Entropic Distribution Matching in Supervised Fine-tuning of LLMs: Less Overfitting and Better Diversity

0

Sign in to get full access
Overview
- Summarizes a paper on a technique called "Entropic Distribution Matching" for supervised fine-tuning of large language models (LLMs)
- Aims to reduce overfitting and improve diversity in the fine-tuned model
- Proposes a novel loss function that matches the entropy (diversity) of the model's output distribution to a target distribution
Plain English Explanation
The paper introduces a new technique called "Entropic Distribution Matching" that can be used when fine-tuning large language models (LLMs) on specific tasks. Fine-tuning is the process of taking a pre-trained LLM and further training it on a particular dataset to specialize its performance for a specific task.
One common problem with fine-tuning is overfitting - the model becomes too specialized to the training data and loses the ability to generalize well to new, unseen inputs. Another issue is that fine-tuned models can sometimes produce less diverse outputs, with the model tending to repeat similar patterns rather than generating novel and varied content.
The key idea behind Entropic Distribution Matching is to modify the training loss function to encourage the fine-tuned model to maintain a desired level of entropy or diversity in its output distribution. By matching the entropy of the model's outputs to a target distribution, the authors show that the fine-tuned model can achieve better generalization and produce more diverse responses, without sacrificing performance on the target task.
Technical Explanation
The paper proposes a novel loss function for supervised fine-tuning of LLMs that incorporates an "Entropic Distribution Matching" (EDM) term. The overall training loss is a combination of the standard supervised training loss (e.g., cross-entropy) and the EDM term.
The EDM term encourages the output distribution of the fine-tuned model to match a target distribution characterized by a desired level of entropy. Specifically, the authors use the Kullback-Leibler (KL) divergence between the model's output distribution and the target distribution as the EDM loss.
Through experiments on various natural language tasks, the authors demonstrate that models trained with the EDM loss exhibit:
- Less overfitting: The fine-tuned models maintain better performance on held-out test sets compared to standard fine-tuning approaches.
- Improved diversity: The generated outputs from the fine-tuned models are more diverse and less repetitive, as measured by metrics like n-gram diversity.
The authors also provide insights into how the target entropy level can be adjusted to control the trade-off between task performance and output diversity.
Critical Analysis
The paper presents a compelling approach to address the common challenges of overfitting and lack of diversity in supervised fine-tuning of LLMs. The Entropic Distribution Matching technique is a well-motivated and theoretically grounded solution that appears effective based on the reported results.
One potential limitation is that the method requires tuning the target entropy level, which may not be straightforward and could vary depending on the specific task and dataset. The authors acknowledge this and suggest further research into automated methods for setting the target entropy.
Additionally, the paper focuses on standard language modeling tasks and does not explore the implications of the EDM approach for more open-ended or generative tasks, where diversity may be even more crucial. Investigating the effectiveness of EDM in these broader settings could be an interesting avenue for future work.
Overall, the Entropic Distribution Matching technique offers a promising direction for improving the robustness and versatility of fine-tuned LLMs, and the paper provides a solid foundation for further research in this area.
Conclusion
This paper introduces a novel technique called Entropic Distribution Matching (EDM) for supervised fine-tuning of large language models. EDM aims to address two key challenges in fine-tuning: overfitting and lack of diversity in the model's outputs.
By incorporating an entropy-matching term in the training loss function, the authors demonstrate that fine-tuned models can maintain better generalization performance and produce more diverse responses, without sacrificing task-specific accuracy. The insights and findings from this work have the potential to contribute to the development of more robust and versatile language models, with applications across a wide range of natural language processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Entropic Distribution Matching in Supervised Fine-tuning of LLMs: Less Overfitting and Better Diversity
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Ruoyu Sun, Zhi-Quan Luo
Large language models rely on Supervised Fine-Tuning (SFT) to specialize in downstream tasks. Cross Entropy (CE) loss is the de facto choice in SFT, but it often leads to overfitting and limited output diversity due to its aggressive updates to the data distribution. This paper aim to address these issues by introducing the maximum entropy principle, which favors models with flatter distributions that still effectively capture the data. Specifically, we develop a new distribution matching method called GEM, which solves reverse Kullback-Leibler divergence minimization with an entropy regularizer. For the SFT of Llama-3-8B models, GEM outperforms CE in several aspects. First, when applied to the UltraFeedback dataset to develop general instruction-following abilities, GEM exhibits reduced overfitting, evidenced by lower perplexity and better performance on the IFEval benchmark. Furthermore, GEM enhances output diversity, leading to performance gains of up to 7 points on math reasoning and code generation tasks using best-of-n sampling, even without domain-specific data. Second, when fine-tuning with domain-specific datasets for math reasoning and code generation, GEM also shows less overfitting and improvements of up to 10 points compared with CE.
Read more8/30/2024

0
Are LLM-based Recommenders Already the Best? Simple Scaled Cross-entropy Unleashes the Potential of Traditional Sequential Recommenders
Cong Xu, Zhangchi Zhu, Mo Yu, Jun Wang, Jianyong Wang, Wei Zhang
Large language models (LLMs) have been garnering increasing attention in the recommendation community. Some studies have observed that LLMs, when fine-tuned by the cross-entropy (CE) loss with a full softmax, could achieve `state-of-the-art' performance in sequential recommendation. However, most of the baselines used for comparison are trained using a pointwise/pairwise loss function. This inconsistent experimental setting leads to the underestimation of traditional methods and further fosters over-confidence in the ranking capability of LLMs. In this study, we provide theoretical justification for the superiority of the cross-entropy loss by demonstrating its two desirable properties: tightness and coverage. Furthermore, this study sheds light on additional novel insights: 1) Taking into account only the recommendation performance, CE is not yet optimal as it is not a quite tight bound in terms of some ranking metrics. 2) In scenarios that full softmax cannot be performed, an effective alternative is to scale up the sampled normalizing term. These findings then help unleash the potential of traditional recommendation models, allowing them to surpass LLM-based counterparts. Given the substantial computational burden, existing LLM-based methods are not as effective as claimed for sequential recommendation. We hope that these theoretical understandings in conjunction with the empirical results will facilitate an objective evaluation of LLM-based recommendation in the future.
Read more8/27/2024
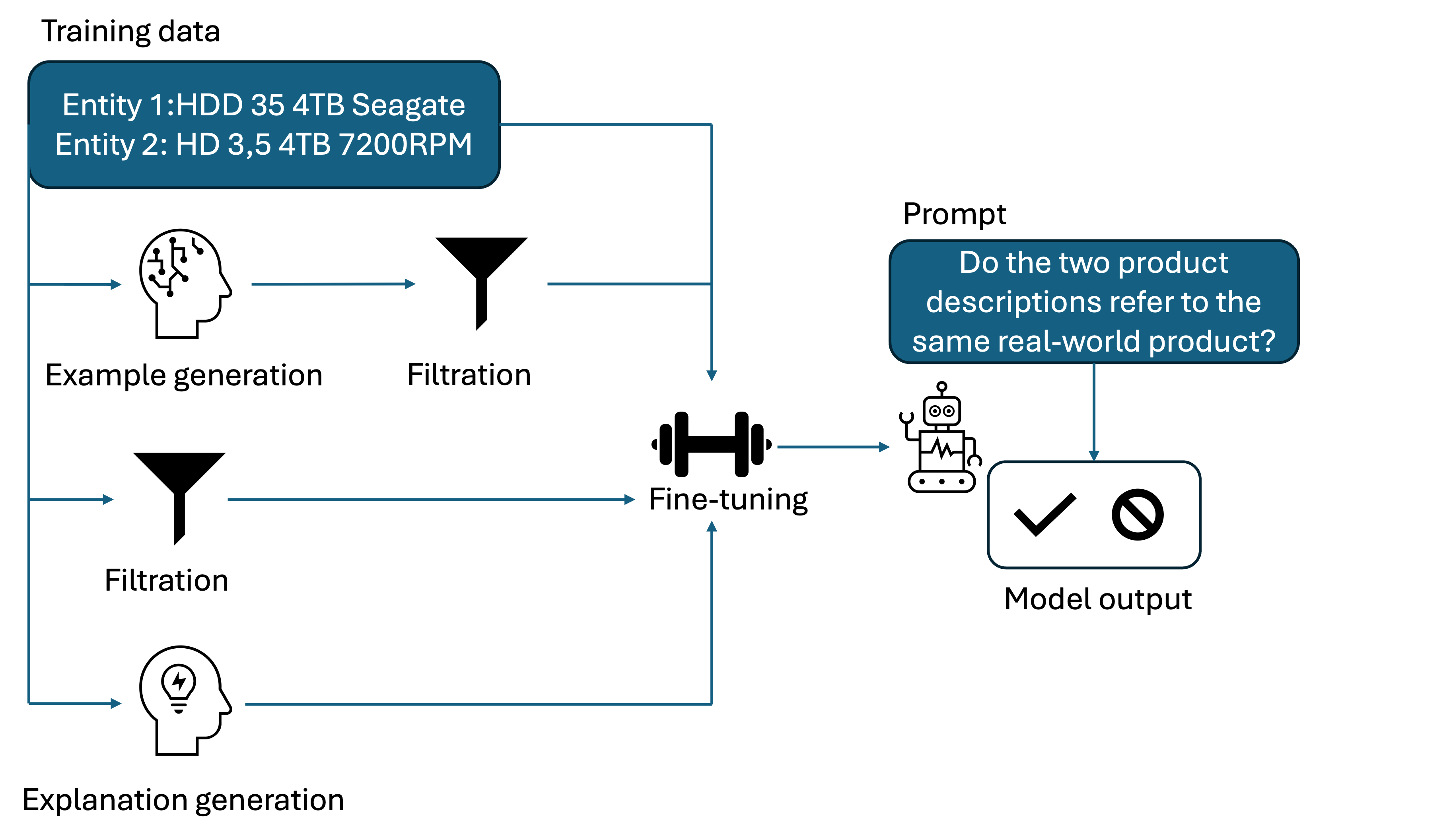
0
Fine-tuning Large Language Models for Entity Matching
Aaron Steiner, Ralph Peeters, Christian Bizer
Generative large language models (LLMs) are a promising alternative to pre-trained language models for entity matching due to their high zero-shot performance and their ability to generalize to unseen entities. Existing research on using LLMs for entity matching has focused on prompt engineering and in-context learning. This paper explores the potential of fine-tuning LLMs for entity matching. We analyze fine-tuning along two dimensions: 1) The representation of training examples, where we experiment with adding different types of LLM-generated explanations to the training set, and 2) the selection and generation of training examples using LLMs. In addition to the matching performance on the source dataset, we investigate how fine-tuning affects the model's ability to generalize to other in-domain datasets as well as across topical domains. Our experiments show that fine-tuning significantly improves the performance of the smaller models while the results for the larger models are mixed. Fine-tuning also improves the generalization to in-domain datasets while hurting cross-domain transfer. We show that adding structured explanations to the training set has a positive impact on the performance of three out of four LLMs, while the proposed example selection and generation methods only improve the performance of Llama 3.1 8B while decreasing the performance of GPT-4o Mini.
Read more9/14/2024
💬
0
Fine-tuning large language models for domain adaptation: Exploration of training strategies, scaling, model merging and synergistic capabilities
Wei Lu, Rachel K. Luu, Markus J. Buehler
The advancement of Large Language Models (LLMs) for domain applications in fields such as materials science and engineering depends on the development of fine-tuning strategies that adapt models for specialized, technical capabilities. In this work, we explore the effects of Continued Pretraining (CPT), Supervised Fine-Tuning (SFT), and various preference-based optimization approaches, including Direct Preference Optimization (DPO) and Odds Ratio Preference Optimization (ORPO), on fine-tuned LLM performance. Our analysis shows how these strategies influence model outcomes and reveals that the merging of multiple fine-tuned models can lead to the emergence of capabilities that surpass the individual contributions of the parent models. We find that model merging leads to new functionalities that neither parent model could achieve alone, leading to improved performance in domain-specific assessments. Experiments with different model architectures are presented, including Llama 3.1 8B and Mistral 7B models, where similar behaviors are observed. Exploring whether the results hold also for much smaller models, we use a tiny LLM with 1.7 billion parameters and show that very small LLMs do not necessarily feature emergent capabilities under model merging, suggesting that model scaling may be a key component. In open-ended yet consistent chat conversations between a human and AI models, our assessment reveals detailed insights into how different model variants perform and show that the smallest model achieves a high intelligence score across key criteria including reasoning depth, creativity, clarity, and quantitative precision. Other experiments include the development of image generation prompts based on disparate biological material design concepts, to create new microstructures, architectural concepts, and urban design based on biological materials-inspired construction principles.
Read more9/6/2024