Enriching Information and Preserving Semantic Consistency in Expanding Curvilinear Object Segmentation Datasets

0
Sign in to get full access
Overview
- This paper presents a novel method for enriching and preserving semantic consistency in expanding curvilinear object segmentation datasets.
- The proposed approach involves using synthetic image generation techniques to augment existing datasets, while ensuring that the added data maintains semantic coherence with the original samples.
- The researchers demonstrate the effectiveness of their method through experiments on several benchmark datasets, showcasing improved performance in curvilinear object segmentation tasks.
Plain English Explanation
Curvilinear objects, such as roads, rivers, and blood vessels, are essential elements in many computer vision applications, but segmenting them accurately can be challenging. To address this, researchers have been working on creating and expanding datasets that can be used to train machine learning models for curvilinear object segmentation.
However, as these datasets grow, it becomes increasingly important to ensure that the new data added to the dataset maintains the same semantic meaning and consistency as the original samples. This paper presents a novel approach to address this challenge. The researchers use synthetic image generation techniques to create new samples that can be added to the dataset, but they also develop methods to ensure that the generated data preserves the semantic characteristics of the original data.
By doing this, the researchers are able to enrich the dataset with a larger number of samples, while still maintaining the overall coherence and meaning of the data. This, in turn, helps to improve the performance of machine learning models trained on the expanded dataset for tasks like curvilinear object segmentation.
The researchers demonstrate the effectiveness of their approach through experiments on several benchmark datasets, showing that their method can lead to significant improvements in segmentation accuracy compared to other approaches.
Technical Explanation
The paper proposes a novel framework for enriching and preserving semantic consistency in expanding curvilinear object segmentation datasets. The key components of the proposed approach are:
-
Synthetic Image Generation: The researchers use a generative adversarial network (GAN) to create new synthetic images that can be added to the dataset. This allows them to expand the dataset without relying solely on manual data collection and annotation.
-
Semantic Consistency Preservation: To ensure that the synthetic images maintain the same semantic characteristics as the original dataset, the researchers develop a semantic loss function. This loss term encourages the generated samples to align with the semantic features of the real data, such as the shape, orientation, and connectivity of curvilinear objects.
-
Dataset Augmentation: The researchers combine the original dataset and the newly generated synthetic samples to create an expanded dataset. This expanded dataset is then used to train machine learning models for curvilinear object segmentation tasks.
The researchers evaluate their proposed approach on several benchmark datasets, including DRIVE, STARE, and CHASE_DB1. Their results demonstrate that the expanded datasets created using their method lead to significant performance improvements in curvilinear object segmentation tasks compared to using the original datasets alone or other data augmentation techniques.
Critical Analysis
The paper presents a well-designed and promising approach for enriching and preserving semantic consistency in expanding curvilinear object segmentation datasets. The use of synthetic image generation, coupled with a semantic consistency preservation mechanism, is a novel and effective solution to the challenge of dataset expansion while maintaining data quality.
One potential limitation of the study is the reliance on specific benchmark datasets, which may not fully represent the diversity of curvilinear objects encountered in real-world scenarios. It would be interesting to see the performance of the proposed method on a broader range of datasets, including those with more complex or varied curvilinear structures, such as 3D human reconstruction from wild synthetic data or object-centric relational representations for image generation.
Additionally, while the paper demonstrates the effectiveness of the proposed approach, it would be valuable to explore the scalability and computational efficiency of the method, especially as the size of the dataset grows. This information could help researchers and practitioners better understand the practical implications of adopting the proposed framework in real-world applications.
Conclusion
This paper presents a novel and effective approach for enriching and preserving semantic consistency in expanding curvilinear object segmentation datasets. By leveraging synthetic image generation techniques coupled with a semantic consistency preservation mechanism, the researchers have developed a method that can significantly improve the performance of machine learning models trained on the expanded datasets.
The demonstrated improvements in curvilinear object segmentation tasks across multiple benchmark datasets highlight the potential of this approach to enhance the quality and diversity of data used for training computer vision models. As the field of computer vision continues to evolve, advancements in dataset expansion and maintenance, such as the one presented in this paper, will be crucial for driving further progress in areas like medical image analysis, autonomous navigation, and infrastructure monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Enriching Information and Preserving Semantic Consistency in Expanding Curvilinear Object Segmentation Datasets
Qin Lei, Jiang Zhong, Qizhu Dai
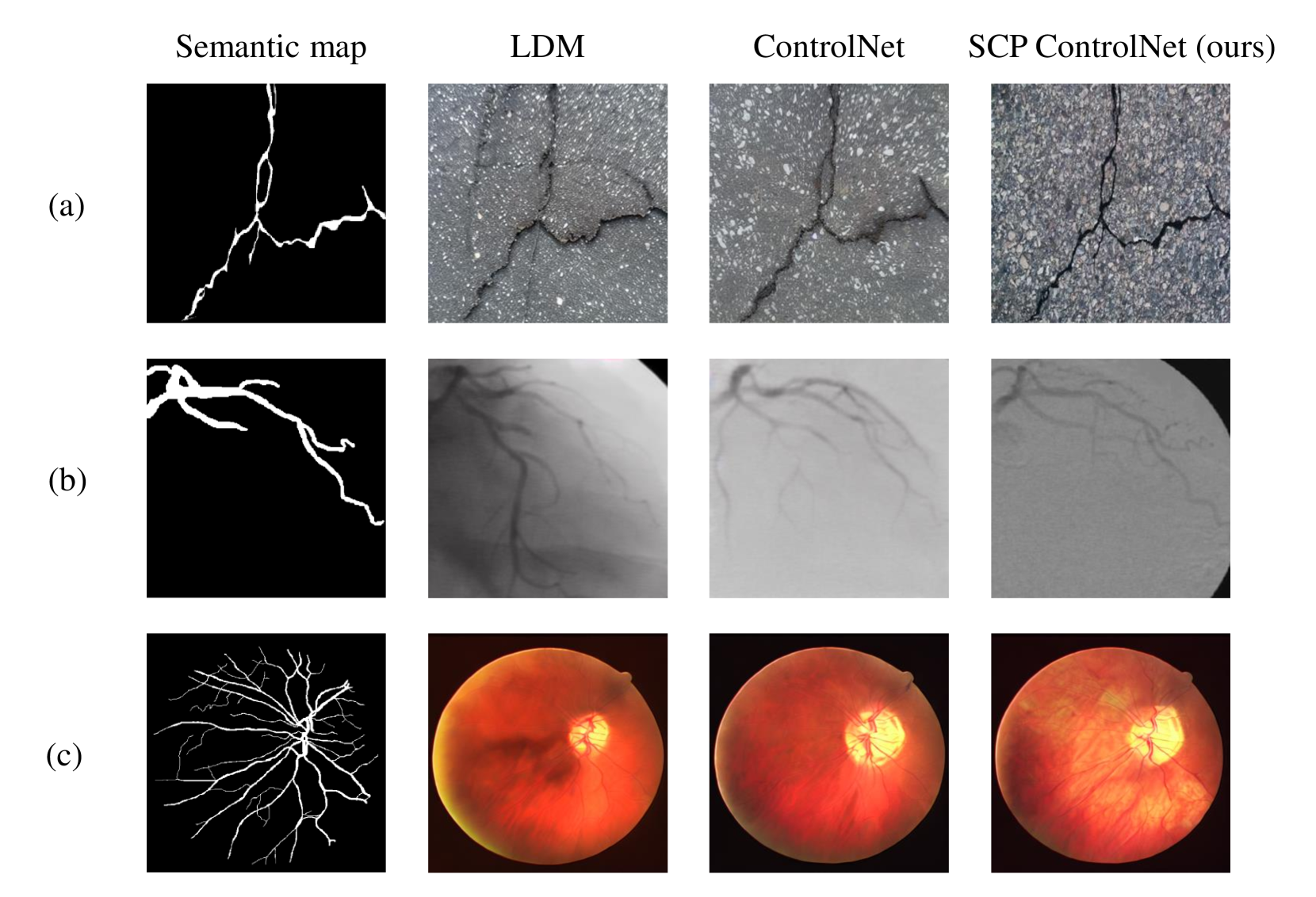
Curvilinear object segmentation plays a crucial role across various applications, yet datasets in this domain often suffer from small scale due to the high costs associated with data acquisition and annotation. To address these challenges, this paper introduces a novel approach for expanding curvilinear object segmentation datasets, focusing on enhancing the informativeness of generated data and the consistency between semantic maps and generated images. Our method enriches synthetic data informativeness by generating curvilinear objects through their multiple textual features. By combining textual features from each sample in original dataset, we obtain synthetic images that beyond the original dataset's distribution. This initiative necessitated the creation of the Curvilinear Object Segmentation based on Text Generation (COSTG) dataset. Designed to surpass the limitations of conventional datasets, COSTG incorporates not only standard semantic maps but also some textual descriptions of curvilinear object features. To ensure consistency between synthetic semantic maps and images, we introduce the Semantic Consistency Preserving ControlNet (SCP ControlNet). This involves an adaptation of ControlNet with Spatially-Adaptive Normalization (SPADE), allowing it to preserve semantic information that would typically be washed away in normalization layers. This modification facilitates more accurate semantic image synthesis. Experimental results demonstrate the efficacy of our approach across three types of curvilinear objects (angiography, crack and retina) and six public datasets (CHUAC, XCAD, DCA1, DRIVE, CHASEDB1 and Crack500). The synthetic data generated by our method not only expand the dataset, but also effectively improves the performance of other curvilinear object segmentation models. Source code and dataset are available at url{https://github.com/tanlei0/COSTG}.
Read more7/12/2024

0
Enhanced Generative Data Augmentation for Semantic Segmentation via Stronger Guidance
Quang-Huy Che, Duc-Tri Le, Vinh-Tiep Nguyen
Data augmentation is a widely used technique for creating training data for tasks that require labeled data, such as semantic segmentation. This method benefits pixel-wise annotation tasks requiring much effort and intensive labor. Traditional data augmentation methods involve simple transformations like rotations and flips to create new images from existing ones. However, these new images may lack diversity along the main semantic axes in the data and not change high-level semantic properties. To address this issue, generative models have emerged as an effective solution for augmenting data by generating synthetic images. Controllable generative models offer a way to augment data for semantic segmentation tasks using a prompt and visual reference from the original image. However, using these models directly presents challenges, such as creating an effective prompt and visual reference to generate a synthetic image that accurately reflects the content and structure of the original. In this work, we introduce an effective data augmentation method for semantic segmentation using the Controllable Diffusion Model. Our proposed method includes efficient prompt generation using Class-Prompt Appending and Visual Prior Combination to enhance attention to labeled classes in real images. These techniques allow us to generate images that accurately depict segmented classes in the real image. In addition, we employ the class balancing algorithm to ensure efficiency when merging the synthetic and original images to generate balanced data for the training dataset. We evaluated our method on the PASCAL VOC datasets and found it highly effective for synthesizing images in semantic segmentation.
Read more9/14/2024

0
3D-VirtFusion: Synthetic 3D Data Augmentation through Generative Diffusion Models and Controllable Editing
Shichao Dong, Ze Yang, Guosheng Lin
Data augmentation plays a crucial role in deep learning, enhancing the generalization and robustness of learning-based models. Standard approaches involve simple transformations like rotations and flips for generating extra data. However, these augmentations are limited by their initial dataset, lacking high-level diversity. Recently, large models such as language models and diffusion models have shown exceptional capabilities in perception and content generation. In this work, we propose a new paradigm to automatically generate 3D labeled training data by harnessing the power of pretrained large foundation models. For each target semantic class, we first generate 2D images of a single object in various structure and appearance via diffusion models and chatGPT generated text prompts. Beyond texture augmentation, we propose a method to automatically alter the shape of objects within 2D images. Subsequently, we transform these augmented images into 3D objects and construct virtual scenes by random composition. This method can automatically produce a substantial amount of 3D scene data without the need of real data, providing significant benefits in addressing few-shot learning challenges and mitigating long-tailed class imbalances. By providing a flexible augmentation approach, our work contributes to enhancing 3D data diversity and advancing model capabilities in scene understanding tasks.
Read more8/27/2024

0
SCP-Diff: Spatial-Categorical Joint Prior for Diffusion Based Semantic Image Synthesis
Huan-ang Gao, Mingju Gao, Jiaju Li, Wenyi Li, Rong Zhi, Hao Tang, Hao Zhao
Semantic image synthesis (SIS) shows good promises for sensor simulation. However, current best practices in this field, based on GANs, have not yet reached the desired level of quality. As latent diffusion models make significant strides in image generation, we are prompted to evaluate ControlNet, a notable method for its dense control capabilities. Our investigation uncovered two primary issues with its results: the presence of weird sub-structures within large semantic areas and the misalignment of content with the semantic mask. Through empirical study, we pinpointed the cause of these problems as a mismatch between the noised training data distribution and the standard normal prior applied at the inference stage. To address this challenge, we developed specific noise priors for SIS, encompassing spatial, categorical, and a novel spatial-categorical joint prior for inference. This approach, which we have named SCP-Diff, has set new state-of-the-art results in SIS on Cityscapes, ADE20K and COCO-Stuff, yielding a FID as low as 10.53 on Cityscapes. The code and models can be accessed via the project page.
Read more7/17/2024