Multimodal Large Language Model is a Human-Aligned Annotator for Text-to-Image Generation
2404.15100
0
0
💬
Abstract
Recent studies have demonstrated the exceptional potentials of leveraging human preference datasets to refine text-to-image generative models, enhancing the alignment between generated images and textual prompts. Despite these advances, current human preference datasets are either prohibitively expensive to construct or suffer from a lack of diversity in preference dimensions, resulting in limited applicability for instruction tuning in open-source text-to-image generative models and hinder further exploration. To address these challenges and promote the alignment of generative models through instruction tuning, we leverage multimodal large language models to create VisionPrefer, a high-quality and fine-grained preference dataset that captures multiple preference aspects. We aggregate feedback from AI annotators across four aspects: prompt-following, aesthetic, fidelity, and harmlessness to construct VisionPrefer. To validate the effectiveness of VisionPrefer, we train a reward model VP-Score over VisionPrefer to guide the training of text-to-image generative models and the preference prediction accuracy of VP-Score is comparable to human annotators. Furthermore, we use two reinforcement learning methods to supervised fine-tune generative models to evaluate the performance of VisionPrefer, and extensive experimental results demonstrate that VisionPrefer significantly improves text-image alignment in compositional image generation across diverse aspects, e.g., aesthetic, and generalizes better than previous human-preference metrics across various image distributions. Moreover, VisionPrefer indicates that the integration of AI-generated synthetic data as a supervisory signal is a promising avenue for achieving improved alignment with human preferences in vision generative models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Recent studies have shown the potential of using human preference datasets to improve text-to-image generative models and align the generated images with the original text prompts.
- However, current human preference datasets are either expensive to create or lack diversity in the types of preferences they capture, limiting their usefulness for training open-source text-to-image models.
- To address these challenges, the researchers developed VisionPrefer, a high-quality and fine-grained preference dataset that captures multiple aspects of user preferences.
Plain English Explanation
Researchers have discovered that using datasets of human preferences can help improve the quality and accuracy of text-to-image generation models. These models can generate images based on text prompts, but the images don't always match the prompt perfectly. By training the models on datasets that show what humans prefer, the models can learn to generate images that are more closely aligned with the original text.
However, creating these human preference datasets is often very expensive and time-consuming. Additionally, the existing datasets don't capture a wide enough range of preferences, so the models trained on them have limited abilities. To solve this problem, the researchers in this study used large language models to build a new dataset called VisionPrefer. This dataset includes feedback on things like how well the generated image matches the text prompt, how aesthetically pleasing it is, how realistic it is, and whether it contains anything harmful or inappropriate.
By training text-to-image models using VisionPrefer, the researchers were able to significantly improve the alignment between the generated images and the original text prompts. This means the models can now produce images that are much closer to what a human would expect based on the prompt. The researchers also found that using synthetic data generated by AI models as additional training input can further enhance the models' ability to match human preferences.
Technical Explanation
The researchers leveraged the capabilities of multimodal large language models to create VisionPrefer, a comprehensive dataset that captures multiple dimensions of human preferences for text-to-image generation. They aggregated feedback from AI annotators across four key aspects: prompt-following, aesthetic, fidelity, and harmlessness.
To validate the effectiveness of VisionPrefer, the researchers trained a reward model called VP-Score on the dataset. They found that the prediction accuracy of VP-Score was comparable to that of human annotators, demonstrating the dataset's ability to capture nuanced human preferences.
Furthermore, the researchers used two reinforcement learning methods to fine-tune text-to-image generative models using VisionPrefer. Their extensive experiments showed that VisionPrefer significantly improved the alignment between the generated images and the original text prompts across various aspects, such as aesthetics. VisionPrefer also outperformed previous human-preference metrics in terms of generalization across different image distributions.
The researchers also found that integrating synthetic data generated by AI models as a supervisory signal is a promising approach for achieving better alignment with human preferences in vision generative models.
Critical Analysis
The researchers acknowledge that while VisionPrefer represents a significant advancement in the field, there are still some limitations and areas for further research. For example, the dataset may not capture the full range of human preferences, and the AI annotators used to create it may have biases or blindspots.
Additionally, the researchers did not explore the potential ethical implications of using large language models and synthetic data to generate images, which could raise concerns about the creation of misleading or harmful content. Future research may need to address these ethical considerations more explicitly.
Another area for further exploration is the integration of VisionPrefer with personalized multimodal generation techniques, which could potentially lead to even more tailored and satisfying text-to-image generation for individual users.
Conclusion
The development of VisionPrefer represents a significant advancement in the field of text-to-image generation, as it provides a high-quality dataset that captures a wide range of human preferences. By using this dataset to fine-tune generative models, researchers have been able to significantly improve the alignment between generated images and their corresponding text prompts.
This work has important implications for the development of more accurate and user-friendly text-to-image generation tools, which could have applications in areas like creative design, education, and personal expression. The researchers' finding that integrating synthetic data can further enhance these models' ability to match human preferences is also a promising direction for future research.
Overall, the VisionPrefer dataset and the techniques used to create and leverage it represent an important step forward in the quest to develop text-to-image generation models that truly align with human preferences and expectations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
🤔
MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Brandon McKinzie, Zhe Gan, Jean-Philippe Fauconnier, Sam Dodge, Bowen Zhang, Philipp Dufter, Dhruti Shah, Xianzhi Du, Futang Peng, Floris Weers, Anton Belyi, Haotian Zhang, Karanjeet Singh, Doug Kang, Ankur Jain, Hongyu H`e, Max Schwarzer, Tom Gunter, Xiang Kong, Aonan Zhang, Jianyu Wang, Chong Wang, Nan Du, Tao Lei, Sam Wiseman, Guoli Yin, Mark Lee, Zirui Wang, Ruoming Pang, Peter Grasch, Alexander Toshev, Yinfei Yang
0
0
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, including both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
4/22/2024
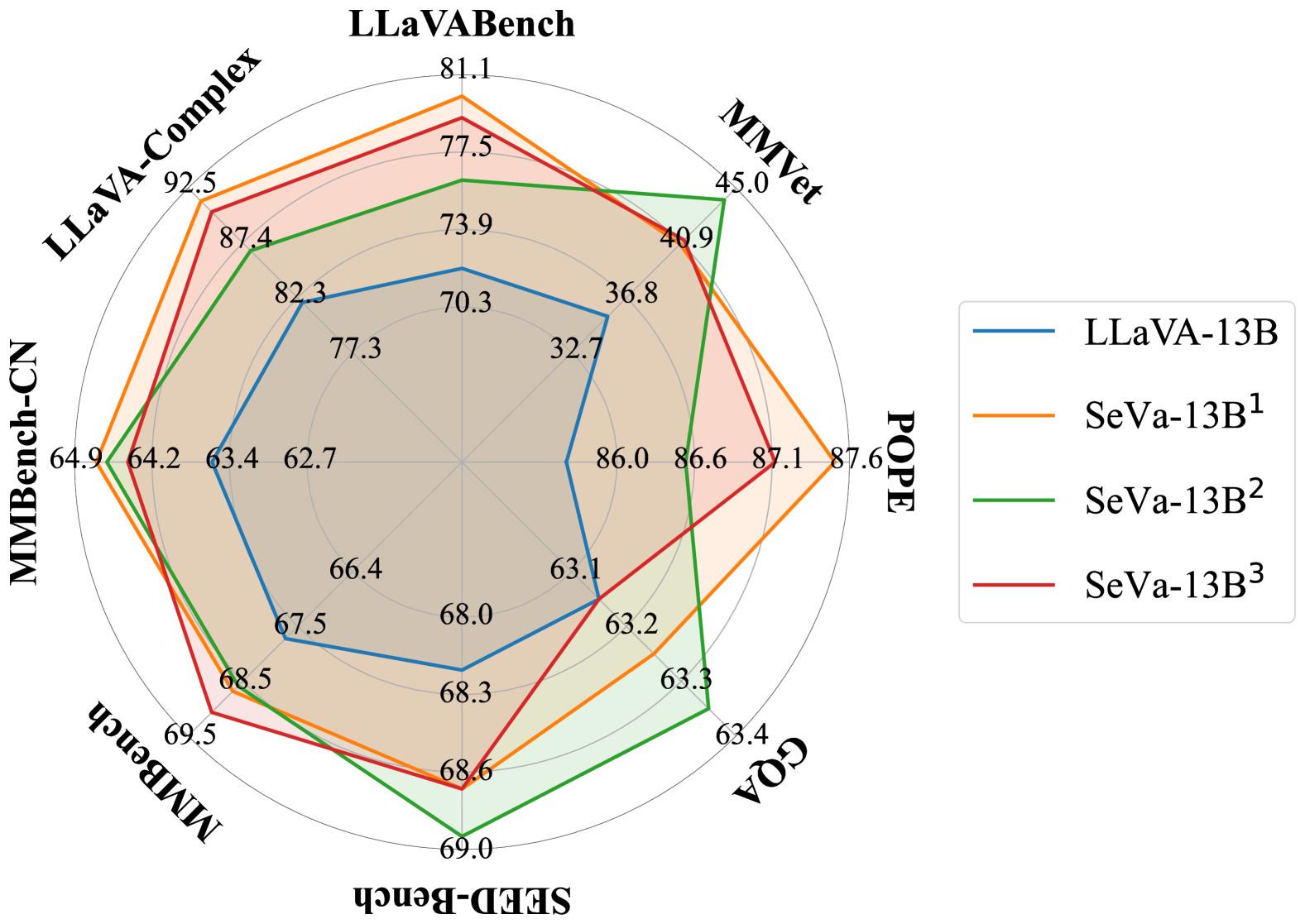
Self-Supervised Visual Preference Alignment
Ke Zhu, Liang Zhao, Zheng Ge, Xiangyu Zhang
0
0
This paper makes the first attempt towards unsupervised preference alignment in Vision-Language Models (VLMs). We generate chosen and rejected responses with regard to the original and augmented image pairs, and conduct preference alignment with direct preference optimization. It is based on a core idea: properly designed augmentation to the image input will induce VLM to generate false but hard negative responses, which helps the model to learn from and produce more robust and powerful answers. The whole pipeline no longer hinges on supervision from GPT4 or human involvement during alignment, and is highly efficient with few lines of code. With only 8k randomly sampled unsupervised data, it achieves 90% relative score to GPT-4 on complex reasoning in LLaVA-Bench, and improves LLaVA-7B/13B by 6.7%/5.6% score on complex multi-modal benchmark MM-Vet. Visualizations shows its improved ability to align with user-intentions. A series of ablations are firmly conducted to reveal the latent mechanism of the approach, which also indicates its potential towards further scaling. Code will be available.
4/17/2024
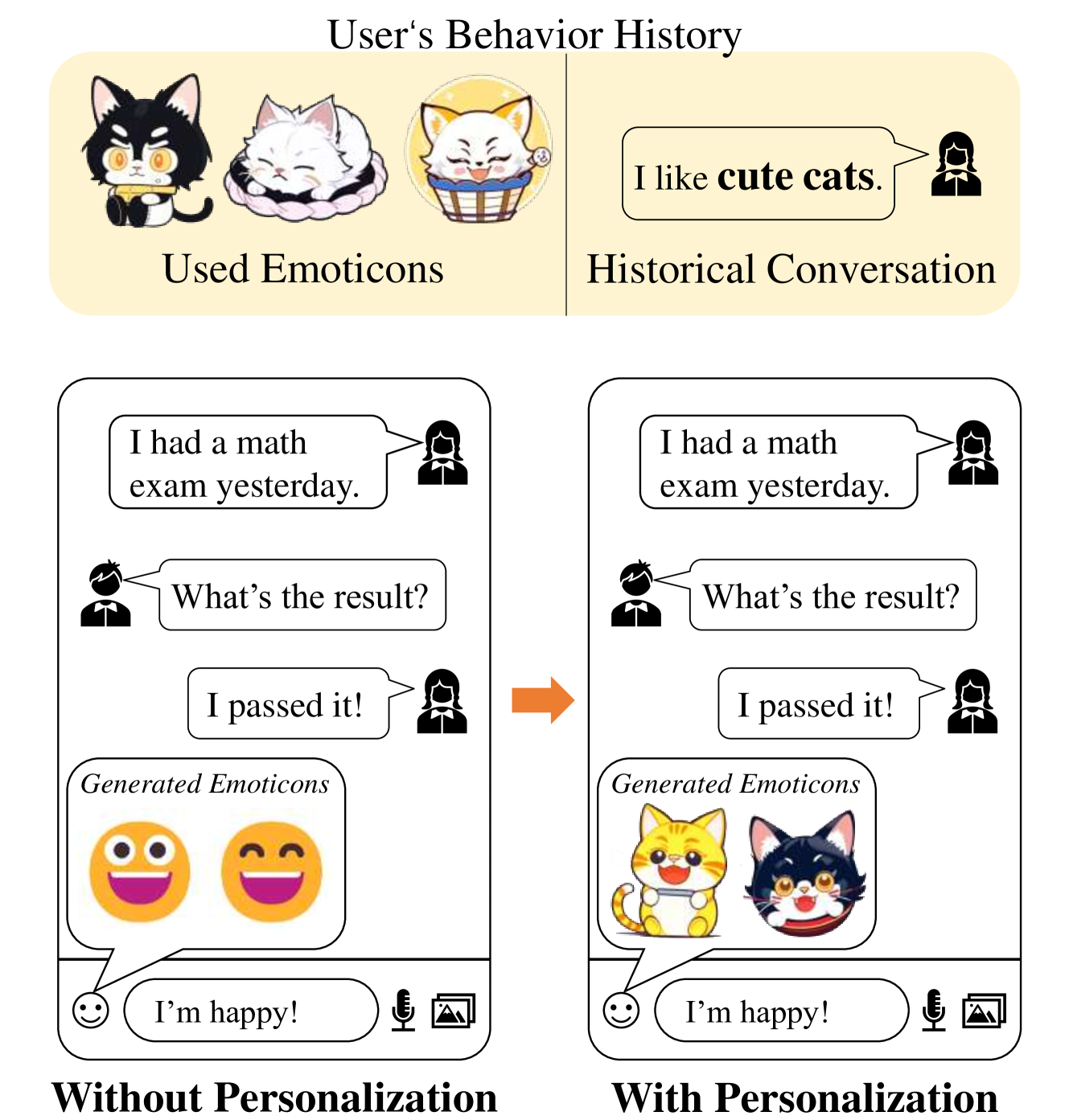
PMG : Personalized Multimodal Generation with Large Language Models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, Xi Xiao
0
0
The emergence of large language models (LLMs) has revolutionized the capabilities of text comprehension and generation. Multi-modal generation attracts great attention from both the industry and academia, but there is little work on personalized generation, which has important applications such as recommender systems. This paper proposes the first method for personalized multimodal generation using LLMs, showcases its applications and validates its performance via an extensive experimental study on two datasets. The proposed method, Personalized Multimodal Generation (PMG for short) first converts user behaviors (e.g., clicks in recommender systems or conversations with a virtual assistant) into natural language to facilitate LLM understanding and extract user preference descriptions. Such user preferences are then fed into a generator, such as a multimodal LLM or diffusion model, to produce personalized content. To capture user preferences comprehensively and accurately, we propose to let the LLM output a combination of explicit keywords and implicit embeddings to represent user preferences. Then the combination of keywords and embeddings are used as prompts to condition the generator. We optimize a weighted sum of the accuracy and preference scores so that the generated content has a good balance between them. Compared to a baseline method without personalization, PMG has a significant improvement on personalization for up to 8% in terms of LPIPS while retaining the accuracy of generation.
4/16/2024