Enhancing Visual-Language Modality Alignment in Large Vision Language Models via Self-Improvement
2405.15973
0
0
👀
Abstract
Large vision-language models (LVLMs) have achieved impressive results in various visual question-answering and reasoning tasks through vision instruction tuning on specific datasets. However, there is still significant room for improvement in the alignment between visual and language modalities. Previous methods to enhance this alignment typically require external models or data, heavily depending on their capabilities and quality, which inevitably sets an upper bound on performance. In this paper, we propose SIMA, a framework that enhances visual and language modality alignment through self-improvement, eliminating the needs for external models or data. SIMA leverages prompts from existing vision instruction tuning datasets to self-generate responses and employs an in-context self-critic mechanism to select response pairs for preference tuning. The key innovation is the introduction of three vision metrics during the in-context self-critic process, which can guide the LVLM in selecting responses that enhance image comprehension. Through experiments across 14 hallucination and comprehensive benchmarks, we demonstrate that SIMA not only improves model performance across all benchmarks but also achieves superior modality alignment, outperforming previous approaches.
Create account to get full access
Overview
- Large vision-language models (LVLMs) have achieved impressive results in visual question-answering and reasoning tasks through vision instruction tuning on specific datasets.
- However, there is still significant room for improvement in the alignment between visual and language modalities.
- Previous methods to enhance this alignment typically require external models or data, which sets an upper bound on performance.
Plain English Explanation
Large vision-language models are AI systems that can understand and reason about both visual and textual information. They have shown impressive results in tasks like answering questions about images. However, these models still struggle to fully align the visual and language parts of their knowledge.
Previous attempts to improve this alignment have relied on external models or data sources. This means the performance of these methods is limited by the quality and capabilities of those external components.
In this paper, the researchers propose a new framework called SIMA that can enhance the alignment between visual and language modalities without needing any external models or data. SIMA uses the prompts from existing vision instruction datasets to generate responses and then employs an internal "self-critic" mechanism to select the best responses. This self-improvement approach allows SIMA to enhance the model's understanding of images without relying on external factors.
Technical Explanation
The core innovation of the SIMA framework is the introduction of three "vision metrics" that guide the in-context self-critic mechanism during the preference tuning process. These vision metrics help the LVLM select responses that demonstrate better comprehension of the input images.
Through extensive experiments across 14 different benchmarks, the researchers show that SIMA not only improves the model's performance on a wide range of tasks, but also achieves superior modality alignment compared to previous approaches that relied on external models or data, such as Calibrated Self-Rewarding Vision-Language Models, Self-Supervised Visual Preference Alignment, and FGAIF: Aligning Large Vision-Language Models.
Critical Analysis
The paper provides a compelling solution to the challenge of improving visual-language modality alignment in LVLMs without relying on external models or data. By leveraging the self-critic mechanism and the novel vision metrics, SIMA demonstrates the ability to self-improve and enhance the model's understanding of visual information.
However, the paper does not discuss the potential limitations of the SIMA framework, such as the scalability of the self-critic process or the generalization of the vision metrics to a wider range of visual tasks and datasets. Additionally, the paper could have explored the potential shortcomings of LVLMs in certain visual reasoning or comprehension tasks that may not be fully addressed by the SIMA approach.
Conclusion
The SIMA framework proposed in this paper represents a significant step forward in enhancing the alignment between visual and language modalities in large vision-language models. By eliminating the need for external models or data, SIMA enables self-improvement and superior modality alignment, which can have far-reaching implications for the development of more robust and capable AI systems that can seamlessly integrate visual and textual understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

X-VILA: Cross-Modality Alignment for Large Language Model
Hanrong Ye, De-An Huang, Yao Lu, Zhiding Yu, Wei Ping, Andrew Tao, Jan Kautz, Song Han, Dan Xu, Pavlo Molchanov, Hongxu Yin
0
0
We introduce X-VILA, an omni-modality model designed to extend the capabilities of large language models (LLMs) by incorporating image, video, and audio modalities. By aligning modality-specific encoders with LLM inputs and diffusion decoders with LLM outputs, X-VILA achieves cross-modality understanding, reasoning, and generation. To facilitate this cross-modality alignment, we curate an effective interleaved any-to-any modality instruction-following dataset. Furthermore, we identify a significant problem with the current cross-modality alignment method, which results in visual information loss. To address the issue, we propose a visual alignment mechanism with a visual embedding highway module. We then introduce a resource-efficient recipe for training X-VILA, that exhibits proficiency in any-to-any modality conversation, surpassing previous approaches by large margins. X-VILA also showcases emergent properties across modalities even in the absence of similar training data. The project will be made open-source.
5/30/2024
Self-Supervised Visual Preference Alignment
Ke Zhu, Liang Zhao, Zheng Ge, Xiangyu Zhang
0
0
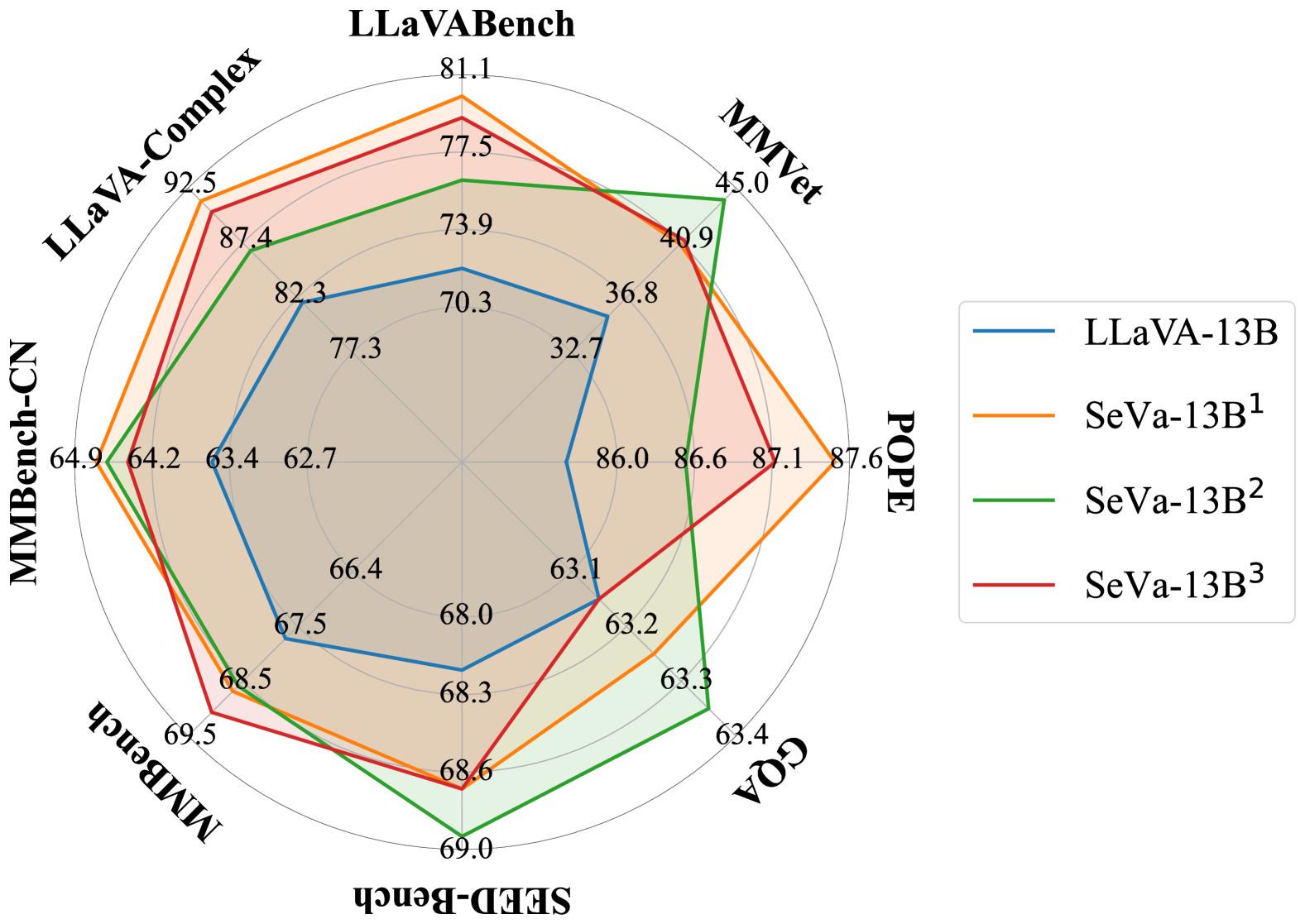
This paper makes the first attempt towards unsupervised preference alignment in Vision-Language Models (VLMs). We generate chosen and rejected responses with regard to the original and augmented image pairs, and conduct preference alignment with direct preference optimization. It is based on a core idea: properly designed augmentation to the image input will induce VLM to generate false but hard negative responses, which helps the model to learn from and produce more robust and powerful answers. The whole pipeline no longer hinges on supervision from GPT4 or human involvement during alignment, and is highly efficient with few lines of code. With only 8k randomly sampled unsupervised data, it achieves 90% relative score to GPT-4 on complex reasoning in LLaVA-Bench, and improves LLaVA-7B/13B by 6.7%/5.6% score on complex multi-modal benchmark MM-Vet. Visualizations shows its improved ability to align with user-intentions. A series of ablations are firmly conducted to reveal the latent mechanism of the approach, which also indicates its potential towards further scaling. Code will be available.
4/17/2024
Enhancing Large Vision Language Models with Self-Training on Image Comprehension
Yihe Deng, Pan Lu, Fan Yin, Ziniu Hu, Sheng Shen, James Zou, Kai-Wei Chang, Wei Wang
0
0
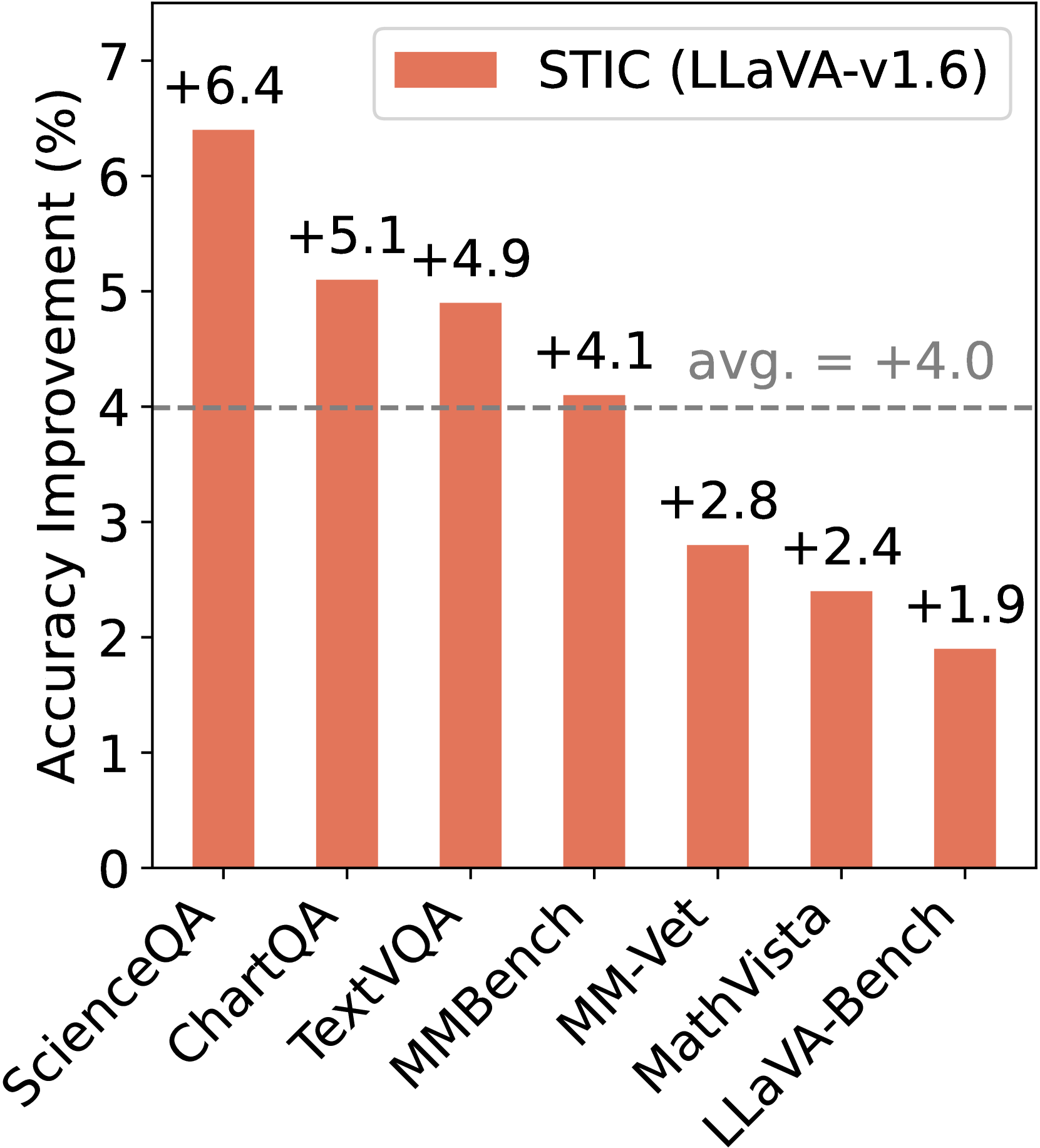
Large vision language models (LVLMs) integrate large language models (LLMs) with pre-trained vision encoders, thereby activating the perception capability of the model to understand image inputs for different queries and conduct subsequent reasoning. Improving this capability requires high-quality vision-language data, which is costly and labor-intensive to acquire. Self-training approaches have been effective in single-modal settings to alleviate the need for labeled data by leveraging model's own generation. However, effective self-training remains a challenge regarding the unique visual perception and reasoning capability of LVLMs. To address this, we introduce Self-Training on Image Comprehension (STIC), which emphasizes a self-training approach specifically for image comprehension. First, the model self-constructs a preference dataset for image descriptions using unlabeled images. Preferred responses are generated through a step-by-step prompt, while dis-preferred responses are generated from either corrupted images or misleading prompts. To further self-improve reasoning on the extracted visual information, we let the model reuse a small portion of existing instruction-tuning data and append its self-generated image descriptions to the prompts. We validate the effectiveness of STIC across seven different benchmarks, demonstrating substantial performance gains of 4.0% on average while using 70% less supervised fine-tuning data than the current method. Further studies investigate various components of STIC and highlight its potential to leverage vast quantities of unlabeled images for self-training. Code and data are made publicly available.
5/31/2024
👀
Calibrated Self-Rewarding Vision Language Models
Yiyang Zhou, Zhiyuan Fan, Dongjie Cheng, Sihan Yang, Zhaorun Chen, Chenhang Cui, Xiyao Wang, Yun Li, Linjun Zhang, Huaxiu Yao
0
0
Large Vision-Language Models (LVLMs) have made substantial progress by integrating pre-trained large language models (LLMs) and vision models through instruction tuning. Despite these advancements, LVLMs often exhibit the hallucination phenomenon, where generated text responses appear linguistically plausible but contradict the input image, indicating a misalignment between image and text pairs. This misalignment arises because the model tends to prioritize textual information over visual input, even when both the language model and visual representations are of high quality. Existing methods leverage additional models or human annotations to curate preference data and enhance modality alignment through preference optimization. These approaches may not effectively reflect the target LVLM's preferences, making the curated preferences easily distinguishable. Our work addresses these challenges by proposing the Calibrated Self-Rewarding (CSR) approach, which enables the model to self-improve by iteratively generating candidate responses, evaluating the reward for each response, and curating preference data for fine-tuning. In the reward modeling, we employ a step-wise strategy and incorporate visual constraints into the self-rewarding process to place greater emphasis on visual input. Empirical results demonstrate that CSR enhances performance and reduces hallucinations across ten benchmarks and tasks, achieving substantial improvements over existing methods by 7.62%. Our empirical results are further supported by rigorous theoretical analysis, under mild assumptions, verifying the effectiveness of introducing visual constraints into the self-rewarding paradigm. Additionally, CSR shows compatibility with different vision-language models and the ability to incrementally improve performance through iterative fine-tuning. Our data and code are available at https://github.com/YiyangZhou/CSR.
6/3/2024