Evaluating and Benchmarking Foundation Models for Earth Observation and Geospatial AI
2406.18295
0
0
Abstract
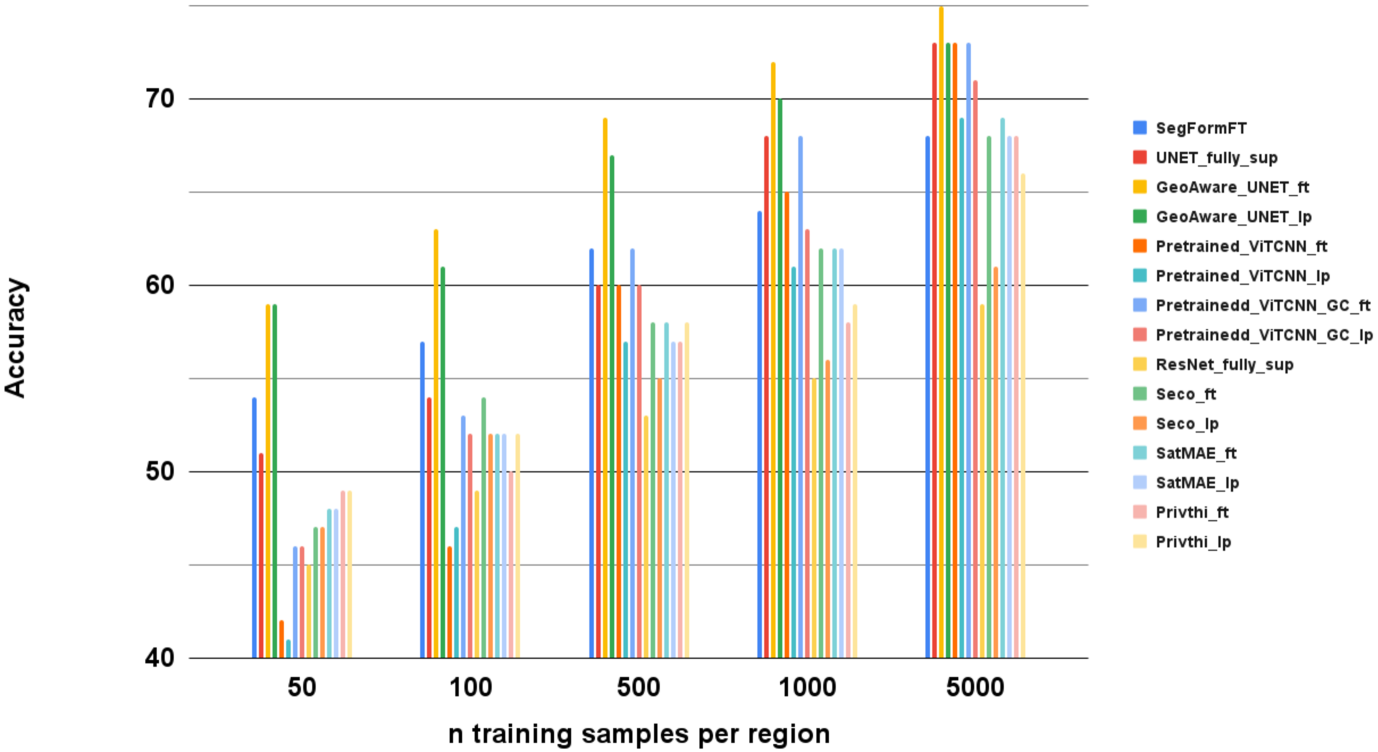
When we are primarily interested in solving several problems jointly with a given prescribed high performance accuracy for each target application, then Foundation Models should for most cases be used rather than problem-specific models. We focus on the specific Computer Vision application of Foundation Models for Earth Observation (EO) and geospatial AI. These models can solve important problems we are tackling, including for example land cover classification, crop type mapping, flood segmentation, building density estimation, and road regression segmentation. In this paper, we show that for a limited number of labelled data, Foundation Models achieve improved performance compared to problem-specific models. In this work, we also present our proposed evaluation benchmark for Foundation Models for EO. Benchmarking the generalization performance of Foundation Models is important as it has become difficult to standardize a fair comparison across the many different models that have been proposed recently. We present the results using our evaluation benchmark for EO Foundation Models and show that Foundation Models are label efficient in the downstream tasks and help us solve problems we are tackling in EO and remote sensing.
Create account to get full access
Overview
- This paper evaluates and benchmarks the performance of foundation models for Earth observation and geospatial AI applications.
- Foundation models are large, pre-trained neural networks that can be fine-tuned for a variety of downstream tasks.
- The authors assess the suitability of different foundation models for geospatial applications, which have unique challenges compared to traditional computer vision or natural language processing tasks.
Plain English Explanation
Foundation models are a powerful AI technique that has seen great success in areas like language and image understanding. These models are trained on massive amounts of data, allowing them to develop a deep, general understanding of the world. Once trained, they can be "fine-tuned" for specific tasks, like analyzing satellite imagery or understanding geographic data.
This paper looks at how well these foundation models perform on geospatial AI tasks, which involve working with spatial data like maps, satellite images, and geographic information. Geospatial AI has unique challenges compared to other domains, so the authors want to understand which foundation models are best suited for these types of applications.
They evaluate the performance of several popular foundation models, like CLIP and Geospatial Foundation Models, on a range of geospatial benchmarks. This helps identify the strengths and weaknesses of different models and provides guidance on which ones work best for various geospatial tasks.
The goal is to help researchers and practitioners in the geospatial AI field choose the right foundation models for their applications, ultimately improving the performance and capabilities of these systems.
Technical Explanation
The paper evaluates the performance of several prominent foundation models on a suite of geospatial AI benchmarks. The authors consider models like CLIP, Geospatial Foundation Models, and Chorus that have been pre-trained on large, diverse datasets and can be fine-tuned for downstream tasks.
The experiments cover a range of geospatial tasks, including land cover classification, building footprint extraction, and road network extraction from satellite imagery. The authors assess the models' performance on these benchmarks, as well as their sample efficiency (how much training data is required) and zero-shot capabilities (ability to perform tasks without fine-tuning).
The results show that foundation models generally outperform task-specific models, but certain models are better suited for geospatial applications than others. For example, Geospatial Foundation Models demonstrate strong performance across many tasks, while CLIP struggles with some specialized geospatial challenges.
The authors also explore the impact of pre-training data and fine-tuning strategies, providing guidance on how to effectively leverage foundation models for geospatial AI. Additionally, they identify areas for further research, such as improving the robustness of these models to distribution shift and developing more comprehensive geospatial benchmarks.
Critical Analysis
The paper provides a thorough and well-designed evaluation of foundation models for geospatial AI, addressing an important area of research. The authors have carefully selected a diverse set of benchmarks and foundation models to assess, making the results broadly applicable.
One potential limitation is the scope of the benchmarks, which may not fully capture the breadth of challenges in real-world geospatial applications. The authors acknowledge this and suggest the development of more comprehensive geospatial benchmarks as an area for future work.
Additionally, the paper does not delve into the interpretability or explainability of the foundation models, which could be a valuable consideration for geospatial AI applications that require some level of human understanding and trust. Exploring these aspects could be another fruitful direction for further research.
Overall, this paper makes a significant contribution to the understanding of foundation models for geospatial AI. The insights provided can help researchers and practitioners make more informed decisions when selecting and deploying these powerful AI systems in Earth observation and geographic information applications.
Conclusion
This paper presents a comprehensive evaluation of foundation models for Earth observation and geospatial AI tasks. The authors assess the performance, sample efficiency, and zero-shot capabilities of several prominent foundation models on a range of geospatial benchmarks, providing valuable insights for researchers and practitioners in this field.
The results show that foundation models can offer significant advantages over task-specific models, but the suitability of different models varies depending on the specific geospatial application. The authors also identify areas for further research, such as improving model robustness and developing more comprehensive geospatial benchmarks.
By understanding the strengths and limitations of foundation models in the geospatial domain, the findings of this paper can help guide the development and deployment of these powerful AI systems for a wide range of Earth observation and geographic information applications, ultimately advancing the state of the art in this important field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Yiqun Xie, Zhihao Wang, Weiye Chen, Zhili Li, Xiaowei Jia, Yanhua Li, Ruichen Wang, Kangyang Chai, Ruohan Li, Sergii Skakun
0
0
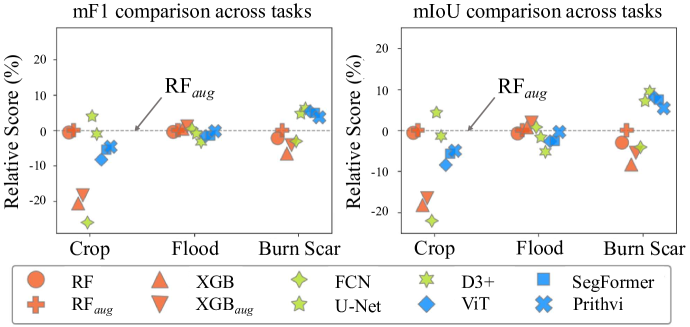
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
4/19/2024

On the Foundations of Earth and Climate Foundation Models
Xiao Xiang Zhu, Zhitong Xiong, Yi Wang, Adam J. Stewart, Konrad Heidler, Yuanyuan Wang, Zhenghang Yuan, Thomas Dujardin, Qingsong Xu, Yilei Shi
0
0
Foundation models have enormous potential in advancing Earth and climate sciences, however, current approaches may not be optimal as they focus on a few basic features of a desirable Earth and climate foundation model. Crafting the ideal Earth foundation model, we define eleven features which would allow such a foundation model to be beneficial for any geoscientific downstream application in an environmental- and human-centric manner.We further shed light on the way forward to achieve the ideal model and to evaluate Earth foundation models. What comes after foundation models? Energy efficient adaptation, adversarial defenses, and interpretability are among the emerging directions.
5/8/2024

CHORUS: Foundation Models for Unified Data Discovery and Exploration
Moe Kayali, Anton Lykov, Ilias Fountalis, Nikolaos Vasiloglou, Dan Olteanu, Dan Suciu
0
0
We apply foundation models to data discovery and exploration tasks. Foundation models include large language models (LLMs) that show promising performance on a range of diverse tasks unrelated to their training. We show that these models are highly applicable to the data discovery and data exploration domain. When carefully used, they have superior capability on three representative tasks: table-class detection, column-type annotation and join-column prediction. On all three tasks, we show that a foundation-model-based approach outperforms the task-specific models and so the state of the art. Further, our approach often surpasses human-expert task performance. We investigate the fundamental characteristics of this approach including generalizability to several foundation models and the impact of non-determinism on the outputs. All in all, this suggests a future direction in which disparate data management tasks can be unified under foundation models.
4/9/2024
Pretraining Billion-scale Geospatial Foundational Models on Frontier
Aristeidis Tsaris, Philipe Ambrozio Dias, Abhishek Potnis, Junqi Yin, Feiyi Wang, Dalton Lunga
0
0
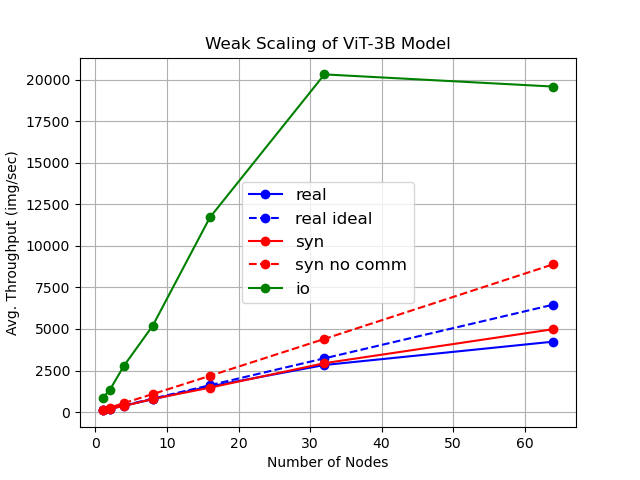
As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.
4/19/2024