Guiding Large Language Models to Post-Edit Machine Translation with Error Annotations
2404.07851
0
0
Abstract
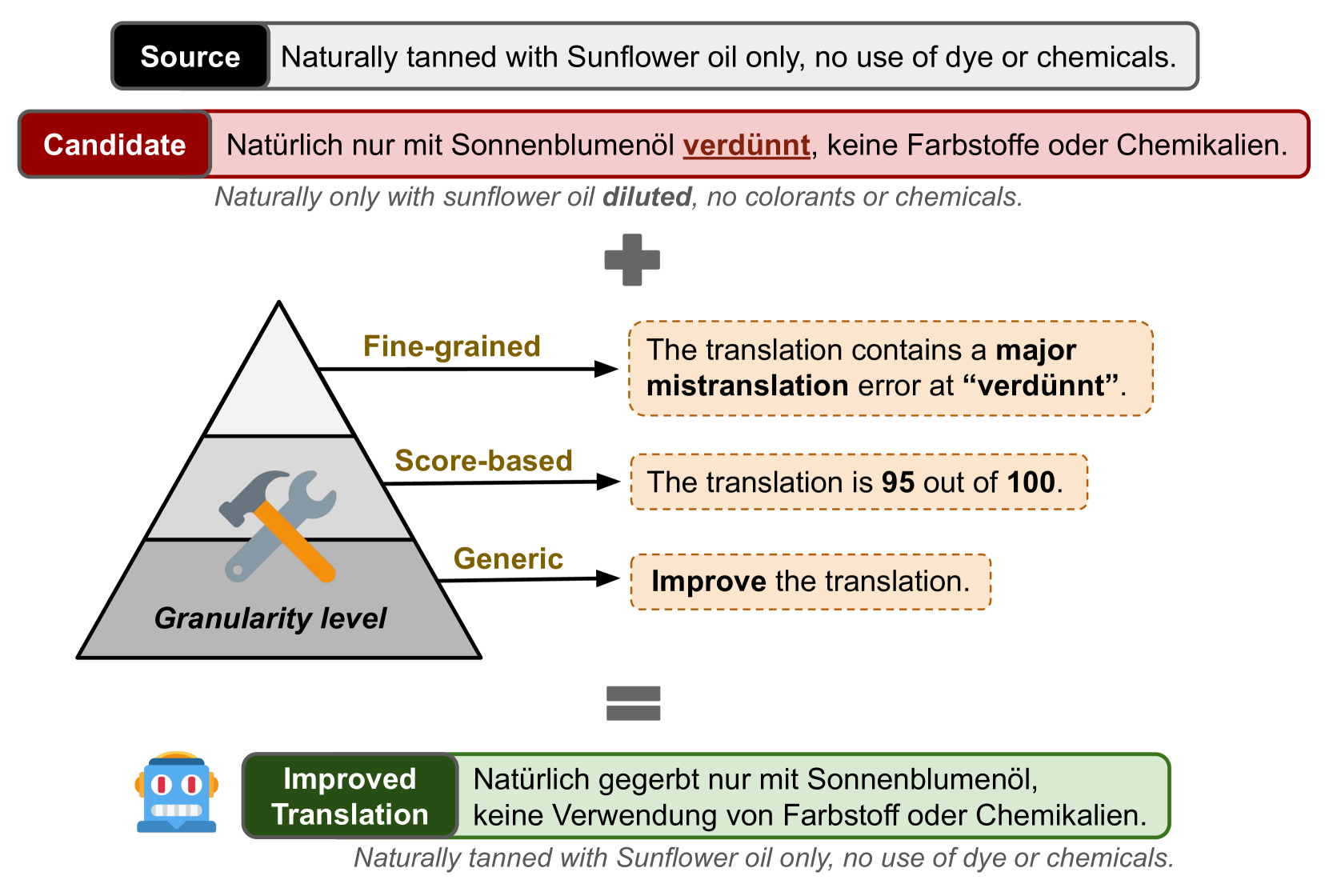
Machine Translation (MT) remains one of the last NLP tasks where large language models (LLMs) have not yet replaced dedicated supervised systems. This work exploits the complementary strengths of LLMs and supervised MT by guiding LLMs to automatically post-edit MT with external feedback on its quality, derived from Multidimensional Quality Metric (MQM) annotations. Working with LLaMA-2 models, we consider prompting strategies varying the nature of feedback provided and then fine-tune the LLM to improve its ability to exploit the provided guidance. Through experiments on Chinese-English, English-German, and English-Russian MQM data, we demonstrate that prompting LLMs to post-edit MT improves TER, BLEU and COMET scores, although the benefits of fine-grained feedback are not clear. Fine-tuning helps integrate fine-grained feedback more effectively and further improves translation quality based on both automatic and human evaluation.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This research paper explores how large language models (LLMs) can be guided to effectively post-edit machine translation (MT) output using error annotations.
- The researchers investigate ways to leverage the capabilities of LLMs to improve the quality of machine-translated text by incorporating feedback on specific translation errors.
- The goal is to develop techniques that can enhance the post-editing process and lead to more accurate and fluent translations.
Plain English Explanation
Machine translation (MT) systems have made significant advancements in recent years, but they still struggle to produce perfect translations. This is where post-editing comes in - human experts review the machine-generated translations and make corrections to improve the output.
The researchers in this study wanted to explore how large language models (LLMs), such as GPT-3, can be used to assist in the post-editing process. LLMs are powerful AI systems that can understand and generate human-like text. The researchers hypothesized that by providing LLMs with information about specific translation errors, they could guide the models to make more accurate and natural corrections.
To test this idea, the researchers conducted experiments where they gave the LLMs access to error annotations - information about the type and location of errors in the machine-translated text. They then measured how well the LLMs were able to post-edit the translations and improve their quality.
The results of the study suggest that incorporating error annotations can indeed help LLMs become more effective at post-editing machine translations. By understanding the specific problems in the translations, the LLMs were able to make more targeted and meaningful corrections, leading to higher-quality final output.
This research highlights the potential for LLMs to play a valuable role in the post-editing process, potentially reducing the workload for human translators and improving the overall efficiency of machine translation workflows. As LLMs continue to advance, finding ways to leverage their capabilities in practical applications like this is an important area of exploration.
Technical Explanation
The researchers propose a novel approach to leveraging large language models (LLMs) for post-editing machine translation (MT) output. They investigate ways to guide the LLMs by providing them with error annotations - information about the type and location of errors in the machine-translated text.
The study uses a dataset of machine-translated sentences with corresponding error annotations. The researchers fine-tune several LLM models, including GPT-3, on this dataset, training the models to learn how to effectively post-edit the translations based on the error information.
During the evaluation phase, the researchers assess the performance of the fine-tuned LLMs on a held-out test set of machine-translated sentences and their error annotations. They measure metrics like BLEU score, chrF, and human evaluation to quantify the quality of the post-edited translations.
The results show that incorporating error annotations can significantly improve the performance of the LLMs in the post-editing task. The models are able to leverage the error information to make more targeted and appropriate corrections, leading to higher-quality final translations.
The researchers also explore the impact of different types of error annotations, such as binary error flags versus more detailed error categorizations. They find that more granular error information tends to yield better post-editing results.
Overall, this work demonstrates the potential of large language models to augment the machine translation post-editing process. By guiding the LLMs with error feedback, the researchers have shown that it is possible to enhance the efficiency and effectiveness of human post-editing efforts.
Critical Analysis
The research presented in this paper makes a valuable contribution to the field of machine translation by exploring novel ways to leverage the capabilities of large language models. The core idea of using error annotations to guide the LLMs in the post-editing process is well-conceived and the experimental results appear promising.
One potential limitation of the study is the reliance on a single dataset for evaluation. While the researchers used a held-out test set, it would be valuable to validate the findings on a more diverse range of machine-translated text and error annotations. Expanding the evaluation to include different language pairs, domains, and translation quality levels could provide a more comprehensive understanding of the approach's generalizability.
Additionally, the paper could have delved deeper into the specific types of errors that the LLMs were most effective at correcting. Understanding the strengths and weaknesses of the models in addressing different error categories could inform future research and practical applications.
Another area for further investigation is the potential impact of the proposed approach on the overall translation workflow. While the results suggest that LLM-based post-editing can enhance efficiency, the researchers could have explored the broader implications for human translators, translation service providers, and end-users of machine-translated content.
Despite these potential areas for expansion, the research presented in this paper represents a valuable step forward in the ongoing efforts to improve machine translation quality and the role of large language models in this process. The insights and techniques developed here could pave the way for more advanced human-AI collaboration in translation and other language-related tasks.
Conclusion
This research paper explores a novel approach to leveraging large language models (LLMs) for the post-editing of machine-translated text. By providing the LLMs with error annotations - information about the type and location of errors in the machine-translated output - the researchers demonstrate that the models can be guided to make more accurate and appropriate corrections, leading to higher-quality final translations.
The findings of this study suggest that incorporating error feedback into the LLM-based post-editing process can significantly enhance the efficiency and effectiveness of the overall translation workflow. As large language models continue to advance, this work highlights the potential for AI systems to play a valuable role in assisting human translators and improving the quality of machine-translated content.
While further research is needed to validate the approach across a wider range of languages and domains, this paper represents an important step forward in the ongoing effort to harness the power of large language models for practical language-related tasks. The insights and techniques developed here could inspire new avenues of exploration in the field of machine translation and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024
💬
On-the-Fly Fusion of Large Language Models and Machine Translation
Hieu Hoang, Huda Khayrallah, Marcin Junczys-Dowmunt
0
0
We propose the on-the-fly ensembling of a machine translation model with an LLM, prompted on the same task and input. We perform experiments on 4 language pairs (both directions) with varying data amounts. We find that a slightly weaker-at-translation LLM can improve translations of a NMT model, and ensembling with an LLM can produce better translations than ensembling two stronger MT models. We combine our method with various techniques from LLM prompting, such as in context learning and translation context.
5/7/2024

Investigating Automatic Scoring and Feedback using Large Language Models
Gloria Ashiya Katuka, Alexander Gain, Yen-Yun Yu
0
0
Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
5/2/2024
💬
Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
Jiahuan Li, Hao Zhou, Shujian Huang, Shanbo Cheng, Jiajun Chen
0
0
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
4/16/2024