Enhancing Trust in LLMs: Algorithms for Comparing and Interpreting LLMs
2406.01943
0
0
📶
Abstract
This paper surveys evaluation techniques to enhance the trustworthiness and understanding of Large Language Models (LLMs). As reliance on LLMs grows, ensuring their reliability, fairness, and transparency is crucial. We explore algorithmic methods and metrics to assess LLM performance, identify weaknesses, and guide development towards more trustworthy applications. Key evaluation metrics include Perplexity Measurement, NLP metrics (BLEU, ROUGE, METEOR, BERTScore, GLEU, Word Error Rate, Character Error Rate), Zero-Shot and Few-Shot Learning Performance, Transfer Learning Evaluation, Adversarial Testing, and Fairness and Bias Evaluation. We introduce innovative approaches like LLMMaps for stratified evaluation, Benchmarking and Leaderboards for competitive assessment, Stratified Analysis for in-depth understanding, Visualization of Blooms Taxonomy for cognitive level accuracy distribution, Hallucination Score for quantifying inaccuracies, Knowledge Stratification Strategy for hierarchical analysis, and Machine Learning Models for Hierarchy Generation. Human Evaluation is highlighted for capturing nuances that automated metrics may miss. These techniques form a framework for evaluating LLMs, aiming to enhance transparency, guide development, and establish user trust. Future papers will describe metric visualization and demonstrate each approach on practical examples.
Create account to get full access
Overview
• This research paper explores algorithms for comparing and interpreting large language models (LLMs) to enhance trust in their use.
• It addresses the imperative for transparency in LLMs, which are increasingly being deployed in high-stakes applications.
• The paper presents techniques for evaluating and interpreting the behavior of LLMs, with the goal of making them more trustworthy and accountable.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. As these models become more widely used, there is a growing need to ensure they are trustworthy and their behavior is well-understood.
This research paper proposes several algorithms and techniques to help address this challenge. The key ideas are:
-
Comparing LLMs: The researchers develop methods to systematically compare the outputs and behavior of different LLMs, even when they have been trained on different data or use different architectures. This allows users to better understand the similarities and differences between models.
-
Interpreting LLM Behavior: The paper introduces techniques to "open the black box" of LLMs and gain insights into how they make decisions and generate their outputs. This can help users understand the models' strengths, weaknesses, and potential biases.
-
Enhancing Transparency: By making LLMs more interpretable and comparable, the researchers aim to increase the transparency of these powerful AI systems. This can build trust and accountability, especially in high-stakes applications where the models' decisions can have significant real-world impacts.
The overarching goal is to develop tools and methods that allow users to better understand, evaluate, and ultimately trust the LLMs they rely on. This is an important step in ensuring these AI systems are deployed responsibly and ethically.
Technical Explanation
The paper presents several key technical contributions:
-
Comparing LLMs: The researchers develop a framework for systematically comparing LLMs, even when they have been trained on different datasets or use different architectures. This includes methods for aligning the output spaces of models, as well as techniques for measuring the similarity of their behavior on a wide range of tasks. (Unveiling LLM Evaluation-Focused Metrics: Challenges and Solutions, Large Language Models are Inconsistent Biased Evaluators)
-
Interpreting LLM Behavior: The paper introduces novel algorithms for interpreting the internal decision-making processes of LLMs. This includes techniques for extracting and visualizing the models' reasoning, as well as methods for identifying potential biases or inconsistencies in their outputs. (METAL: Towards Multilingual Meta-Evaluation, Exploring Precision-Recall to Assess Quality & Diversity)
-
Enhancing Transparency: By enabling more effective comparison and interpretation of LLMs, the researchers aim to increase the transparency and accountability of these powerful AI systems. This can help build trust in their use, particularly in high-stakes applications where the models' decisions can have significant real-world impacts. (TrustScore: A Reference-Free Evaluation of LLM Response Trustworthiness)
The paper presents a comprehensive set of techniques and algorithms to address the challenge of enhancing trust in LLMs. By making these models more interpretable and comparable, the researchers hope to pave the way for their responsible and ethical deployment in a wide range of applications.
Critical Analysis
The paper presents a well-designed and thorough set of techniques for comparing and interpreting LLMs. The researchers have clearly put a lot of thought and effort into addressing the critical issue of transparency and trust in these powerful AI systems.
One potential limitation of the research is that it focuses primarily on the technical aspects of LLM evaluation and interpretation, without delving deeply into the broader societal and ethical implications of these technologies. While the paper touches on the importance of trust and accountability, it could have explored these issues in greater depth, particularly in the context of high-stakes applications where the stakes are high.
Additionally, the paper does not address the potential challenges of implementing these techniques in real-world settings, such as the computational resources required or the challenges of scaling the methods to large-scale LLMs. Further research may be needed to address these practical considerations.
Overall, the paper represents a significant contribution to the field of LLM evaluation and interpretation. The proposed techniques have the potential to significantly improve the transparency and trustworthiness of these AI systems, which is crucial as they become more widely deployed in critical applications.
Conclusion
This research paper presents a comprehensive set of algorithms and techniques for comparing and interpreting large language models (LLMs) with the goal of enhancing trust in their use. The key contributions include methods for systematically comparing the behavior of different LLMs, as well as novel techniques for interpreting the internal decision-making processes of these AI systems.
By making LLMs more transparent and accountable, the researchers hope to pave the way for their responsible and ethical deployment in a wide range of applications, particularly in high-stakes domains where the models' decisions can have significant real-world impacts. While the paper focuses primarily on the technical aspects of LLM evaluation and interpretation, it represents an important step towards building trust and confidence in these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🚀
Unveiling LLM Evaluation Focused on Metrics: Challenges and Solutions
Taojun Hu, Xiao-Hua Zhou
0
0
Natural Language Processing (NLP) is witnessing a remarkable breakthrough driven by the success of Large Language Models (LLMs). LLMs have gained significant attention across academia and industry for their versatile applications in text generation, question answering, and text summarization. As the landscape of NLP evolves with an increasing number of domain-specific LLMs employing diverse techniques and trained on various corpus, evaluating performance of these models becomes paramount. To quantify the performance, it's crucial to have a comprehensive grasp of existing metrics. Among the evaluation, metrics which quantifying the performance of LLMs play a pivotal role. This paper offers a comprehensive exploration of LLM evaluation from a metrics perspective, providing insights into the selection and interpretation of metrics currently in use. Our main goal is to elucidate their mathematical formulations and statistical interpretations. We shed light on the application of these metrics using recent Biomedical LLMs. Additionally, we offer a succinct comparison of these metrics, aiding researchers in selecting appropriate metrics for diverse tasks. The overarching goal is to furnish researchers with a pragmatic guide for effective LLM evaluation and metric selection, thereby advancing the understanding and application of these large language models.
4/16/2024

Leveraging Large Language Models for NLG Evaluation: Advances and Challenges
Zhen Li, Xiaohan Xu, Tao Shen, Can Xu, Jia-Chen Gu, Yuxuan Lai, Chongyang Tao, Shuai Ma
0
0
In the rapidly evolving domain of Natural Language Generation (NLG) evaluation, introducing Large Language Models (LLMs) has opened new avenues for assessing generated content quality, e.g., coherence, creativity, and context relevance. This paper aims to provide a thorough overview of leveraging LLMs for NLG evaluation, a burgeoning area that lacks a systematic analysis. We propose a coherent taxonomy for organizing existing LLM-based evaluation metrics, offering a structured framework to understand and compare these methods. Our detailed exploration includes critically assessing various LLM-based methodologies, as well as comparing their strengths and limitations in evaluating NLG outputs. By discussing unresolved challenges, including bias, robustness, domain-specificity, and unified evaluation, this paper seeks to offer insights to researchers and advocate for fairer and more advanced NLG evaluation techniques.
6/13/2024
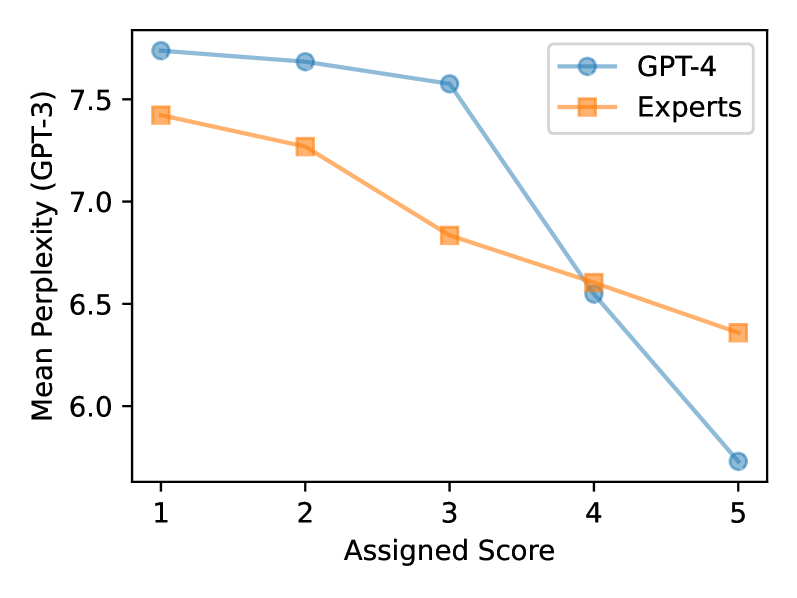
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024

METAL: Towards Multilingual Meta-Evaluation
Rishav Hada, Varun Gumma, Mohamed Ahmed, Kalika Bali, Sunayana Sitaram
0
0
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
4/3/2024