Estimating Conditional Average Treatment Effects via Sufficient Representation Learning

0

Sign in to get full access
Overview
- The paper proposes a method called "Estimating Conditional Average Treatment Effects via Sufficient Representation Learning" to estimate the causal effect of a treatment on an outcome, conditional on observed covariates.
- The method learns a low-dimensional representation of the covariates that is sufficient for estimating the conditional average treatment effect.
- This approach aims to address the challenge of high-dimensional covariates, which can lead to overfitting and poor generalization.
Plain English Explanation
The paper is about a new way to estimate the causal effect of a treatment on an outcome, taking into account the characteristics of the people or things being studied. This is an important problem in fields like medicine, social science, and economics, where researchers want to understand how an intervention affects different groups.
The key idea is to find a low-dimensional representation of the characteristics (called "covariates") that still contains all the information needed to estimate the treatment effect. This helps address the challenge of high-dimensional covariates, which can lead to overfitting and poor results when trying to estimate the treatment effect.
The proposed method learns this low-dimensional representation in a way that is "sufficient" for estimating the causal effect. This means the representation contains exactly the information needed, without extra irrelevant details. By using this sufficient representation, the researchers can get better estimates of the treatment effect, especially for complex, high-dimensional datasets.
Technical Explanation
The paper introduces a method called "Estimating Conditional Average Treatment Effects via Sufficient Representation Learning" (CATE-SRL) to address the challenge of estimating conditional average treatment effects (CATE) when dealing with high-dimensional covariates.
The key idea is to learn a low-dimensional representation of the covariates that is sufficient for estimating the CATE. This means the representation contains all the information needed to estimate the CATE, without extraneous details that could lead to overfitting.
The CATE-SRL method consists of two main steps:
- Representation Learning: An encoder network learns a low-dimensional representation of the covariates that preserves the information relevant for CATE estimation.
- CATE Estimation: A separate network uses the learned representation to estimate the CATE, leveraging techniques like doubly robust estimation to improve performance.
The authors provide theoretical analysis showing that the learned representation is indeed sufficient for CATE estimation. They also demonstrate the effectiveness of CATE-SRL through experiments on both synthetic and real-world datasets, showing improved performance compared to alternative methods.
Critical Analysis
The paper makes a valuable contribution by proposing a method to address the challenges of high-dimensional covariates in CATE estimation. The authors provide a thorough theoretical analysis and compelling empirical results to support their approach.
However, the paper also acknowledges several limitations and areas for future work. For example, the method assumes the covariates are independent of the treatment assignment, which may not always hold in practice. The authors suggest exploring ways to relax this assumption in future research.
Additionally, the paper does not address the interpretability of the learned representations, which is an important consideration in many real-world applications. Incorporating techniques to enhance the interpretability of the representations could further improve the practical relevance of the CATE-SRL method.
Overall, the paper presents a promising approach for CATE estimation in high-dimensional settings, but additional research is needed to address the identified limitations and expand the method's applicability to a wider range of scenarios.
Conclusion
The paper introduces a novel method called CATE-SRL that learns a low-dimensional representation of high-dimensional covariates to improve the estimation of conditional average treatment effects. By preserving only the relevant information in the representation, the method can better handle the challenges of overfitting and poor generalization that often arise in high-dimensional settings.
The theoretical analysis and empirical results presented in the paper demonstrate the effectiveness of this approach, making it a valuable contribution to the field of causal inference. While the method has some limitations, the authors provide a solid foundation for future research to build upon and further advance the state of the art in CATE estimation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Estimating Conditional Average Treatment Effects via Sufficient Representation Learning
Pengfei Shi, Wei Zhong, Xinyu Zhang, Ningtao Wang, Xing Fu, Weiqiang Wang, Yin Jin
Estimating the conditional average treatment effects (CATE) is very important in causal inference and has a wide range of applications across many fields. In the estimation process of CATE, the unconfoundedness assumption is typically required to ensure the identifiability of the regression problems. When estimating CATE using high-dimensional data, there have been many variable selection methods and neural network approaches based on representation learning, while these methods do not provide a way to verify whether the subset of variables after dimensionality reduction or the learned representations still satisfy the unconfoundedness assumption during the estimation process, which can lead to ineffective estimates of the treatment effects. Additionally, these methods typically use data from only the treatment or control group when estimating the regression functions for each group. This paper proposes a novel neural network approach named textbf{CrossNet} to learn a sufficient representation for the features, based on which we then estimate the CATE, where cross indicates that in estimating the regression functions, we used data from their own group as well as cross-utilized data from another group. Numerical simulations and empirical results demonstrate that our method outperforms the competitive approaches.
Read more9/2/2024
👀
0
Bounds on Representation-Induced Confounding Bias for Treatment Effect Estimation
Valentyn Melnychuk, Dennis Frauen, Stefan Feuerriegel
State-of-the-art methods for conditional average treatment effect (CATE) estimation make widespread use of representation learning. Here, the idea is to reduce the variance of the low-sample CATE estimation by a (potentially constrained) low-dimensional representation. However, low-dimensional representations can lose information about the observed confounders and thus lead to bias, because of which the validity of representation learning for CATE estimation is typically violated. In this paper, we propose a new, representation-agnostic refutation framework for estimating bounds on the representation-induced confounding bias that comes from dimensionality reduction (or other constraints on the representations) in CATE estimation. First, we establish theoretically under which conditions CATE is non-identifiable given low-dimensional (constrained) representations. Second, as our remedy, we propose a neural refutation framework which performs partial identification of CATE or, equivalently, aims at estimating lower and upper bounds of the representation-induced confounding bias. We demonstrate the effectiveness of our bounds in a series of experiments. In sum, our refutation framework is of direct relevance in practice where the validity of CATE estimation is of importance.
Read more4/15/2024
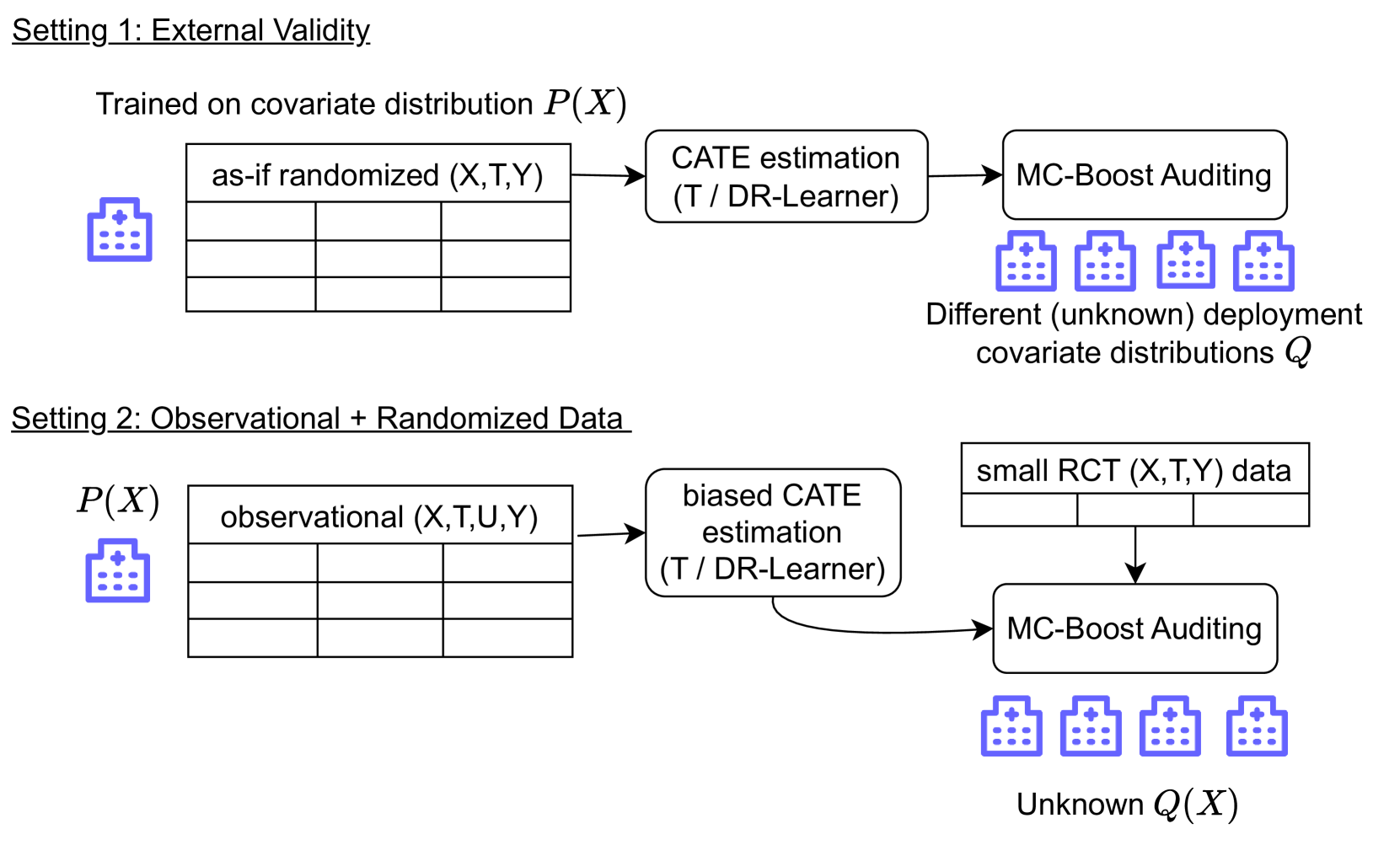
0
Multi-CATE: Multi-Accurate Conditional Average Treatment Effect Estimation Robust to Unknown Covariate Shifts
Christoph Kern, Michael Kim, Angela Zhou
Estimating heterogeneous treatment effects is important to tailor treatments to those individuals who would most likely benefit. However, conditional average treatment effect predictors may often be trained on one population but possibly deployed on different, possibly unknown populations. We use methodology for learning multi-accurate predictors to post-process CATE T-learners (differenced regressions) to become robust to unknown covariate shifts at the time of deployment. The method works in general for pseudo-outcome regression, such as the DR-learner. We show how this approach can combine (large) confounded observational and (smaller) randomized datasets by learning a confounded predictor from the observational dataset, and auditing for multi-accuracy on the randomized controlled trial. We show improvements in bias and mean squared error in simulations with increasingly larger covariate shift, and on a semi-synthetic case study of a parallel large observational study and smaller randomized controlled experiment. Overall, we establish a connection between methods developed for multi-distribution learning and achieve appealing desiderata (e.g. external validity) in causal inference and machine learning.
Read more5/29/2024
📉
0
Estimation of conditional average treatment effects on distributed data: A privacy-preserving approach
Yuji Kawamata, Ryoki Motai, Yukihiko Okada, Akira Imakura, Tetsuya Sakurai
Estimation of conditional average treatment effects (CATEs) is an important topic in sciences. CATEs can be estimated with high accuracy if distributed data across multiple parties can be centralized. However, it is difficult to aggregate such data owing to confidential or privacy concerns. To address this issue, we proposed data collaboration double machine learning, a method that can estimate CATE models from privacy-preserving fusion data constructed from distributed data, and evaluated our method through simulations. Our contributions are summarized in the following three points. First, our method enables estimation and testing of semi-parametric CATE models without iterative communication on distributed data. Our semi-parametric CATE method enable estimation and testing that is more robust to model mis-specification than parametric methods. Second, our method enables collaborative estimation between multiple time points and different parties through the accumulation of a knowledge base. Third, our method performed equally or better than other methods in simulations using synthetic, semi-synthetic and real-world datasets.
Read more9/11/2024