ERQ: Error Reduction for Post-Training Quantization of Vision Transformers

0

Sign in to get full access
Overview
- This paper, "ERQ: Error Reduction for Post-Training Quantization of Vision Transformers," explores a novel technique to improve the accuracy of vision transformers after they have been compressed using post-training quantization.
- The key innovation is a method to reduce the quantization error that occurs when converting high-precision network weights and activations to lower-bit representations, which can significantly degrade model performance.
- The authors propose several approaches, including MGRQ, Q-HyViT, and ADFQ-ViT, to effectively reduce quantization error and maintain high accuracy for vision transformers after post-training quantization.
Plain English Explanation
The paper focuses on a problem called "post-training quantization" - a technique used to make machine learning models smaller and faster by converting the numbers used in the model from high-precision (like 32-bit floating-point numbers) to lower-precision (like 8-bit integers). This reduces the model size and allows it to run more efficiently on devices like smartphones.
However, this conversion process can introduce errors that degrade the model's performance. The authors of this paper propose several new methods to reduce these errors, specifically for a type of machine learning model called a "vision transformer."
Vision transformers are a powerful type of model that can analyze images and perform tasks like image classification. The authors show that their new quantization techniques can significantly improve the accuracy of vision transformers after they've been compressed using post-training quantization, without sacrificing too much performance.
This is important because it allows vision transformers to be deployed on a wider range of devices, from powerful servers to more resource-constrained edge devices, while still maintaining high accuracy. The techniques described in this paper could help make advanced AI-powered features more accessible on a variety of platforms.
Technical Explanation
The paper introduces a new technique called "Error Reduction for Post-Training Quantization of Vision Transformers" (ERQ), which aims to mitigate the accuracy degradation caused by post-training quantization of vision transformer models.
The key innovations in ERQ include:
-
Mixed Grouping for Quantization (MGRQ): A method that groups network weights and activations in a mixed manner, which can better capture the distribution of values and reduce quantization error compared to uniform grouping.
-
Quantization-aware Hybrid Vision Transformer (Q-HyViT): A hybrid vision transformer architecture that combines convolutional and transformer layers, allowing for more efficient quantization of different components of the model.
-
Activation Distribution Friendly Quantization for ViT (ADFQ-ViT): A quantization scheme that adapts to the activation distribution of the vision transformer, further reducing quantization error.
The authors evaluate these techniques on several vision transformer models and benchmark datasets, demonstrating significant improvements in top-1 accuracy after post-training quantization compared to prior state-of-the-art methods.
Critical Analysis
The paper presents a thorough and well-designed set of experiments to validate the effectiveness of the proposed ERQ techniques. The authors carefully consider various aspects of the quantization problem and explore multiple approaches to address them.
One potential limitation is that the experiments are conducted on a relatively small set of vision transformer models and datasets. While the authors show consistent improvements across the tested scenarios, it would be valuable to see how the techniques perform on a wider range of vision transformer architectures and real-world applications.
Additionally, the paper does not provide a detailed analysis of the computational and memory overhead introduced by the ERQ techniques. Understanding the trade-offs between accuracy improvements and model complexity would be helpful for practitioners looking to deploy these methods in resource-constrained environments.
Overall, the paper makes a significant contribution to the field of post-training quantization for vision transformers, and the proposed methods show promising results that warrant further investigation and exploration.
Conclusion
This paper introduces a set of novel techniques, collectively called ERQ, to improve the accuracy of vision transformers after they have been compressed using post-training quantization. The key innovations, such as MGRQ, Q-HyViT, and ADFQ-ViT, demonstrate effective ways to reduce quantization error and maintain high model performance.
The demonstrated improvements in top-1 accuracy across various vision transformer models and datasets highlight the potential of the ERQ methods to enable the deployment of these powerful AI models on a wider range of devices, from powerful servers to resource-constrained edge platforms. This could significantly expand the accessibility of advanced computer vision capabilities, benefiting a broad range of applications and industries.
While the paper presents a solid technical foundation, further research is needed to explore the scalability and practical implications of the ERQ techniques. Nonetheless, this work represents an important step forward in the field of post-training quantization and contributes to the ongoing efforts to make AI models more efficient and widely deployable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ERQ: Error Reduction for Post-Training Quantization of Vision Transformers
Yunshan Zhong, Jiawei Hu, You Huang, Yuxin Zhang, Rongrong Ji
Post-training quantization (PTQ) for vision transformers (ViTs) has garnered significant attention due to its efficiency in compressing models. However, existing methods typically overlook the intricate interdependence between quantized weight and activation, leading to considerable quantization error. In this paper, we propose ERQ, a two-step PTQ approach meticulously crafted to sequentially reduce the quantization error arising from activation and weight quantization. ERQ first introduces Activation quantization error reduction (Aqer) that strategically formulates the minimization of activation quantization error as a Ridge Regression problem, tackling it by updating weights with full-precision. Subsequently, ERQ introduces Weight quantization error reduction (Wqer) that adopts an iterative approach to mitigate the quantization error induced by weight quantization. In each iteration, an empirically derived, efficient proxy is employed to refine the rounding directions of quantized weights, coupled with a Ridge Regression solver to curtail weight quantization error. Experimental results attest to the effectiveness of our approach. Notably, ERQ surpasses the state-of-the-art GPTQ by 22.36% in accuracy for W3A4 ViT-S.
Read more7/10/2024
👀
0
PTQ4ViT: Post-training quantization for vision transformers with twin uniform quantization
Zhihang Yuan, Chenhao Xue, Yiqi Chen, Qiang Wu, Guangyu Sun
Quantization is one of the most effective methods to compress neural networks, which has achieved great success on convolutional neural networks (CNNs). Recently, vision transformers have demonstrated great potential in computer vision. However, previous post-training quantization methods performed not well on vision transformer, resulting in more than 1% accuracy drop even in 8-bit quantization. Therefore, we analyze the problems of quantization on vision transformers. We observe the distributions of activation values after softmax and GELU functions are quite different from the Gaussian distribution. We also observe that common quantization metrics, such as MSE and cosine distance, are inaccurate to determine the optimal scaling factor. In this paper, we propose the twin uniform quantization method to reduce the quantization error on these activation values. And we propose to use a Hessian guided metric to evaluate different scaling factors, which improves the accuracy of calibration at a small cost. To enable the fast quantization of vision transformers, we develop an efficient framework, PTQ4ViT. Experiments show the quantized vision transformers achieve near-lossless prediction accuracy (less than 0.5% drop at 8-bit quantization) on the ImageNet classification task.
Read more6/26/2024
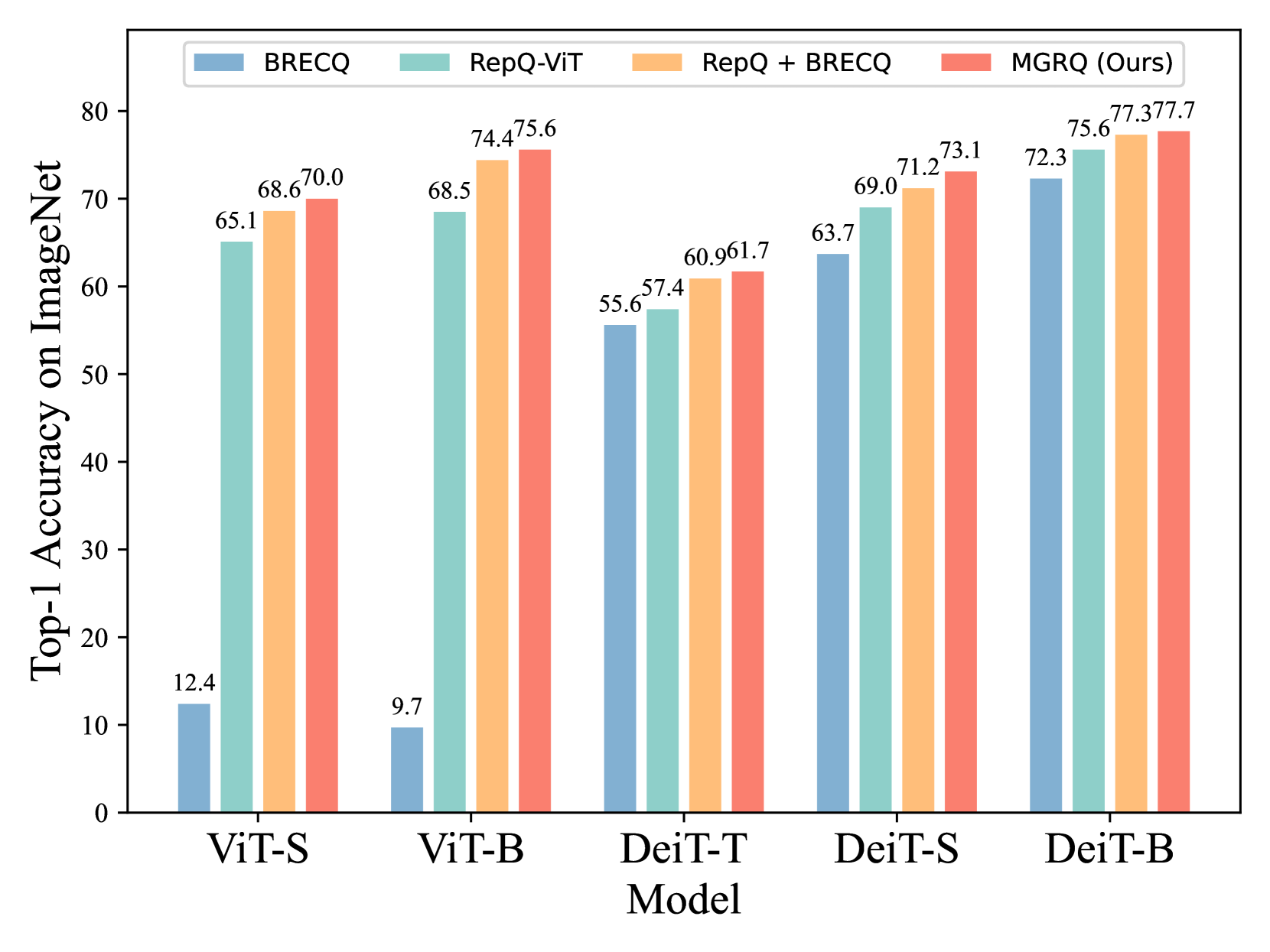
0
MGRQ: Post-Training Quantization For Vision Transformer With Mixed Granularity Reconstruction
Lianwei Yang, Zhikai Li, Junrui Xiao, Haisong Gong, Qingyi Gu
Post-training quantization (PTQ) efficiently compresses vision models, but unfortunately, it accompanies a certain degree of accuracy degradation. Reconstruction methods aim to enhance model performance by narrowing the gap between the quantized model and the full-precision model, often yielding promising results. However, efforts to significantly improve the performance of PTQ through reconstruction in the Vision Transformer (ViT) have shown limited efficacy. In this paper, we conduct a thorough analysis of the reasons for this limited effectiveness and propose MGRQ (Mixed Granularity Reconstruction Quantization) as a solution to address this issue. Unlike previous reconstruction schemes, MGRQ introduces a mixed granularity reconstruction approach. Specifically, MGRQ enhances the performance of PTQ by introducing Extra-Block Global Supervision and Intra-Block Local Supervision, building upon Optimized Block-wise Reconstruction. Extra-Block Global Supervision considers the relationship between block outputs and the model's output, aiding block-wise reconstruction through global supervision. Meanwhile, Intra-Block Local Supervision reduces generalization errors by aligning the distribution of outputs at each layer within a block. Subsequently, MGRQ is further optimized for reconstruction through Mixed Granularity Loss Fusion. Extensive experiments conducted on various ViT models illustrate the effectiveness of MGRQ. Notably, MGRQ demonstrates robust performance in low-bit quantization, thereby enhancing the practicality of the quantized model.
Read more6/14/2024
👀
0
Q-HyViT: Post-Training Quantization of Hybrid Vision Transformers with Bridge Block Reconstruction for IoT Systems
Jemin Lee, Yongin Kwon, Sihyeong Park, Misun Yu, Jeman Park, Hwanjun Song
Recently, vision transformers (ViTs) have superseded convolutional neural networks in numerous applications, including classification, detection, and segmentation. However, the high computational requirements of ViTs hinder their widespread implementation. To address this issue, researchers have proposed efficient hybrid transformer architectures that combine convolutional and transformer layers with optimized attention computation of linear complexity. Additionally, post-training quantization has been proposed as a means of mitigating computational demands. For mobile devices, achieving optimal acceleration for ViTs necessitates the strategic integration of quantization techniques and efficient hybrid transformer structures. However, no prior investigation has applied quantization to efficient hybrid transformers. In this paper, we discover that applying existing post-training quantization (PTQ) methods for ViTs to efficient hybrid transformers leads to a drastic accuracy drop, attributed to the four following challenges: (i) highly dynamic ranges, (ii) zero-point overflow, (iii) diverse normalization, and (iv) limited model parameters ($<$5M). To overcome these challenges, we propose a new post-training quantization method, which is the first to quantize efficient hybrid ViTs (MobileViTv1, MobileViTv2, Mobile-Former, EfficientFormerV1, EfficientFormerV2). We achieve a significant improvement of 17.73% for 8-bit and 29.75% for 6-bit on average, respectively, compared with existing PTQ methods (EasyQuant, FQ-ViT, PTQ4ViT, and RepQ-ViT)}. We plan to release our code at https://gitlab.com/ones-ai/q-hyvit.
Read more5/20/2024