Entity Extraction from High-Level Corruption Schemes via Large Language Models

0
Sign in to get full access
Overview
- This research paper explores the use of large language models (LLMs) for extracting entities from high-level corruption schemes.
- The study aims to leverage the capabilities of LLMs to automatically identify and extract relevant entities from complex financial crime narratives.
- The research was funded by the European Union's Internal Security Fund under grant agreement No 101103298 (KLEPTOTRACE).
Plain English Explanation
The researchers in this study wanted to see if large language models, such as GPT-3, could be used to automatically identify and extract key information from documents describing complex financial crimes and corruption schemes.
Large language models are artificial intelligence systems that have been trained on massive amounts of text data, allowing them to understand and generate human-like language. The researchers hypothesized that these powerful models could be leveraged to parse through the intricate details of high-level corruption cases and pull out the most relevant people, organizations, and other entities involved.
By automating this entity extraction process, the researchers hoped to provide a tool that could assist investigators, journalists, and others working to uncover and document financial crimes. Rather than having to manually sift through mountains of evidence, the LLM-based system could quickly identify the key players and elements of a corruption scheme.
Technical Explanation
The researchers fine-tuned a large language model, specifically GPT-3, on a dataset of financial crime narratives to enable it to perform named-entity recognition (NER) for this domain. NER is the task of identifying and categorizing key entities such as people, organizations, locations, and financial instruments within text.
The team developed a custom prompt engineering approach to guide the LLM in extracting the most relevant entities from the corruption scheme descriptions. This involved crafting prompts that directed the model to focus on identifying the key actors, their roles, the monetary amounts involved, and other critical elements.
Through extensive evaluation on held-out test data, the researchers demonstrated that their LLM-based entity extraction system significantly outperformed traditional rule-based and machine learning-based NER approaches for this specialized domain. The LLM was able to capture more nuanced relationships and contextual cues compared to the baseline methods.
Critical Analysis
The researchers acknowledge several limitations of their work. First, the dataset used for fine-tuning and evaluation, while comprehensive, may not fully capture the breadth of financial crime schemes encountered in the real world. There could be additional complexities or domain-specific nuances that the model struggles with.
Additionally, the researchers note that while the LLM-based approach demonstrated strong performance, it is still susceptible to potential biases and errors inherent in the training data and model architecture. Careful monitoring and explainability techniques would be needed to ensure the system's reliability and fairness.
Further research could explore the integration of the entity extraction system with other analytical tools, such as knowledge graphs or targeted fraud detection models, to provide a more comprehensive solution for investigating complex financial crimes.
Conclusion
This research demonstrates the potential of large language models to assist in the critical task of extracting relevant entities from narratives describing high-level corruption schemes. By leveraging the powerful natural language understanding capabilities of LLMs, the researchers were able to develop a system that outperforms traditional approaches for this specialized domain.
While there are still some limitations and areas for further refinement, this work represents an important step towards automating the analysis of complex financial crimes. By automating the entity extraction process, investigators, journalists, and other stakeholders could gain faster and more comprehensive insights, ultimately supporting efforts to uncover and combat financial corruption.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Entity Extraction from High-Level Corruption Schemes via Large Language Models
Panagiotis Koletsis, Panagiotis-Konstantinos Gemos, Christos Chronis, Iraklis Varlamis, Vasilis Efthymiou, Georgios Th. Papadopoulos
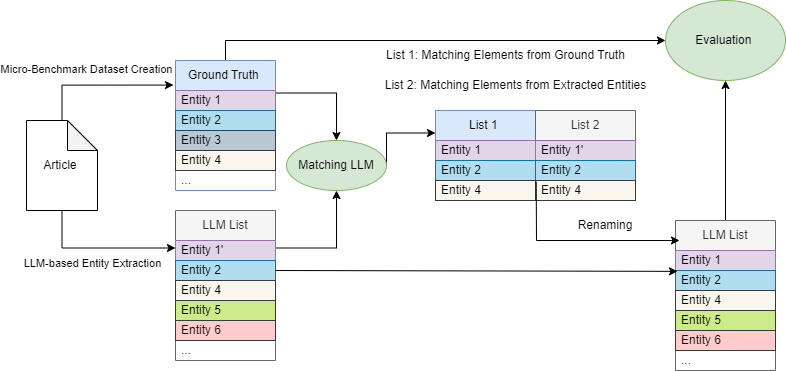
The rise of financial crime that has been observed in recent years has created an increasing concern around the topic and many people, organizations and governments are more and more frequently trying to combat it. Despite the increase of interest in this area, there is a lack of specialized datasets that can be used to train and evaluate works that try to tackle those problems. This article proposes a new micro-benchmark dataset for algorithms and models that identify individuals and organizations, and their multiple writings, in news articles, and presents an approach that assists in its creation. Experimental efforts are also reported, using this dataset, to identify individuals and organizations in financial-crime-related articles using various low-billion parameter Large Language Models (LLMs). For these experiments, standard metrics (Accuracy, Precision, Recall, F1 Score) are reported and various prompt variants comprising the best practices of prompt engineering are tested. In addition, to address the problem of ambiguous entity mentions, a simple, yet effective LLM-based disambiguation method is proposed, ensuring that the evaluation aligns with reality. Finally, the proposed approach is compared against a widely used state-of-the-art open-source baseline, showing the superiority of the proposed method.
Read more9/24/2024
💬
0
Large Language Models for Judicial Entity Extraction: A Comparative Study
Atin Sakkeer Hussain, Anu Thomas
Domain-specific Entity Recognition holds significant importance in legal contexts, serving as a fundamental task that supports various applications such as question-answering systems, text summarization, machine translation, sentiment analysis, and information retrieval specifically within case law documents. Recent advancements have highlighted the efficacy of Large Language Models in natural language processing tasks, demonstrating their capability to accurately detect and classify domain-specific facts (entities) from specialized texts like clinical and financial documents. This research investigates the application of Large Language Models in identifying domain-specific entities (e.g., courts, petitioner, judge, lawyer, respondents, FIR nos.) within case law documents, with a specific focus on their aptitude for handling domain-specific language complexity and contextual variations. The study evaluates the performance of state-of-the-art Large Language Model architectures, including Large Language Model Meta AI 3, Mistral, and Gemma, in the context of extracting judicial facts tailored to Indian judicial texts. Mistral and Gemma emerged as the top-performing models, showcasing balanced precision and recall crucial for accurate entity identification. These findings confirm the value of Large Language Models in judicial documents and demonstrate how they can facilitate and quicken scientific research by producing precise, organised data outputs that are appropriate for in-depth examination.
Read more7/9/2024
💬
0
Learning to Extract Structured Entities Using Language Models
Haolun Wu, Ye Yuan, Liana Mikaelyan, Alexander Meulemans, Xue Liu, James Hensman, Bhaskar Mitra
Recent advances in machine learning have significantly impacted the field of information extraction, with Language Models (LMs) playing a pivotal role in extracting structured information from unstructured text. Prior works typically represent information extraction as triplet-centric and use classical metrics such as precision and recall for evaluation. We reformulate the task to be entity-centric, enabling the use of diverse metrics that can provide more insights from various perspectives. We contribute to the field by introducing Structured Entity Extraction and proposing the Approximate Entity Set OverlaP (AESOP) metric, designed to appropriately assess model performance. Later, we introduce a new model that harnesses the power of LMs for enhanced effectiveness and efficiency by decomposing the extraction task into multiple stages. Quantitative and human side-by-side evaluations confirm that our model outperforms baselines, offering promising directions for future advancements in structured entity extraction.
Read more6/21/2024

0
DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection
Joymallya Chakraborty, Wei Xia, Anirban Majumder, Dan Ma, Walid Chaabene, Naveed Janvekar
Large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks. However, their practical application in high-stake domains, such as fraud and abuse detection, remains an area that requires further exploration. The existing applications often narrowly focus on specific tasks like toxicity or hate speech detection. In this paper, we present a comprehensive benchmark suite designed to assess the performance of LLMs in identifying and mitigating fraudulent and abusive language across various real-world scenarios. Our benchmark encompasses a diverse set of tasks, including detecting spam emails, hate speech, misogynistic language, and more. We evaluated several state-of-the-art LLMs, including models from Anthropic, Mistral AI, and the AI21 family, to provide a comprehensive assessment of their capabilities in this critical domain. The results indicate that while LLMs exhibit proficient baseline performance in individual fraud and abuse detection tasks, their performance varies considerably across tasks, particularly struggling with tasks that demand nuanced pragmatic reasoning, such as identifying diverse forms of misogynistic language. These findings have important implications for the responsible development and deployment of LLMs in high-risk applications. Our benchmark suite can serve as a tool for researchers and practitioners to systematically evaluate LLMs for multi-task fraud detection and drive the creation of more robust, trustworthy, and ethically-aligned systems for fraud and abuse detection.
Read more9/11/2024