DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection

0

Sign in to get full access
Overview
- DetoxBench is a benchmark for evaluating large language models (LLMs) on multitask fraud and abuse detection.
- It covers a range of tasks like detecting hate speech, toxic language, and financial fraud.
- The benchmark aims to assess the capability of LLMs in identifying and mitigating harmful online content.
Plain English Explanation
Large Language Models (LLMs) are powerful artificial intelligence systems that can understand and generate human-like text. DetoxBench is a tool that tests how well these LLMs can identify different types of harmful or fraudulent content online, such as hate speech, toxic language, and financial fraud.
The benchmark covers a wide range of these problematic content types, allowing researchers to see how capable LLMs are at detecting and flagging this kind of harmful material. This is important because these powerful AI systems are increasingly being used to moderate and filter online content, so we need to understand their strengths and limitations in this area.
By testing LLMs on DetoxBench, we can get a better sense of how well they perform at the crucial task of identifying and stopping the spread of abusive, fraudulent, and otherwise harmful information online. This can help inform the development and deployment of these AI models to ensure they are effective at making the internet a safer and more trustworthy space.
Technical Explanation
DetoxBench is a comprehensive benchmark designed to evaluate the performance of large language models (LLMs) on a variety of fraud and abuse detection tasks. The benchmark covers a wide range of harmful content types, including hate speech, toxic language, financial fraud, and more.
The benchmark dataset was constructed by gathering text samples from multiple sources, such as social media platforms and financial transaction records. These samples were then carefully annotated by human raters to identify the presence of different types of harmful content. The resulting dataset serves as a standardized evaluation tool for assessing the capability of LLMs in detecting and mitigating such problematic content.
To evaluate LLM performance, the benchmark incorporates multiple metrics, such as classification accuracy, precision, recall, and F1-score. Researchers can use these metrics to compare the performance of different LLM architectures and configurations across the various tasks within the DetoxBench suite.
By benchmarking LLMs on this comprehensive dataset, researchers and developers can gain valuable insights into the strengths and limitations of these AI systems in the context of online content moderation and fraud prevention. This information can then be used to inform the development of more robust and effective LLM-based solutions for addressing harmful and fraudulent content on the internet.
Critical Analysis
The DetoxBench paper provides a well-designed and comprehensive benchmark for evaluating the performance of large language models (LLMs) on a range of fraud and abuse detection tasks. The breadth of content types covered, from hate speech to financial fraud, is a significant strength of the benchmark, as it allows for a more holistic assessment of LLM capabilities in this domain.
However, the paper acknowledges several limitations and caveats that should be considered. For example, the dataset used for the benchmark may not fully capture the nuances and context-dependent nature of harmful content, which could impact the generalizability of the results. Additionally, the authors note that the benchmark does not address issues of bias and fairness in LLM performance, which is an important consideration when deploying these systems in real-world content moderation scenarios.
Further research could explore ways to address these limitations, such as expanding the dataset to include more diverse and context-rich examples of harmful content, or incorporating bias and fairness metrics into the benchmark. Additionally, it would be valuable to investigate the transferability of LLM performance on DetoxBench to real-world content moderation tasks, to better understand the practical implications of the benchmark results.
Conclusion
DetoxBench is a valuable tool for assessing the capability of large language models (LLMs) in detecting and mitigating a wide range of harmful online content, including hate speech, toxic language, and financial fraud. By providing a standardized and comprehensive evaluation framework, the benchmark can help inform the development and deployment of more effective LLM-based solutions for content moderation and fraud prevention. While the benchmark has some limitations, it represents an important step forward in understanding the strengths and weaknesses of these powerful AI systems in addressing critical societal challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DetoxBench: Benchmarking Large Language Models for Multitask Fraud & Abuse Detection
Joymallya Chakraborty, Wei Xia, Anirban Majumder, Dan Ma, Walid Chaabene, Naveed Janvekar
Large language models (LLMs) have demonstrated remarkable capabilities in natural language processing tasks. However, their practical application in high-stake domains, such as fraud and abuse detection, remains an area that requires further exploration. The existing applications often narrowly focus on specific tasks like toxicity or hate speech detection. In this paper, we present a comprehensive benchmark suite designed to assess the performance of LLMs in identifying and mitigating fraudulent and abusive language across various real-world scenarios. Our benchmark encompasses a diverse set of tasks, including detecting spam emails, hate speech, misogynistic language, and more. We evaluated several state-of-the-art LLMs, including models from Anthropic, Mistral AI, and the AI21 family, to provide a comprehensive assessment of their capabilities in this critical domain. The results indicate that while LLMs exhibit proficient baseline performance in individual fraud and abuse detection tasks, their performance varies considerably across tasks, particularly struggling with tasks that demand nuanced pragmatic reasoning, such as identifying diverse forms of misogynistic language. These findings have important implications for the responsible development and deployment of LLMs in high-risk applications. Our benchmark suite can serve as a tool for researchers and practitioners to systematically evaluate LLMs for multi-task fraud detection and drive the creation of more robust, trustworthy, and ethically-aligned systems for fraud and abuse detection.
Read more9/11/2024

0
Large Language Models for Automatic Detection of Sensitive Topics
Ruoyu Wen, Stephanie Elena Crowe, Kunal Gupta, Xinyue Li, Mark Billinghurst, Simon Hoermann, Dwain Allan, Alaeddin Nassani, Thammathip Piumsomboon
Sensitive information detection is crucial in content moderation to maintain safe online communities. Assisting in this traditionally manual process could relieve human moderators from overwhelming and tedious tasks, allowing them to focus solely on flagged content that may pose potential risks. Rapidly advancing large language models (LLMs) are known for their capability to understand and process natural language and so present a potential solution to support this process. This study explores the capabilities of five LLMs for detecting sensitive messages in the mental well-being domain within two online datasets and assesses their performance in terms of accuracy, precision, recall, F1 scores, and consistency. Our findings indicate that LLMs have the potential to be integrated into the moderation workflow as a convenient and precise detection tool. The best-performing model, GPT-4o, achieved an average accuracy of 99.5% and an F1-score of 0.99. We discuss the advantages and potential challenges of using LLMs in the moderation workflow and suggest that future research should address the ethical considerations of utilising this technology.
Read more9/4/2024
💬
0
Harnessing Large Language Models for Software Vulnerability Detection: A Comprehensive Benchmarking Study
Karl Tamberg, Hayretdin Bahsi
Despite various approaches being employed to detect vulnerabilities, the number of reported vulnerabilities shows an upward trend over the years. This suggests the problems are not caught before the code is released, which could be caused by many factors, like lack of awareness, limited efficacy of the existing vulnerability detection tools or the tools not being user-friendly. To help combat some issues with traditional vulnerability detection tools, we propose using large language models (LLMs) to assist in finding vulnerabilities in source code. LLMs have shown a remarkable ability to understand and generate code, underlining their potential in code-related tasks. The aim is to test multiple state-of-the-art LLMs and identify the best prompting strategies, allowing extraction of the best value from the LLMs. We provide an overview of the strengths and weaknesses of the LLM-based approach and compare the results to those of traditional static analysis tools. We find that LLMs can pinpoint many more issues than traditional static analysis tools, outperforming traditional tools in terms of recall and F1 scores. The results should benefit software developers and security analysts responsible for ensuring that the code is free of vulnerabilities.
Read more5/27/2024
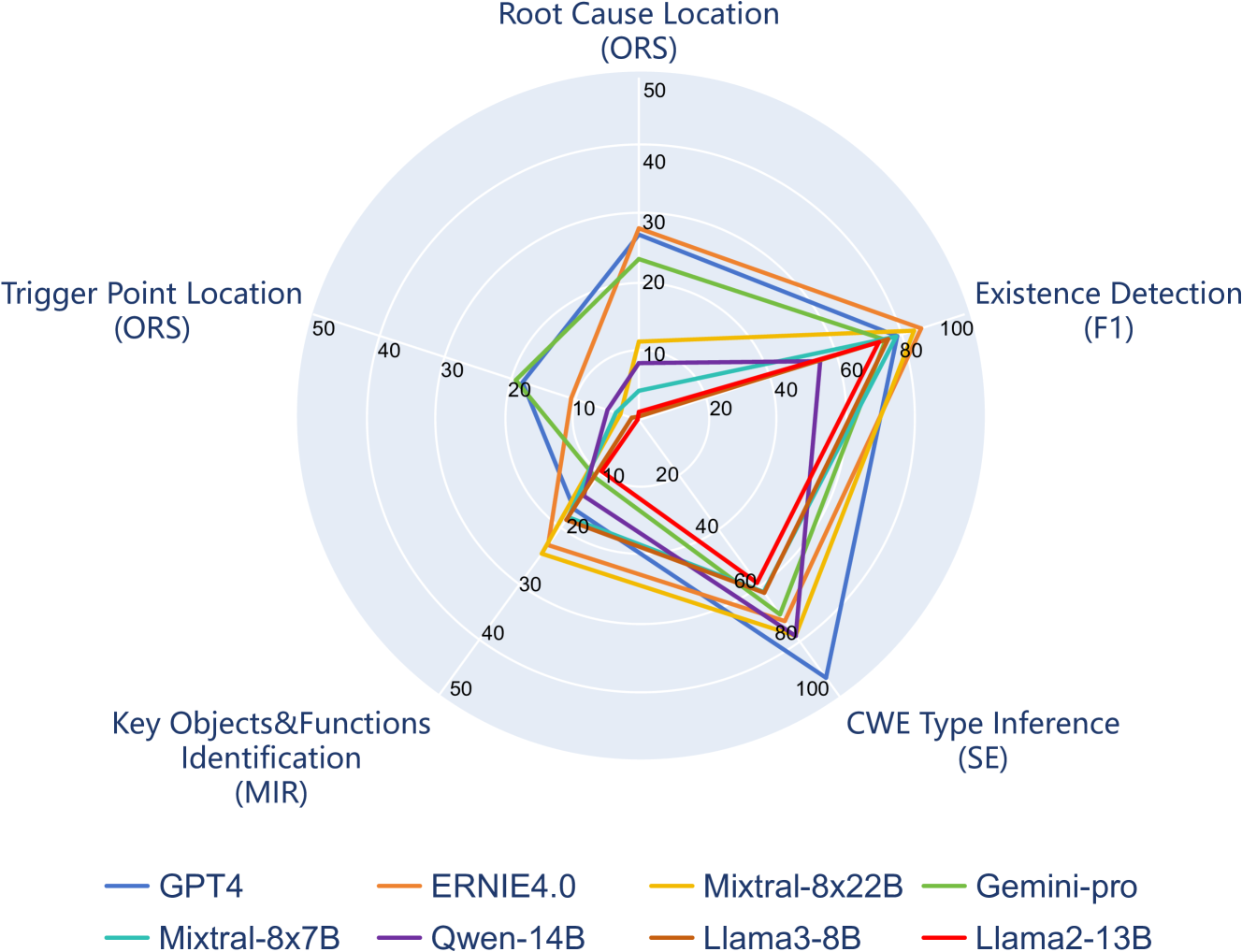
0
VulDetectBench: Evaluating the Deep Capability of Vulnerability Detection with Large Language Models
Yu Liu, Lang Gao, Mingxin Yang, Yu Xie, Ping Chen, Xiaojin Zhang, Wei Chen
Large Language Models (LLMs) have training corpora containing large amounts of program code, greatly improving the model's code comprehension and generation capabilities. However, sound comprehensive research on detecting program vulnerabilities, a more specific task related to code, and evaluating the performance of LLMs in this more specialized scenario is still lacking. To address common challenges in vulnerability analysis, our study introduces a new benchmark, VulDetectBench, specifically designed to assess the vulnerability detection capabilities of LLMs. The benchmark comprehensively evaluates LLM's ability to identify, classify, and locate vulnerabilities through five tasks of increasing difficulty. We evaluate the performance of 17 models (both open- and closed-source) and find that while existing models can achieve over 80% accuracy on tasks related to vulnerability identification and classification, they still fall short on specific, more detailed vulnerability analysis tasks, with less than 30% accuracy, making it difficult to provide valuable auxiliary information for professional vulnerability mining. Our benchmark effectively evaluates the capabilities of various LLMs at different levels in the specific task of vulnerability detection, providing a foundation for future research and improvements in this critical area of code security. VulDetectBench is publicly available at https://github.com/Sweetaroo/VulDetectBench.
Read more8/22/2024