Fine-tuning Large Language Models for Entity Matching

0
Sign in to get full access
Overview
- This paper explores the use of fine-tuning large language models (LLMs) for the task of entity matching.
- Entity matching is the process of identifying whether two or more data records refer to the same real-world entity.
- The researchers investigate the effectiveness of fine-tuning LLMs, such as BERT and GPT-3, on entity matching datasets and compare their performance to traditional machine learning approaches.
Plain English Explanation
The paper looks at using advanced language models, called large language models (LLMs), to help identify when different pieces of data are referring to the same real-world thing, like a person or a product. This process of figuring out if data is about the same thing is called "entity matching."
The researchers took these powerful language models, like BERT and GPT-3, and "fine-tuned" them - which means they trained them on specific entity matching datasets to see if the models could learn to do this task well. They compared the performance of the fine-tuned LLMs to more traditional machine learning approaches for entity matching.
The key idea is that these large language models, which are trained on vast amounts of text data, might be able to pick up on subtle linguistic patterns and relationships that could help with the tricky task of entity matching. By fine-tuning them on relevant datasets, the researchers wanted to see if the LLMs could become experts at this particular problem.
Technical Explanation
The paper explores the use of fine-tuning large language models (LLMs) for the task of entity matching. Entity matching is the process of identifying whether two or more data records refer to the same real-world entity.
The researchers experiment with fine-tuning popular LLMs such as BERT and GPT-3 on entity matching datasets and compare their performance to traditional machine learning approaches. The intuition is that the rich semantic and contextual understanding captured by LLMs could be beneficial for the entity matching task, which often requires understanding subtle linguistic patterns and relationships.
The experimental setup involves using well-established entity matching datasets and fine-tuning the LLMs on them. The researchers also explore different fine-tuning strategies, such as varying the amount of training data and the choice of the LLM backbone. The performance of the fine-tuned LLMs is then evaluated and compared to traditional entity matching methods.
Critical Analysis
The paper provides a thorough investigation into the use of fine-tuned LLMs for entity matching and highlights both the potential benefits and limitations of this approach. While the results demonstrate that LLMs can outperform traditional methods in certain scenarios, the authors also acknowledge the potential challenges, such as the computational cost and the need for large amounts of labeled training data.
Additionally, the paper does not delve into the interpretability or explainability of the fine-tuned LLMs, which could be an important consideration for real-world applications of entity matching. Further research could explore ways to make the LLM-based entity matching systems more transparent and understandable.
Conclusion
This paper presents a compelling exploration of using fine-tuned large language models for the task of entity matching. The results suggest that LLMs can learn to effectively identify when data records refer to the same real-world entity, potentially outperforming traditional machine learning approaches.
The findings have important implications for the field of data integration and knowledge management, where accurate entity matching is a crucial step. By leveraging the powerful language understanding capabilities of LLMs, the entity matching process could become more robust and scalable, with potential benefits for a wide range of applications.
However, the paper also highlights the need for further research to address the limitations and challenges of this approach, such as computational cost and interpretability. Overall, this work offers a valuable contribution to the ongoing efforts to harness the power of large language models for complex data processing tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Fine-tuning Large Language Models for Entity Matching
Aaron Steiner, Ralph Peeters, Christian Bizer
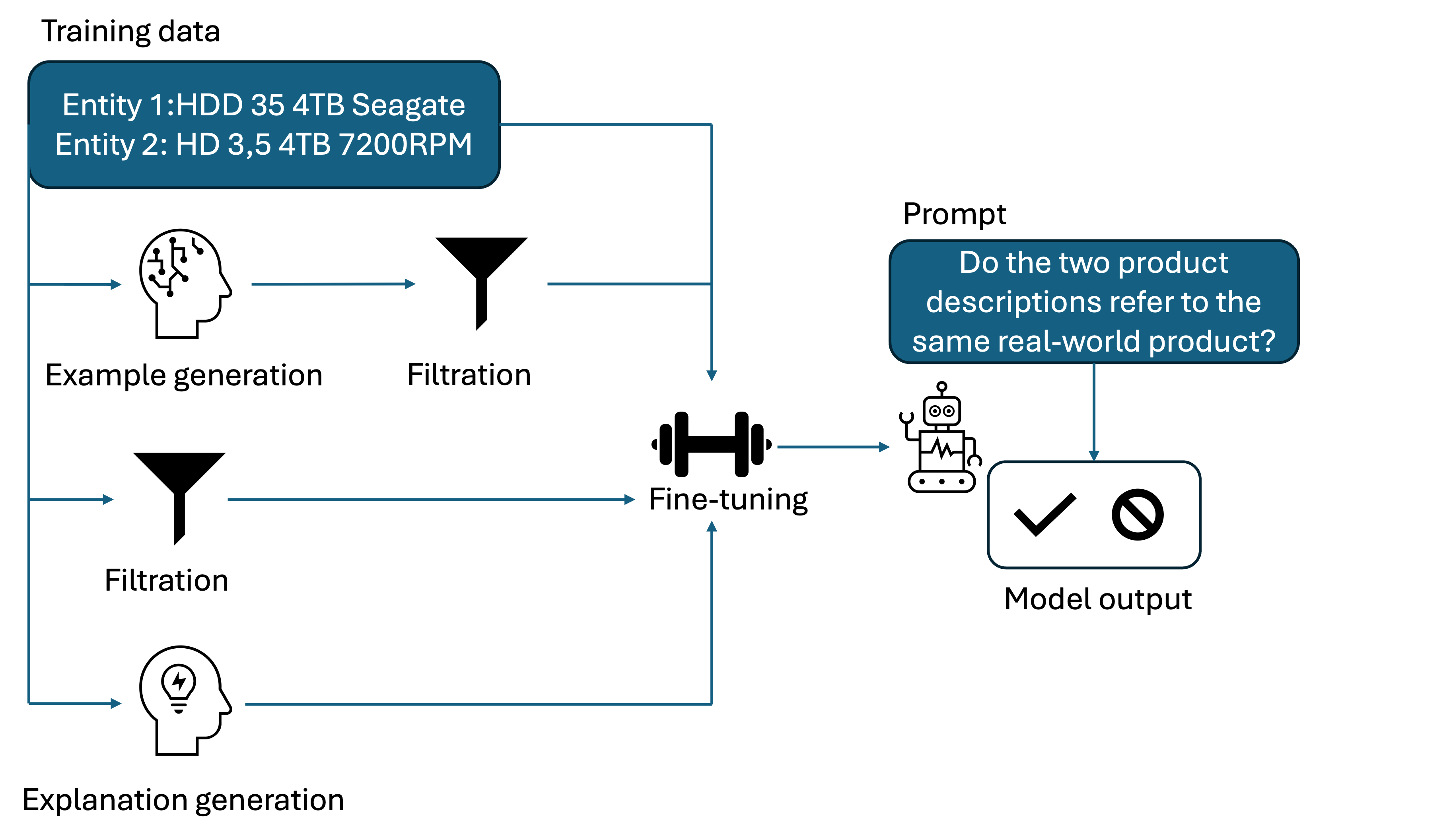
Generative large language models (LLMs) are a promising alternative to pre-trained language models for entity matching due to their high zero-shot performance and their ability to generalize to unseen entities. Existing research on using LLMs for entity matching has focused on prompt engineering and in-context learning. This paper explores the potential of fine-tuning LLMs for entity matching. We analyze fine-tuning along two dimensions: 1) The representation of training examples, where we experiment with adding different types of LLM-generated explanations to the training set, and 2) the selection and generation of training examples using LLMs. In addition to the matching performance on the source dataset, we investigate how fine-tuning affects the model's ability to generalize to other in-domain datasets as well as across topical domains. Our experiments show that fine-tuning significantly improves the performance of the smaller models while the results for the larger models are mixed. Fine-tuning also improves the generalization to in-domain datasets while hurting cross-domain transfer. We show that adding structured explanations to the training set has a positive impact on the performance of three out of four LLMs, while the proposed example selection and generation methods only improve the performance of Llama 3.1 8B while decreasing the performance of GPT-4o Mini.
Read more9/14/2024
💬
0
Entity Matching using Large Language Models
Ralph Peeters, Christian Bizer
Entity Matching is the task of deciding whether two entity descriptions refer to the same real-world entity and is a central step in most data integration pipelines. Many state-of-the-art entity matching methods rely on pre-trained language models (PLMs) such as BERT or RoBERTa. Two major drawbacks of these models for entity matching are that (i) the models require significant amounts of task-specific training data and (ii) the fine-tuned models are not robust concerning out-of-distribution entities. This paper investigates using generative large language models (LLMs) as a less task-specific training data-dependent and more robust alternative to PLM-based matchers. Our study covers hosted and open-source LLMs, which can be run locally. We evaluate these models in a zero-shot scenario and a scenario where task-specific training data is available. We compare different prompt designs and the prompt sensitivity of the models and show that there is no single best prompt but needs to be tuned for each model/dataset combination. We further investigate (i) the selection of in-context demonstrations, (ii) the generation of matching rules, as well as (iii) fine-tuning a hosted LLM using the same pool of training data. Our experiments show that the best LLMs require no or only a few training examples to perform similarly to PLMs that were fine-tuned using thousands of examples. LLM-based matchers further exhibit higher robustness to unseen entities. We show that GPT4 can generate structured explanations for matching decisions. The model can automatically identify potential causes of matching errors by analyzing explanations of wrong decisions. We demonstrate that the model can generate meaningful textual descriptions of the identified error classes, which can help data engineers improve entity matching pipelines.
Read more6/6/2024
0
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Scott Barnett, Zac Brannelly, Stefanus Kurniawan, Sheng Wong
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
Read more7/2/2024

0
Learning from Natural Language Explanations for Generalizable Entity Matching
Somin Wadhwa, Adit Krishnan, Runhui Wang, Byron C. Wallace, Chris Kong
Entity matching is the task of linking records from different sources that refer to the same real-world entity. Past work has primarily treated entity linking as a standard supervised learning problem. However, supervised entity matching models often do not generalize well to new data, and collecting exhaustive labeled training data is often cost prohibitive. Further, recent efforts have adopted LLMs for this task in few/zero-shot settings, exploiting their general knowledge. But LLMs are prohibitively expensive for performing inference at scale for real-world entity matching tasks. As an efficient alternative, we re-cast entity matching as a conditional generation task as opposed to binary classification. This enables us to distill LLM reasoning into smaller entity matching models via natural language explanations. This approach achieves strong performance, especially on out-of-domain generalization tests (10.85% F-1) where standalone generative methods struggle. We perform ablations that highlight the importance of explanations, both for performance and model robustness.
Read more6/14/2024