3D Human Reconstruction in the Wild with Synthetic Data Using Generative Models
2403.11111
0
0
Abstract
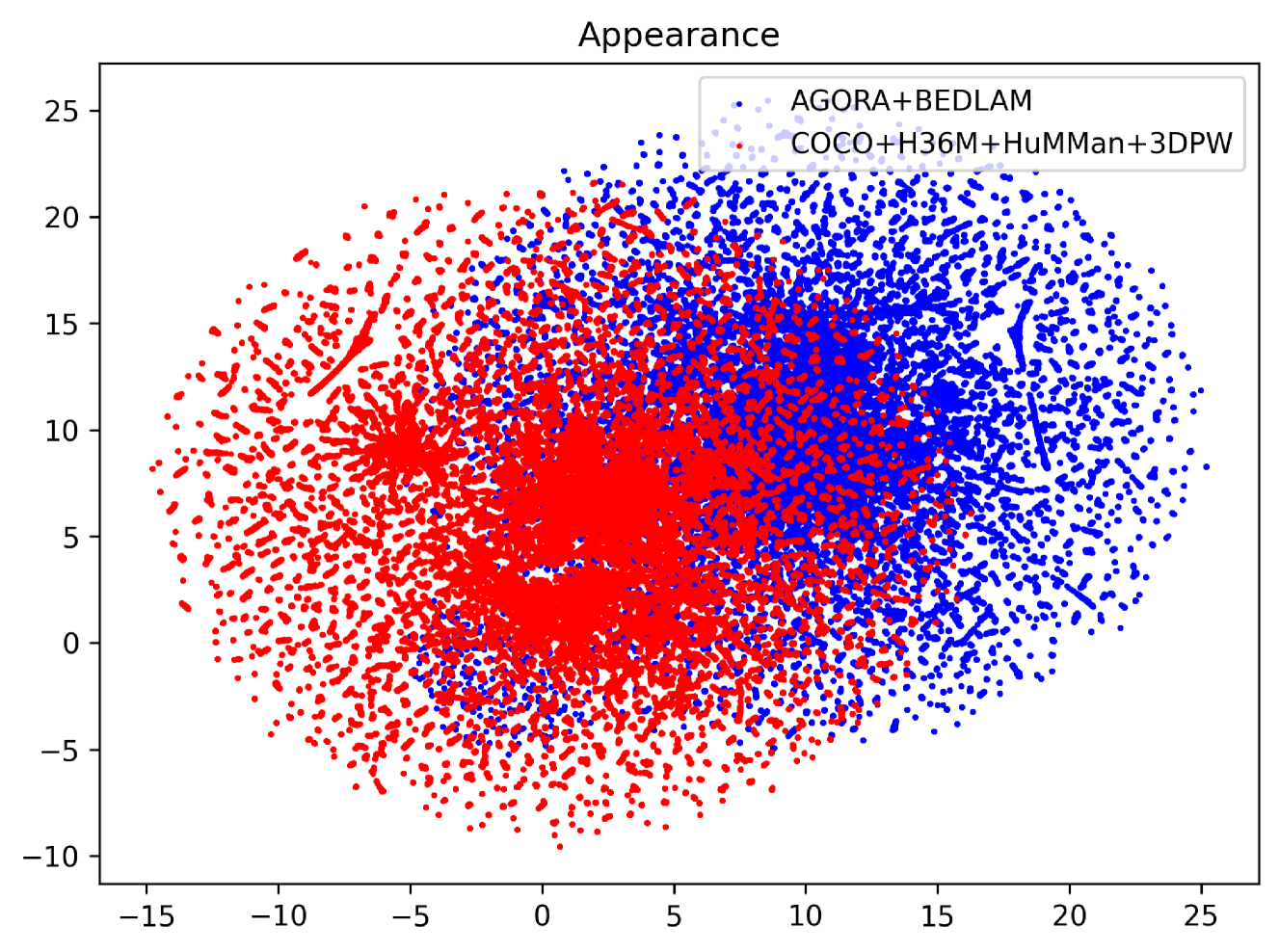
In this work, we show that synthetic data created by generative models is complementary to computer graphics (CG) rendered data for achieving remarkable generalization performance on diverse real-world scenes for 3D human pose and shape estimation (HPS). Specifically, we propose an effective approach based on recent diffusion models, termed HumanWild, which can effortlessly generate human images and corresponding 3D mesh annotations. We first collect a large-scale human-centric dataset with comprehensive annotations, e.g., text captions and surface normal images. Then, we train a customized ControlNet model upon this dataset to generate diverse human images and initial ground-truth labels. At the core of this step is that we can easily obtain numerous surface normal images from a 3D human parametric model, e.g., SMPL-X, by rendering the 3D mesh onto the image plane. As there exists inevitable noise in the initial labels, we then apply an off-the-shelf foundation segmentation model, i.e., SAM, to filter negative data samples. Our data generation pipeline is flexible and customizable to facilitate different real-world tasks, e.g., ego-centric scenes and perspective-distortion scenes. The generated dataset comprises 0.79M images with corresponding 3D annotations, covering versatile viewpoints, scenes, and human identities. We train various HPS regressors on top of the generated data and evaluate them on a wide range of benchmarks (3DPW, RICH, EgoBody, AGORA, SSP-3D) to verify the effectiveness of the generated data. By exclusively employing generative models, we generate large-scale in-the-wild human images and high-quality annotations, eliminating the need for real-world data collection.
Create account to get full access
Overview
- This paper presents a method for 3D human reconstruction from images in unconstrained environments using synthetic data and generative models.
- The approach leverages a diffusion model trained on a large-scale synthetic dataset to reconstruct 3D human poses and shapes from single RGB images.
- The synthetic dataset is created using a novel controllable human generation pipeline, allowing fine-grained control over various attributes like pose, shape, and clothing.
Plain English Explanation
This research aims to develop a way to reconstruct 3D models of people from regular 2D photos, even in challenging outdoor settings. The key idea is to use computer-generated, synthetic data to train a machine learning model that can take a 2D photo and output a 3D representation of the person in the image.
The researchers created a large dataset of synthetic human images, where they had full control over the people's poses, body shapes, and clothing. They then trained a diffusion model, a type of generative AI, to learn the mapping from these 2D synthetic images to the corresponding 3D human models. With this trained model, they can now take a new 2D photo of a person "in the wild" and reconstruct a 3D version of that person.
This approach is useful because collecting and annotating real-world 3D human data is extremely challenging and time-consuming. By using synthetic data instead, the researchers were able to develop a 3D human reconstruction system that works well even in uncontrolled outdoor environments, where previous methods struggled.
Technical Explanation
The key technical components of this work are:
-
Controllable Human Generation Pipeline: The researchers developed a novel pipeline to generate a large-scale synthetic dataset of humans with fine-grained control over attributes like pose, shape, and clothing. This builds on prior work like Template-Free Reconstruction of Human-Object Interaction, EgoGen: Egocentric Synthetic Data Generator, and Joint2Human: High-Quality 3D Human Generation via Joint Optimization of Pose and Appearance.
-
Diffusion Model for 3D Reconstruction: The researchers trained a diffusion model, a type of generative adversarial network (GAN), to learn the mapping from 2D synthetic images to 3D human models. This builds on work like Semantic Human Mesh Recovery from Textures.
-
Iterative Retraining Approach: To improve the model's performance on real-world data, the researchers used an iterative retraining strategy, where they fine-tuned the model on a small set of real images. This helps address the Stability of Iterative Retraining of Generative Models on Their Own distribution shift issue.
The key insight is that by leveraging a large-scale synthetic dataset with fine-grained control, the researchers were able to train a robust 3D human reconstruction model that generalizes well to real-world, "in the wild" scenarios, where prior methods struggled.
Critical Analysis
The paper presents a novel and promising approach to 3D human reconstruction, but there are a few potential limitations and areas for further research:
- The synthetic dataset, while large-scale, may still not capture the full diversity of real-world human appearances and poses. Expanding the dataset's realism and diversity could further improve the model's performance.
- The iterative retraining strategy helps bridge the gap between synthetic and real data, but the authors note that it can be unstable. More advanced domain adaptation techniques may be necessary to fully overcome this challenge.
- The paper focuses on single-view 3D reconstruction, but incorporating multiple views or depth information could potentially lead to even more accurate 3D models.
- While the results are impressive, the paper does not provide a detailed analysis of the model's limitations or failure cases. Understanding the model's weaknesses could guide future improvements.
Overall, this work represents an important step forward in 3D human reconstruction and demonstrates the power of leveraging synthetic data and generative models. Further research in this direction could lead to significant advancements in areas like augmented reality, robotics, and human-computer interaction.
Conclusion
This paper presents a novel approach for 3D human reconstruction from single RGB images in unconstrained environments. By using a large-scale synthetic dataset with fine-grained control over human attributes and a diffusion-based generative model, the researchers were able to develop a system that can accurately reconstruct 3D human poses and shapes even in challenging real-world scenarios.
The key innovation is the use of synthetic data to train a robust 3D reconstruction model, which helps overcome the challenges of collecting and annotating real-world 3D human data. This work builds on previous research in areas like human pose estimation, 3D reconstruction, and generative modeling, and represents an important step towards more widespread adoption of 3D human understanding in computer vision and related fields.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SynthForge: Synthesizing High-Quality Face Dataset with Controllable 3D Generative Models
Abhay Rawat, Shubham Dokania, Astitva Srivastava, Shuaib Ahmed, Haiwen Feng, Rahul Tallamraju
0
0
Recent advancements in generative models have unlocked the capabilities to render photo-realistic data in a controllable fashion. Trained on the real data, these generative models are capable of producing realistic samples with minimal to no domain gap, as compared to the traditional graphics rendering. However, using the data generated using such models for training downstream tasks remains under-explored, mainly due to the lack of 3D consistent annotations. Moreover, controllable generative models are learned from massive data and their latent space is often too vast to obtain meaningful sample distributions for downstream task with limited generation. To overcome these challenges, we extract 3D consistent annotations from an existing controllable generative model, making the data useful for downstream tasks. Our experiments show competitive performance against state-of-the-art models using only generated synthetic data, demonstrating potential for solving downstream tasks. Project page: https://synth-forge.github.io
6/13/2024
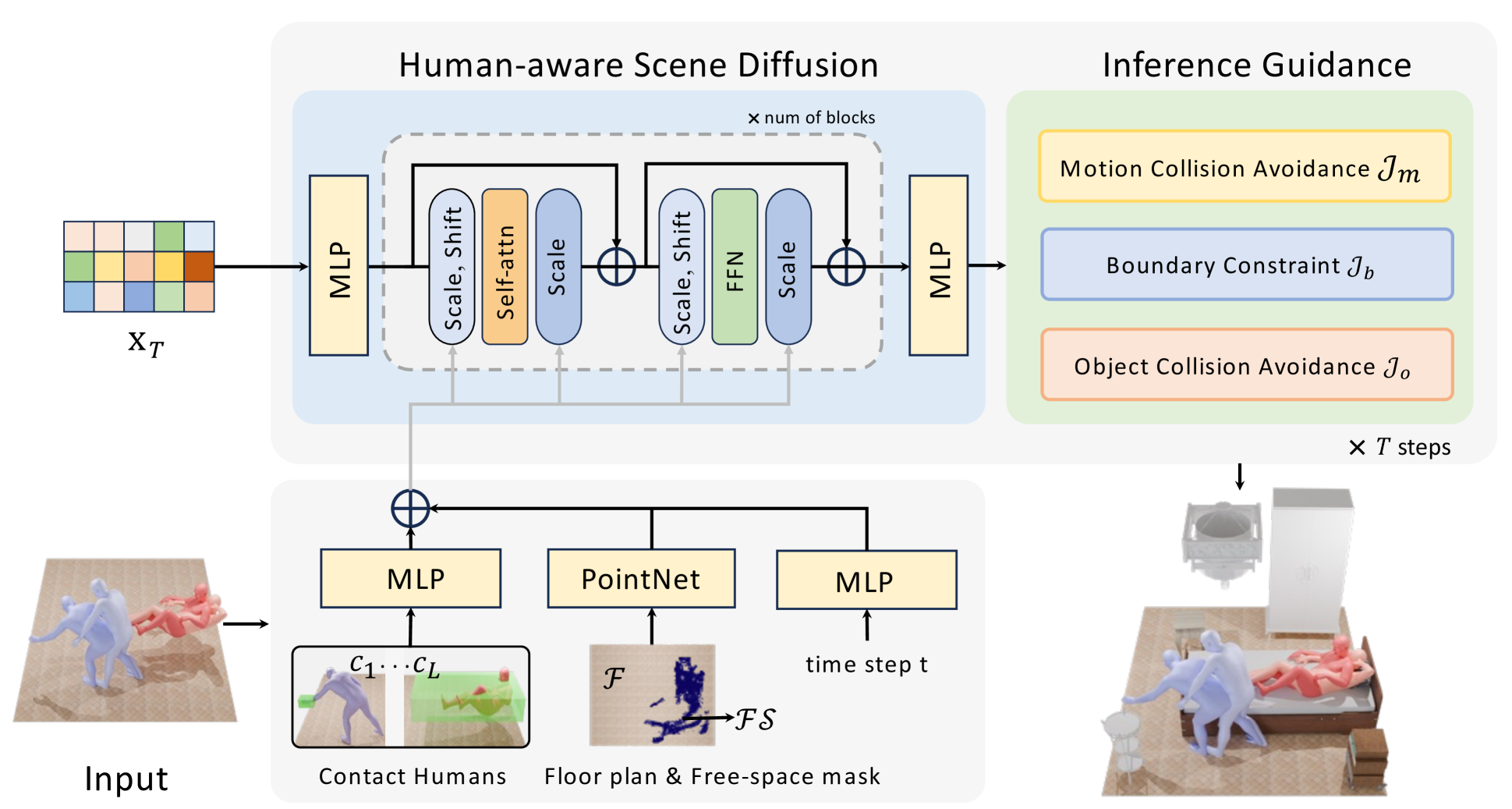
Human-Aware 3D Scene Generation with Spatially-constrained Diffusion Models
Xiaolin Hong, Hongwei Yi, Fazhi He, Qiong Cao
0
0
Generating 3D scenes from human motion sequences supports numerous applications, including virtual reality and architectural design. However, previous auto-regression-based human-aware 3D scene generation methods have struggled to accurately capture the joint distribution of multiple objects and input humans, often resulting in overlapping object generation in the same space. To address this limitation, we explore the potential of diffusion models that simultaneously consider all input humans and the floor plan to generate plausible 3D scenes. Our approach not only satisfies all input human interactions but also adheres to spatial constraints with the floor plan. Furthermore, we introduce two spatial collision guidance mechanisms: human-object collision avoidance and object-room boundary constraints. These mechanisms help avoid generating scenes that conflict with human motions while respecting layout constraints. To enhance the diversity and accuracy of human-guided scene generation, we have developed an automated pipeline that improves the variety and plausibility of human-object interactions in the existing 3D FRONT HUMAN dataset. Extensive experiments on both synthetic and real-world datasets demonstrate that our framework can generate more natural and plausible 3D scenes with precise human-scene interactions, while significantly reducing human-object collisions compared to previous state-of-the-art methods. Our code and data will be made publicly available upon publication of this work.
6/27/2024

Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation
Xianghui Xie, Bharat Lal Bhatnagar, Jan Eric Lenssen, Gerard Pons-Moll
0
0
Reconstructing human-object interaction in 3D from a single RGB image is a challenging task and existing data driven methods do not generalize beyond the objects present in the carefully curated 3D interaction datasets. Capturing large-scale real data to learn strong interaction and 3D shape priors is very expensive due to the combinatorial nature of human-object interactions. In this paper, we propose ProciGen (Procedural interaction Generation), a method to procedurally generate datasets with both, plausible interaction and diverse object variation. We generate 1M+ human-object interaction pairs in 3D and leverage this large-scale data to train our HDM (Hierarchical Diffusion Model), a novel method to reconstruct interacting human and unseen objects, without any templates. Our HDM is an image-conditioned diffusion model that learns both realistic interaction and highly accurate human and object shapes. Experiments show that our HDM trained with ProciGen significantly outperforms prior methods that requires template meshes and that our dataset allows training methods with strong generalization ability to unseen object instances. Our code and data are released.
4/9/2024
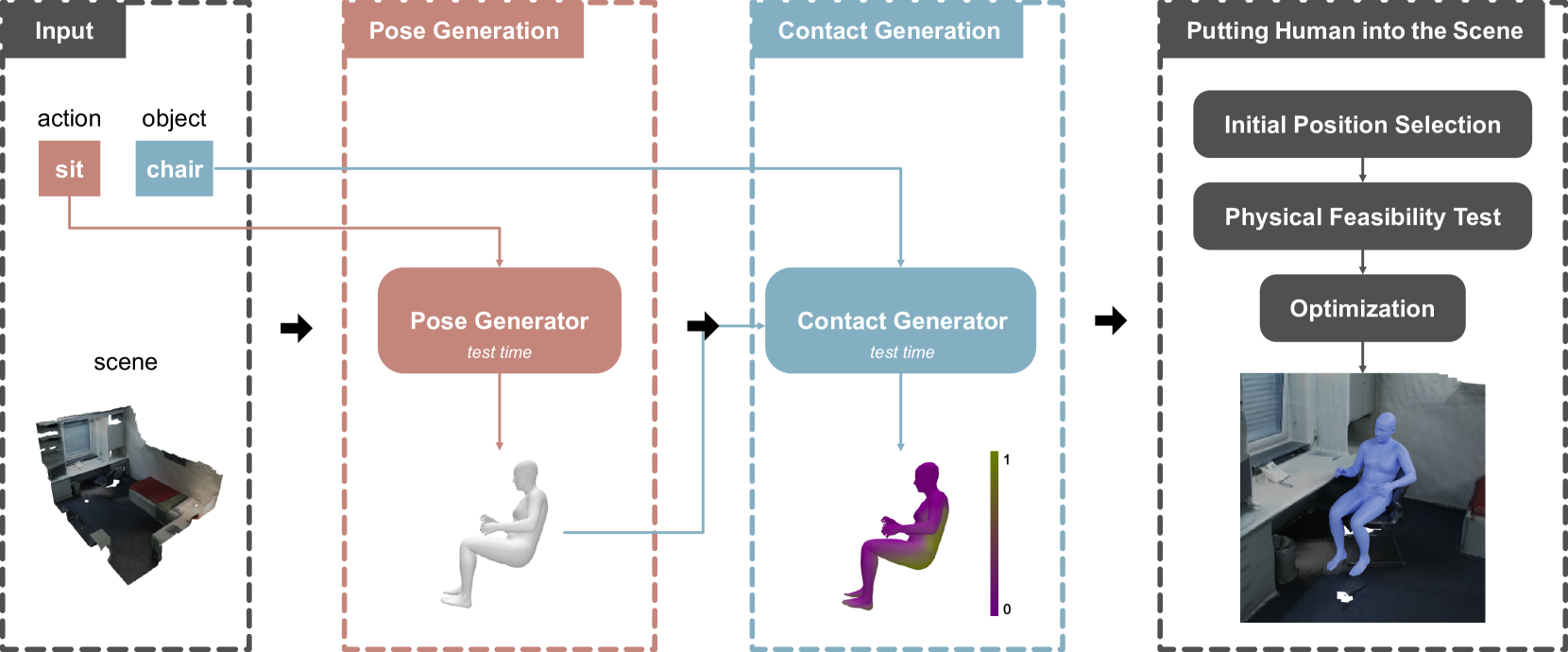
Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
Bowen Dang, Xi Zhao
0
0
This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.
6/11/2024