thi Thanh Binh, Thieu Vo, Anh Nguyen
Visual navigation, a foundational aspect of Embodied AI (E-AI), has been significantly studied in the past few years. While many 3D simulators have been introduced to support visual navigation tasks, scarcely works have been directed towards combining human dynamics, creating the gap between simulation and real-world applications. Furthermore, current 3D simulators incorporating human dynamics have several limitations, particularly in terms of computational efficiency, which is a promise of E-AI simulators. To overcome these shortcomings, we introduce HabiCrowd, the first standard benchmark for crowd-aware visual navigation that integrates a crowd dynamics model with diverse human settings into photorealistic environments. Empirical evaluations demonstrate that our proposed human dynamics model achieves state-of-the-art performance in collision avoidance, while exhibiting superior computational efficiency compared to its counterparts. We leverage HabiCrowd to conduct several comprehensive studies on crowd-aware visual navigation tasks and human-robot interactions. The source code and data can be found at https://habicrowd.github.io/.
Read more7/30/2024
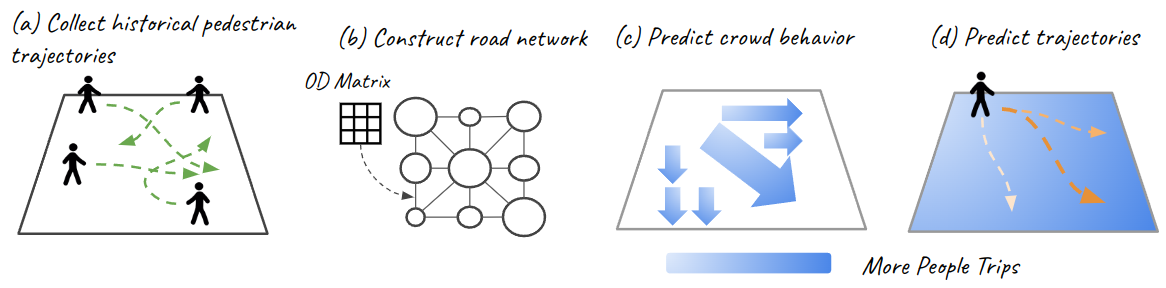
0
Enhancing Pedestrian Trajectory Prediction with Crowd Trip Information
Rei Tamaru, Pei Li, Bin Ran
Pedestrian trajectory prediction is essential for various applications in active traffic management, urban planning, traffic control, crowd management, and autonomous driving, aiming to enhance traffic safety and efficiency. Accurately predicting pedestrian trajectories requires a deep understanding of individual behaviors, social interactions, and road environments. Existing studies have developed various models to capture the influence of social interactions and road conditions on pedestrian trajectories. However, these approaches are limited by the lack of a comprehensive view of social interactions and road environments. To address these limitations and enhance the accuracy of pedestrian trajectory prediction, we propose a novel approach incorporating trip information as a new modality into pedestrian trajectory models. We propose RNTransformer, a generic model that utilizes crowd trip information to capture global information on social interactions. We incorporated RNTransformer with various socially aware local pedestrian trajectory prediction models to demonstrate its performance. Specifically, by leveraging a pre-trained RNTransformer when training different pedestrian trajectory prediction models, we observed improvements in performance metrics: a 1.3/2.2% enhancement in ADE/FDE on Social-LSTM, a 6.5/28.4% improvement on Social-STGCNN, and an 8.6/4.3% improvement on S-Implicit. Evaluation results demonstrate that RNTransformer significantly enhances the accuracy of various pedestrian trajectory prediction models across multiple datasets. Further investigation reveals that the RNTransformer effectively guides local models to more accurate directions due to the consideration of global information. By exploring crowd behavior within the road network, our approach shows great promise in improving pedestrian safety through accurate trajectory predictions.
Read more9/24/2024