Enhancing Vehicle Aerodynamics with Deep Reinforcement Learning in Voxelised Models

0

Sign in to get full access
Overview
• This research paper explores the use of deep reinforcement learning techniques to enhance the aerodynamics of vehicles, particularly in the context of Formula One racing.
• The researchers developed a voxelized model of a vehicle, which divides the vehicle's surface into small, three-dimensional cubes called voxels. They then used deep reinforcement learning algorithms to optimize the shape and position of these voxels to minimize air resistance and improve overall aerodynamic performance.
Plain English Explanation
• The researchers wanted to find a way to make vehicles, like race cars, more aerodynamic and efficient. They did this by creating a detailed 3D model of a vehicle, breaking it down into tiny cubes called voxels.
• Then, they used a type of artificial intelligence called deep reinforcement learning to experiment with changing the shape and position of these voxels. The goal was to find the ideal configuration that would reduce air resistance and improve the vehicle's aerodynamics.
• Deep reinforcement learning is a technique where the AI system learns by trial and error, trying different actions and being rewarded or punished based on how well those actions work. In this case, the AI was trying different voxel arrangements to see which ones performed the best aerodynamically.
• By using this approach, the researchers were able to optimize the vehicle's shape in ways that would be difficult for human designers to identify on their own. This could lead to significant improvements in the performance and efficiency of vehicles, particularly in high-speed applications like Formula One racing.
Technical Explanation
• The researchers developed a voxelized model of a Formula One car, where the vehicle's surface was divided into a grid of small, three-dimensional cubes called voxels.
• They then used deep reinforcement learning algorithms to manipulate the position and shape of these voxels, with the goal of minimizing the vehicle's drag coefficient and improving overall aerodynamic performance.
• The deep reinforcement learning system was trained using a simulated environment, where it could experiment with different voxel configurations and receive immediate feedback on the resulting aerodynamic performance.
• The researchers used a novel reward function that combined the drag coefficient with other metrics, such as downforce and stability, to ensure the optimized designs were both efficient and drivable.
• Through extensive experimentation, the deep reinforcement learning system was able to identify voxel configurations that outperformed traditional aerodynamic designs, demonstrating the potential of this approach for enhancing vehicle aerodynamics.
Critical Analysis
• While the research demonstrates the potential of deep reinforcement learning for aerodynamic optimization, the authors acknowledge that the voxelized model may oversimplify the complex geometry of a real-world vehicle.
• Additionally, the simulated environment used for training may not fully capture the nuances of real-world aerodynamics, and the researchers suggest that further validation and testing in physical wind tunnels or on-track testing would be necessary to confirm the effectiveness of the optimized designs.
• The authors also note that the computational resources required for the deep reinforcement learning process may be a practical limitation, particularly for smaller teams or organizations without access to powerful hardware and computing infrastructure.
• Nonetheless, the research represents an important step forward in the use of advanced AI techniques for enhancing vehicle aerodynamics, and the insights gained could have broader implications for the design and optimization of a wide range of engineering systems.
Conclusion
• This research demonstrates the potential of deep reinforcement learning to revolutionize the way vehicle aerodynamics are optimized, particularly in the context of high-performance applications like Formula One racing.
• By utilizing a voxelized model and experimenting with different voxel configurations, the deep reinforcement learning system was able to identify aerodynamic designs that outperformed traditional approaches.
• While there are still some practical limitations to overcome, this research highlights the growing importance of AI-driven optimization techniques in the field of engineering and design, and the significant benefits they can offer in terms of improving the performance and efficiency of complex systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enhancing Vehicle Aerodynamics with Deep Reinforcement Learning in Voxelised Models
Jignesh Patel, Yannis Spyridis, Vasileios Argyriou
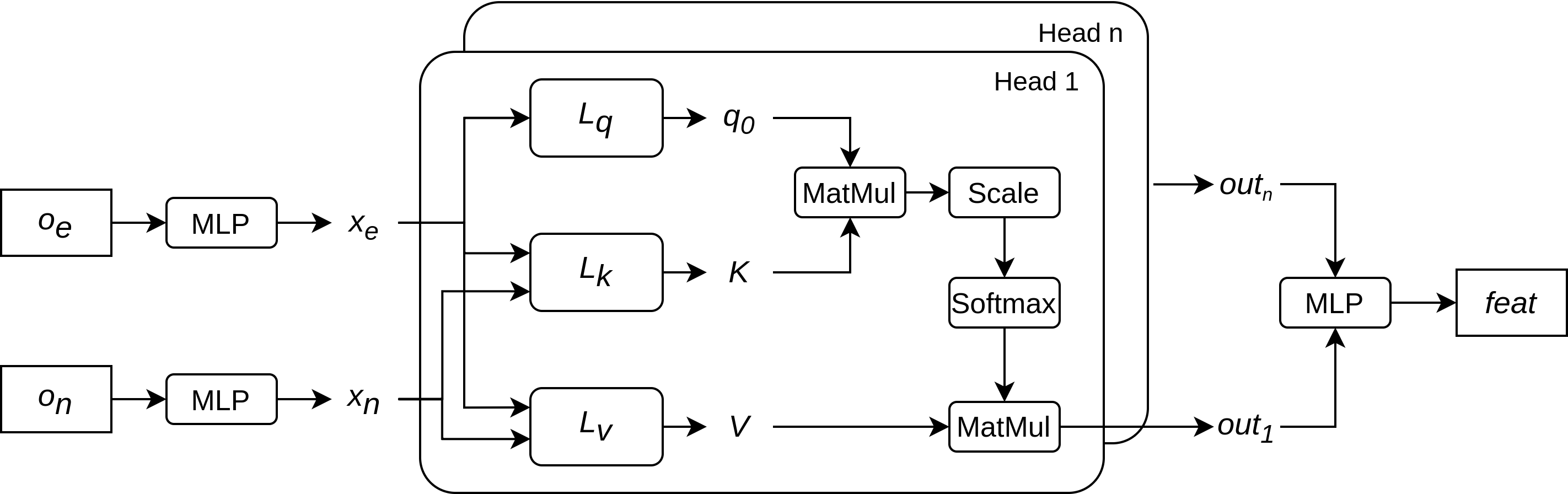
Aerodynamic design optimisation plays a crucial role in improving the performance and efficiency of automotive vehicles. This paper presents a novel approach for aerodynamic optimisation in car design using deep reinforcement learning (DRL). Traditional optimisation methods often face challenges in handling the complexity of the design space and capturing non-linear relationships between design parameters and aerodynamic performance metrics. This study addresses these challenges by employing DRL to learn optimal aerodynamic design strategies in a voxelised model representation. The proposed approach utilises voxelised models to discretise the vehicle geometry into a grid of voxels, allowing for a detailed representation of the aerodynamic flow field. The Proximal Policy Optimisation (PPO) algorithm is then employed to train a DRL agent to optimise the design parameters of the vehicle with respect to drag force, kinetic energy, and voxel collision count. Experimental results demonstrate the effectiveness and efficiency of the proposed approach in achieving significant results in aerodynamic performance. The findings highlight the potential of DRL techniques for addressing complex aerodynamic design optimisation problems in automotive engineering, with implications for improving vehicle performance, fuel efficiency, and environmental sustainability.
Read more5/21/2024
0
Demystifying the Physics of Deep Reinforcement Learning-Based Autonomous Vehicle Decision-Making
Hanxi Wan, Pei Li, Arpan Kusari
With the advent of universal function approximators in the domain of reinforcement learning, the number of practical applications leveraging deep reinforcement learning (DRL) has exploded. Decision-making in autonomous vehicles (AVs) has emerged as a chief application among them, taking the sensor data or the higher-order kinematic variables as the input and providing a discrete choice or continuous control output. There has been a continuous effort to understand the black-box nature of the DRL models, but so far, there hasn't been any discussion (to the best of authors' knowledge) about how the models learn the physical process. This presents an overwhelming limitation that restricts the real-world deployment of DRL in AVs. Therefore, in this research work, we try to decode the knowledge learnt by the attention-based DRL framework about the physical process. We use a continuous proximal policy optimization-based DRL algorithm as the baseline model and add a multi-head attention framework in an open-source AV simulation environment. We provide some analytical techniques for discussing the interpretability of the trained models in terms of explainability and causality for spatial and temporal correlations. We show that the weights in the first head encode the positions of the neighboring vehicles while the second head focuses on the leader vehicle exclusively. Also, the ego vehicle's action is causally dependent on the vehicles in the target lane spatially and temporally. Through these findings, we reliably show that these techniques can help practitioners decipher the results of the DRL algorithms.
Read more6/14/2024
🤿
0
Research on Autonomous Driving Decision-making Strategies based Deep Reinforcement Learning
Zixiang Wang, Hao Yan, Changsong Wei, Junyu Wang, Shi Bo, Minheng Xiao
The behavior decision-making subsystem is a key component of the autonomous driving system, which reflects the decision-making ability of the vehicle and the driver, and is an important symbol of the high-level intelligence of the vehicle. However, the existing rule-based decision-making schemes are limited by the prior knowledge of designers, and it is difficult to cope with complex and changeable traffic scenarios. In this work, an advanced deep reinforcement learning model is adopted, which can autonomously learn and optimize driving strategies in a complex and changeable traffic environment by modeling the driving decision-making process as a reinforcement learning problem. Specifically, we used Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) for comparative experiments. DQN guides the agent to choose the best action by approximating the state-action value function, while PPO improves the decision-making quality by optimizing the policy function. We also introduce improvements in the design of the reward function to promote the robustness and adaptability of the model in real-world driving situations. Experimental results show that the decision-making strategy based on deep reinforcement learning has better performance than the traditional rule-based method in a variety of driving tasks.
Read more8/7/2024

0
Model-Based Reinforcement Learning for Control of Strongly-Disturbed Unsteady Aerodynamic Flows
Zhecheng Liu (University of California, Los Angeles), Diederik Beckers (California Institute of Technology), Jeff D. Eldredge (University of California, Los Angeles)
The intrinsic high dimension of fluid dynamics is an inherent challenge to control of aerodynamic flows, and this is further complicated by a flow's nonlinear response to strong disturbances. Deep reinforcement learning, which takes advantage of the exploratory aspects of reinforcement learning (RL) and the rich nonlinearity of a deep neural network, provides a promising approach to discover feasible control strategies. However, the typical model-free approach to reinforcement learning requires a significant amount of interaction between the flow environment and the RL agent during training, and this high training cost impedes its development and application. In this work, we propose a model-based reinforcement learning (MBRL) approach by incorporating a novel reduced-order model as a surrogate for the full environment. The model consists of a physics-augmented autoencoder, which compresses high-dimensional CFD flow field snaphsots into a three-dimensional latent space, and a latent dynamics model that is trained to accurately predict the long-time dynamics of trajectories in the latent space in response to action sequences. The robustness and generalizability of the model is demonstrated in two distinct flow environments, a pitching airfoil in a highly disturbed environment and a vertical-axis wind turbine in a disturbance-free environment. Based on the trained model in the first problem, we realize an MBRL strategy to mitigate lift variation during gust-airfoil encounters. We demonstrate that the policy learned in the reduced-order environment translates to an effective control strategy in the full CFD environment.
Read more8/28/2024