Error Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models

0
💬
Sign in to get full access
Overview
- Generative large language models (LLMs) like ChatGPT have shown impressive capabilities across various natural language processing (NLP) tasks, including machine translation (MT) and text summarization.
- Recent research has found that while LLMs perform well at the system level for MT quality assessment, they perform poorly at the segment level.
- To address this, the researchers investigated different prompting techniques and proposed a new method called "Error Analysis Prompting" (EAPrompt) that combines Chain-of-Thoughts and Error Analysis.
- EAPrompt aims to produce explainable and reliable MT evaluations at both the system and segment level, emulating the Multidimensional Quality Metrics (MQM) framework for human evaluation.
Plain English Explanation
Large language models (LLMs) like ChatGPT have become incredibly capable at various language tasks, including translating between languages. Researchers have found that these models can accurately evaluate the overall quality of machine translations, but they struggle to provide detailed feedback on specific problems within the translations.
To address this, the researchers in this study tried out different ways of asking the LLMs to assess translations. They proposed a new technique called "Error Analysis Prompting" (EAPrompt) that combines two existing methods: Chain-of-Thoughts and Error Analysis. This new approach aims to make the LLMs' evaluations more human-like, with clear explanations of the types of errors they find, similar to how human experts would assess translations.
The researchers tested EAPrompt on a variety of LLMs and found that it performed well at both the overall system level and the individual sentence level. EAPrompt was able to reliably identify major errors versus minor ones, and the distribution of errors it found matched up with what human evaluators using the standard Multidimensional Quality Metrics (MQM) framework would find.
This suggests that EAPrompt could be a powerful tool for getting high-quality, explainable feedback on machine translations from large language models, which could be useful for improving translation systems and for educational purposes.
Technical Explanation
The researchers investigated different prompting techniques to improve the performance of LLMs on machine translation (MT) quality assessment. They proposed a new method called "Error Analysis Prompting" (EAPrompt) that combines two existing techniques: Chain-of-Thoughts (Wei et al., 2022) and Error Analysis (Lu et al., 2023).
EAPrompt is designed to emulate the Multidimensional Quality Metrics (MQM) framework used in human evaluation of MT. The technique involves asking the LLM to first provide an overall quality score for the translation, then to analyze the specific errors it identifies and classify them into different categories (e.g., major vs. minor errors).
The researchers tested EAPrompt on various LLM architectures, including GPT-3, PaLM, and FLAN, using data from the WMT22 metrics shared task. They found that EAPrompt outperformed other prompting techniques and achieved state-of-the-art performance at both the system and segment level for MT quality assessment.
Further analysis showed that EAPrompt was able to effectively distinguish major errors from minor ones, and the distribution of errors it identified closely matched that of human evaluations using the MQM framework. These findings suggest that EAPrompt can serve as a reliable, human-like evaluator for machine translations.
Critical Analysis
The researchers provide a thorough evaluation of their EAPrompt technique and demonstrate its effectiveness in improving LLM performance on MT quality assessment. However, there are a few potential limitations and areas for further research:
-
The study focuses on evaluating EAPrompt on a specific dataset from the WMT22 metrics shared task. It would be valuable to test the technique on a broader range of MT datasets and language pairs to further validate its generalizability.
-
The researchers acknowledge that the current implementation of EAPrompt relies on predefined error categories, which may not capture the full nuance and complexity of human evaluation. Exploring more flexible, open-ended error analysis prompting could be an interesting area for future research.
-
While EAPrompt aims to emulate human-like evaluation, it is still based on an LLM and may not fully capture the contextual understanding and reasoning that human experts bring to the task. Further research is needed to understand the limitations and potential biases of LLM-based evaluation techniques.
Overall, the EAPrompt approach represents a promising step forward in leveraging large language models for more reliable and explainable MT evaluation. The researchers have demonstrated the potential of this technique, but continued exploration and refinement will be important to fully realize its benefits.
Conclusion
This research proposes a novel prompting technique called "Error Analysis Prompting" (EAPrompt) that aims to improve the performance of large language models (LLMs) on machine translation (MT) quality assessment. By combining Chain-of-Thoughts and Error Analysis, EAPrompt is able to produce explainable and reliable evaluations at both the system and segment level, emulating the Multidimensional Quality Metrics (MQM) framework used in human evaluation.
The experimental results validate the effectiveness of EAPrompt across different LLM architectures, highlighting its potential as a powerful tool for assessing and improving MT systems. This research contributes to the ongoing efforts to leverage the capabilities of large language models for various NLP applications, while also underscoring the importance of developing techniques that can provide meaningful, human-like feedback and explanations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Error Analysis Prompting Enables Human-Like Translation Evaluation in Large Language Models
Qingyu Lu, Baopu Qiu, Liang Ding, Kanjian Zhang, Tom Kocmi, Dacheng Tao
Generative large language models (LLMs), e.g., ChatGPT, have demonstrated remarkable proficiency across several NLP tasks, such as machine translation, text summarization. Recent research (Kocmi and Federmann, 2023) has shown that utilizing LLMs for assessing the quality of machine translation (MT) achieves state-of-the-art performance at the system level but textit{performs poorly at the segment level}. To further improve the performance of LLMs on MT quality assessment, we investigate several prompting designs, and propose a new prompting method called textbf{texttt{Error Analysis Prompting}} (EAPrompt) by combining Chain-of-Thoughts (Wei et al., 2022) and Error Analysis (Lu et al., 2023). This technique emulates the commonly accepted human evaluation framework - Multidimensional Quality Metrics (MQM, Freitag et al. (2021)) and textit{produces explainable and reliable MT evaluations at both the system and segment level}. Experimental Results from the WMT22 metrics shared task validate the effectiveness of EAPrompt on various LLMs, with different structures. Further analysis confirms that EAPrompt effectively distinguishes major errors from minor ones, while also sharing a similar distribution of the number of errors with MQM. These findings highlight the potential of EAPrompt as a human-like evaluator prompting technique for MT evaluation.
Read more6/6/2024
💬
0
Prompting Large Language Models with Human Error Markings for Self-Correcting Machine Translation
Nathaniel Berger, Stefan Riezler, Miriam Exel, Matthias Huck
While large language models (LLMs) pre-trained on massive amounts of unpaired language data have reached the state-of-the-art in machine translation (MT) of general domain texts, post-editing (PE) is still required to correct errors and to enhance term translation quality in specialized domains. In this paper we present a pilot study of enhancing translation memories (TM) produced by PE (source segments, machine translations, and reference translations, henceforth called PE-TM) for the needs of correct and consistent term translation in technical domains. We investigate a light-weight two-step scenario where, at inference time, a human translator marks errors in the first translation step, and in a second step a few similar examples are extracted from the PE-TM to prompt an LLM. Our experiment shows that the additional effort of augmenting translations with human error markings guides the LLM to focus on a correction of the marked errors, yielding consistent improvements over automatic PE (APE) and MT from scratch.
Read more6/5/2024

0
Question-Analysis Prompting Improves LLM Performance in Reasoning Tasks
Dharunish Yugeswardeenoo, Kevin Zhu, Sean O'Brien
Although LLMs have the potential to transform many fields, they still underperform humans in reasoning tasks. Existing methods induce the model to produce step-by-step calculations, but this research explores the question: Does making the LLM analyze the question improve its performance? We propose a novel prompting strategy called Question Analysis Prompting (QAP), in which the model is prompted to explain the question in $n$ words before solving. The value of $n$ influences the length of response generated by the model. QAP is evaluated on GPT 3.5 Turbo and GPT 4 Turbo on arithmetic datasets GSM8K, AQuA, and SAT and commonsense dataset StrategyQA. QAP is compared with other state-of-the-art prompts including Chain-of-Thought (CoT), Plan and Solve Prompting (PS+) and Take A Deep Breath (TADB). QAP outperforms all state-of-the-art prompts on AQuA and SAT datasets on both GPT3.5 and GPT4. QAP consistently ranks among the top-2 prompts on 75% of the tests. A key factor of QAP performance can be attributed to response length, where detailed responses are beneficial when answering harder questions, but can negatively affect easy questions.
Read more8/27/2024
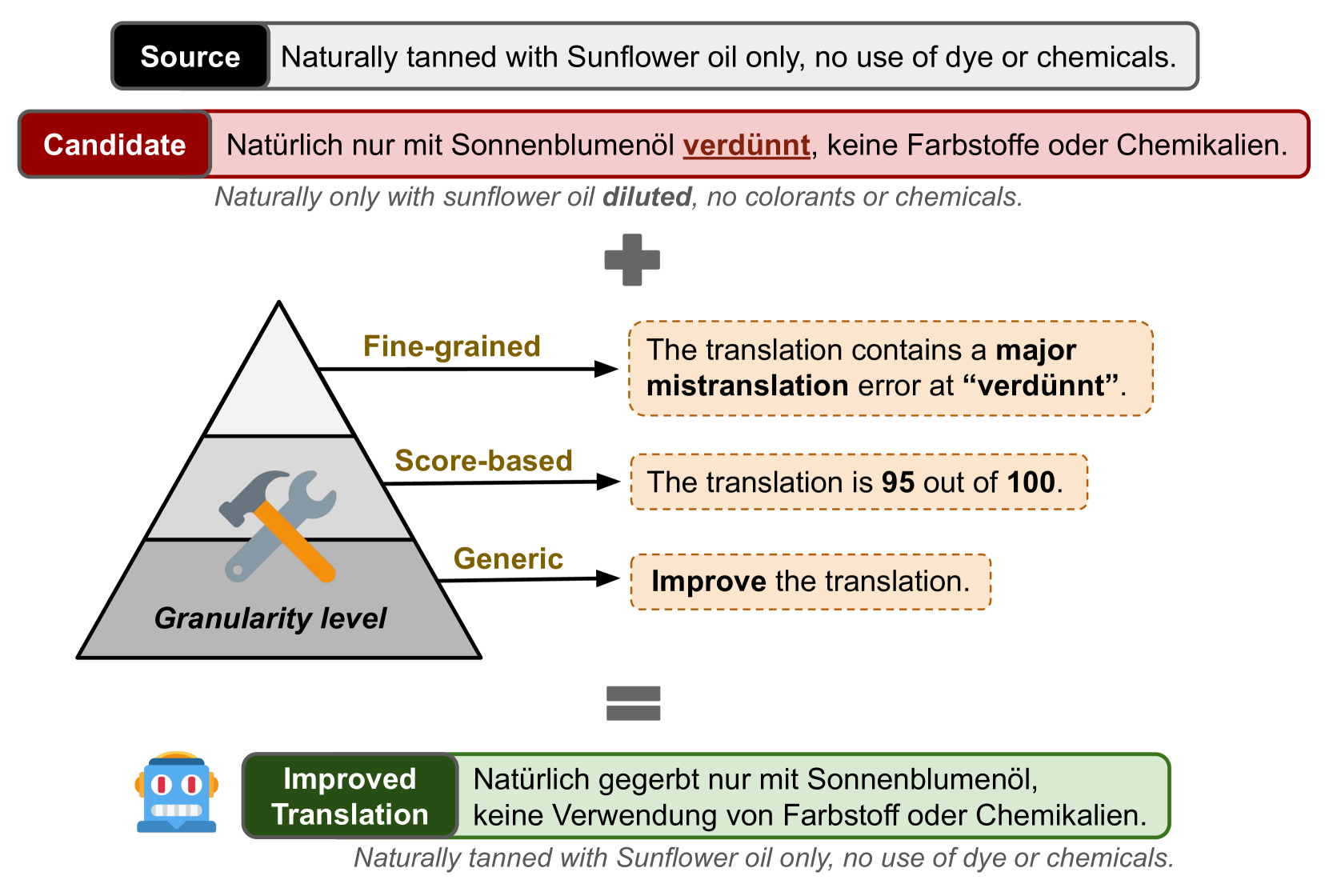
0
Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
Dayeon Ki, Marine Carpuat
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
Read more4/12/2024