Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
2401.06209
2
0

Abstract
Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP). Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. To understand the roots of these errors, we explore the gap between the visual embedding space of CLIP and vision-only self-supervised learning. We identify ''CLIP-blind pairs'' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark. MMVP exposes areas where state-of-the-art systems, including GPT-4V, struggle with straightforward questions across nine basic visual patterns, often providing incorrect answers and hallucinated explanations. We further evaluate various CLIP-based vision-and-language models and found a notable correlation between visual patterns that challenge CLIP models and those problematic for multimodal LLMs. As an initial effort to address these issues, we propose a Mixture of Features (MoF) approach, demonstrating that integrating vision self-supervised learning features with MLLMs can significantly enhance their visual grounding capabilities. Together, our research suggests visual representation learning remains an open challenge, and accurate visual grounding is crucial for future successful multimodal systems.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Explores the visual shortcomings of multimodal large language models (LLMs)
- Introduces the Multimodal Visual Patterns (MMVP) benchmark to identify "CLIP-blind" image-text pairs
- Examines the performance of several prominent multimodal LLMs on the MMVP benchmark
Plain English Explanation
Multimodal large language models (LLMs) are powerful AI systems that can process and understand both text and images. However, this paper suggests that these models may have significant blind spots when it comes to visual perception.
The researchers created a new benchmark called the Multimodal Visual Patterns (MMVP) to test the visual capabilities of multimodal LLMs. The MMVP is designed to identify "CLIP-blind" image-text pairs - that is, pairs that are easily recognized by the CLIP model (a state-of-the-art visual-language model), but prove challenging for other multimodal LLMs.
By evaluating several prominent multimodal LLMs on the MMVP benchmark, the researchers were able to uncover notable differences in their visual understanding capabilities. This suggests that while these models excel at language tasks, they may still struggle with certain types of visual perception and reasoning.
Technical Explanation
The paper begins by highlighting the impressive progress made in multimodal large language models - models that can process and understand both text and images. However, the authors argue that these models may have significant blind spots when it comes to visual perception.
To explore this, the researchers introduce the Multimodal Visual Patterns (MMVP) benchmark. The MMVP is designed to identify "CLIP-blind" image-text pairs - that is, pairs that are easily recognized by the CLIP model (a state-of-the-art visual-language model), but prove challenging for other multimodal LLMs.
The authors describe their process for finding these CLIP-blind pairs, which involves training a CLIP-based model to identify image-text pairs and then selecting pairs that the model can recognize but other multimodal LLMs struggle with.
The paper then evaluates the performance of several prominent multimodal LLMs, including CLIP, METER, and BEIT, on the MMVP benchmark. The results reveal notable differences in the visual understanding capabilities of these models, suggesting that while they excel at language tasks, they may still struggle with certain types of visual perception and reasoning.
Critical Analysis
The paper provides a valuable survey of current multimodal large language models and highlights an important limitation in their visual understanding capabilities. The MMVP benchmark is a clever and well-designed tool for uncovering these shortcomings.
However, the paper does not delve deeply into the specific reasons why these models struggle with certain types of visual patterns. More research is needed to understand the underlying architectural or training factors that contribute to these blind spots.
Additionally, the paper focuses on a relatively narrow set of multimodal LLMs and may not capture the full range of visual capabilities across the field. Expanding the evaluation to include a wider variety of models could provide a more comprehensive understanding of the state of the art in multimodal AI.
Conclusion
This paper offers a thought-provoking exploration of the visual shortcomings of multimodal large language models. By introducing the MMVP benchmark and evaluating several prominent models, the researchers have uncovered important limitations in the visual understanding capabilities of these powerful AI systems.
The findings from this work highlight the need for continued research and development in the field of multimodal AI, as there is still much work to be done to bridge the gap between human-level visual perception and the abilities of current state-of-the-art models. As the field continues to advance, it will be crucial to address these visual blind spots to unlock the full potential of multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
From Image to Video, what do we need in multimodal LLMs?
Suyuan Huang, Haoxin Zhang, Yan Gao, Yao Hu, Zengchang Qin
0
0
Multimodal Large Language Models (MLLMs) have demonstrated profound capabilities in understanding multimodal information, covering from Image LLMs to the more complex Video LLMs. Numerous studies have illustrated their exceptional cross-modal comprehension. Recently, integrating video foundation models with large language models to build a comprehensive video understanding system has been proposed to overcome the limitations of specific pre-defined vision tasks. However, the current advancements in Video LLMs tend to overlook the foundational contributions of Image LLMs, often opting for more complicated structures and a wide variety of multimodal data for pre-training. This approach significantly increases the costs associated with these methods.In response to these challenges, this work introduces an efficient method that strategically leverages the priors of Image LLMs, facilitating a resource-efficient transition from Image to Video LLMs. We propose RED-VILLM, a Resource-Efficient Development pipeline for Video LLMs from Image LLMs, which utilizes a temporal adaptation plug-and-play structure within the image fusion module of Image LLMs. This adaptation extends their understanding capabilities to include temporal information, enabling the development of Video LLMs that not only surpass baseline performances but also do so with minimal instructional data and training resources. Our approach highlights the potential for a more cost-effective and scalable advancement in multimodal models, effectively building upon the foundational work of Image LLMs.
4/19/2024
Revisiting the Adversarial Robustness of Vision Language Models: a Multimodal Perspective
Wanqi Zhou, Shuanghao Bai, Qibin Zhao, Badong Chen
0
0
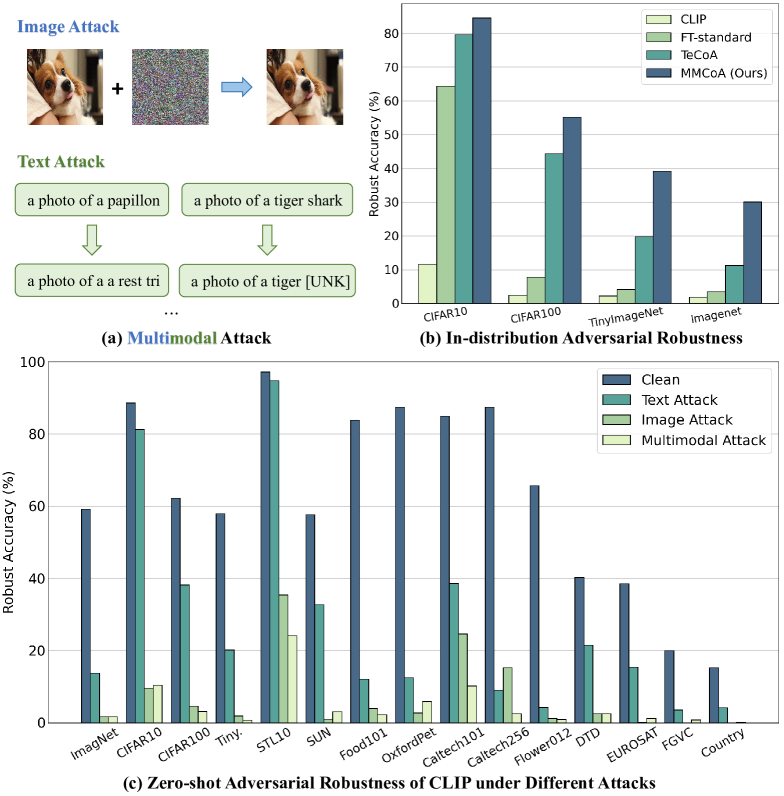
Pretrained vision-language models (VLMs) like CLIP have shown impressive generalization performance across various downstream tasks, yet they remain vulnerable to adversarial attacks. While prior research has primarily concentrated on improving the adversarial robustness of image encoders to guard against attacks on images, the exploration of text-based and multimodal attacks has largely been overlooked. In this work, we initiate the first known and comprehensive effort to study adapting vision-language models for adversarial robustness under the multimodal attack. Firstly, we introduce a multimodal attack strategy and investigate the impact of different attacks. We then propose a multimodal contrastive adversarial training loss, aligning the clean and adversarial text embeddings with the adversarial and clean visual features, to enhance the adversarial robustness of both image and text encoders of CLIP. Extensive experiments on 15 datasets across two tasks demonstrate that our method significantly improves the adversarial robustness of CLIP. Interestingly, we find that the model fine-tuned against multimodal adversarial attacks exhibits greater robustness than its counterpart fine-tuned solely against image-based attacks, even in the context of image attacks, which may open up new possibilities for enhancing the security of VLMs.
5/1/2024
💬
BLINK: Multimodal Large Language Models Can See but Not Perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A. Smith, Wei-Chiu Ma, Ranjay Krishna
0
0
We introduce Blink, a new benchmark for multimodal language models (LLMs) that focuses on core visual perception abilities not found in other evaluations. Most of the Blink tasks can be solved by humans within a blink (e.g., relative depth estimation, visual correspondence, forensics detection, and multi-view reasoning). However, we find these perception-demanding tasks cast significant challenges for current multimodal LLMs because they resist mediation through natural language. Blink reformats 14 classic computer vision tasks into 3,807 multiple-choice questions, paired with single or multiple images and visual prompting. While humans get 95.70% accuracy on average, Blink is surprisingly challenging for existing multimodal LLMs: even the best-performing GPT-4V and Gemini achieve accuracies of 51.26% and 45.72%, only 13.17% and 7.63% higher than random guessing, indicating that such perception abilities have not emerged yet in recent multimodal LLMs. Our analysis also highlights that specialist CV models could solve these problems much better, suggesting potential pathways for future improvements. We believe Blink will stimulate the community to help multimodal LLMs catch up with human-level visual perception.
5/7/2024