Pretraining Billion-scale Geospatial Foundational Models on Frontier
2404.11706
0
0
Abstract
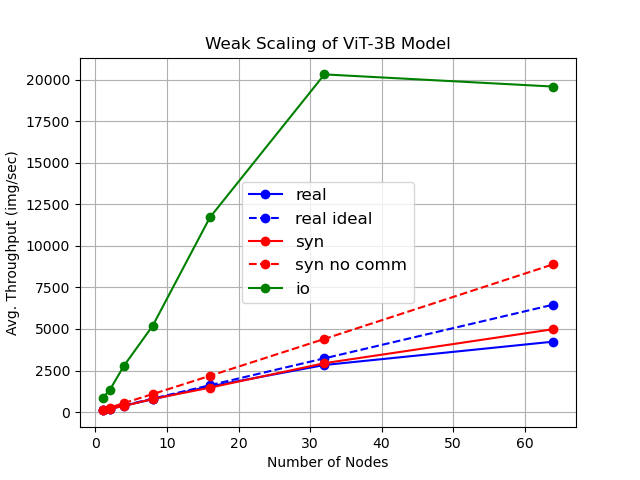
As AI workloads increase in scope, generalization capability becomes challenging for small task-specific models and their demand for large amounts of labeled training samples increases. On the contrary, Foundation Models (FMs) are trained with internet-scale unlabeled data via self-supervised learning and have been shown to adapt to various tasks with minimal fine-tuning. Although large FMs have demonstrated significant impact in natural language processing and computer vision, efforts toward FMs for geospatial applications have been restricted to smaller size models, as pretraining larger models requires very large computing resources equipped with state-of-the-art hardware accelerators. Current satellite constellations collect 100+TBs of data a day, resulting in images that are billions of pixels and multimodal in nature. Such geospatial data poses unique challenges opening up new opportunities to develop FMs. We investigate billion scale FMs and HPC training profiles for geospatial applications by pretraining on publicly available data. We studied from end-to-end the performance and impact in the solution by scaling the model size. Our larger 3B parameter size model achieves up to 30% improvement in top1 scene classification accuracy when comparing a 100M parameter model. Moreover, we detail performance experiments on the Frontier supercomputer, America's first exascale system, where we study different model and data parallel approaches using PyTorch's Fully Sharded Data Parallel library. Specifically, we study variants of the Vision Transformer architecture (ViT), conducting performance analysis for ViT models with size up to 15B parameters. By discussing throughput and performance bottlenecks under different parallelism configurations, we offer insights on how to leverage such leadership-class HPC resources when developing large models for geospatial imagery applications.
Create account to get full access
Overview
- This paper describes the pretraining of billion-scale geospatial foundation models on the Frontier dataset, a large-scale remote sensing dataset.
- The researchers used a vision transformer architecture and distributed training to scale up the model size and training dataset.
- The resulting models are intended to serve as powerful building blocks for a wide range of geospatial applications.
Plain English Explanation
The researchers in this paper built very large-scale machine learning models for working with geospatial data, like satellite imagery and geographic information. These models are called "foundation models" because they can be used as a starting point for many different geospatial applications, rather than having to build everything from scratch.
To create these models, the researchers used a type of machine learning model called a "vision transformer" and trained it on a massive dataset of satellite and aerial imagery called Frontier. This allowed them to train models with over a billion parameters, making them extremely powerful and capable of handling very complex geospatial tasks.
The key innovations in this work were the use of the vision transformer architecture and the distributed training approach, which allowed them to scale up the model size and training data to unprecedented levels for this domain. This means the resulting models should be able to serve as highly capable building blocks for a wide range of geospatial AI applications, from mapping and land-use analysis to disaster response and urban planning.
Technical Explanation
The researchers in this paper explored pretraining billion-scale geospatial foundation models using a vision transformer architecture on the Frontier dataset, a large-scale remote sensing dataset.
They used a distributed training approach to scale up the model size and training dataset. Specifically, they trained vision transformer models with over a billion parameters on the Frontier dataset, which consists of over a billion high-resolution satellite and aerial images spanning a variety of geospatial domains.
The goal was to create powerful geospatial foundation models that can serve as versatile building blocks for a wide range of downstream geospatial AI applications. The researchers hypothesized that pretraining on such a large and diverse geospatial dataset would imbue the models with rich geospatial understanding and capabilities.
The researchers compared their billion-scale geospatial foundation models to smaller baselines and found significant performance improvements across a range of geospatial tasks, showcasing the potential of their approach. They also analyzed the geographic diversity and spatial reasoning capabilities of the models.
Critical Analysis
The paper makes a compelling case for the value of pretraining billion-scale geospatial foundation models on large, diverse datasets like Frontier. The experiments demonstrate significant performance gains over smaller baselines, suggesting that these models can serve as powerful building blocks for a wide range of geospatial applications.
However, the paper does not explore the potential limitations or caveats of this approach in depth. For example, it is unclear how the model's performance and capabilities scale with increasing model size and dataset size. There may also be practical challenges in deploying and fine-tuning these extremely large models for real-world use cases.
Additionally, the paper does not delve into potential biases or fairness issues that could arise from pretraining on a large, potentially skewed dataset like Frontier. The geographic diversity analysis is a good first step, but more work is needed to ensure these models are equitable and unbiased in their geospatial representations and predictions.
Overall, this research represents an important step forward in the field of geospatial AI, but further investigation into the limitations, scalability, and fairness of these billion-scale foundation models is warranted.
Conclusion
This paper presents a novel approach to pretraining billion-scale geospatial foundation models using a vision transformer architecture and distributed training on the Frontier dataset. The resulting models demonstrate significant performance improvements across a range of geospatial tasks, suggesting they can serve as powerful building blocks for a wide variety of geospatial AI applications.
The key innovations in this work are the use of the vision transformer architecture and the distributed training approach, which allowed the researchers to scale up the model size and training dataset to unprecedented levels for this domain. This work represents an important step forward in the field of geospatial AI and lays the groundwork for future research into large-scale, high-performing geospatial foundation models and their applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
A Billion-scale Foundation Model for Remote Sensing Images
Keumgang Cha, Junghoon Seo, Taekyung Lee
0
0
As the potential of foundation models in visual tasks has garnered significant attention, pretraining these models before downstream tasks has become a crucial step. The three key factors in pretraining foundation models are the pretraining method, the size of the pretraining dataset, and the number of model parameters. Recently, research in the remote sensing field has focused primarily on the pretraining method and the size of the dataset, with limited emphasis on the number of model parameters. This paper addresses this gap by examining the effect of increasing the number of model parameters on the performance of foundation models in downstream tasks such as rotated object detection and semantic segmentation. We pretrained foundation models with varying numbers of parameters, including 86M, 605.26M, 1.3B, and 2.4B, to determine whether performance in downstream tasks improved with an increase in parameters. To the best of our knowledge, this is the first billion-scale foundation model in the remote sensing field. Furthermore, we propose an effective method for scaling up and fine-tuning a vision transformer in the remote sensing field. To evaluate general performance in downstream tasks, we employed the DOTA v2.0 and DIOR-R benchmark datasets for rotated object detection, and the Potsdam and LoveDA datasets for semantic segmentation. Experimental results demonstrated that, across all benchmark datasets and downstream tasks, the performance of the foundation models and data efficiency improved as the number of parameters increased. Moreover, our models achieve the state-of-the-art performance on several datasets including DIOR-R, Postdam, and LoveDA.
5/15/2024
The Future of Large Language Model Pre-training is Federated
Lorenzo Sani, Alex Iacob, Zeyu Cao, Bill Marino, Yan Gao, Tomas Paulik, Wanru Zhao, William F. Shen, Preslav Aleksandrov, Xinchi Qiu, Nicholas D. Lane
0
0
Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.
5/20/2024
Evaluating and Benchmarking Foundation Models for Earth Observation and Geospatial AI
Nikolaos Dionelis, Casper Fibaek, Luke Camilleri, Andreas Luyts, Jente Bosmans, Bertrand Le Saux
0
0
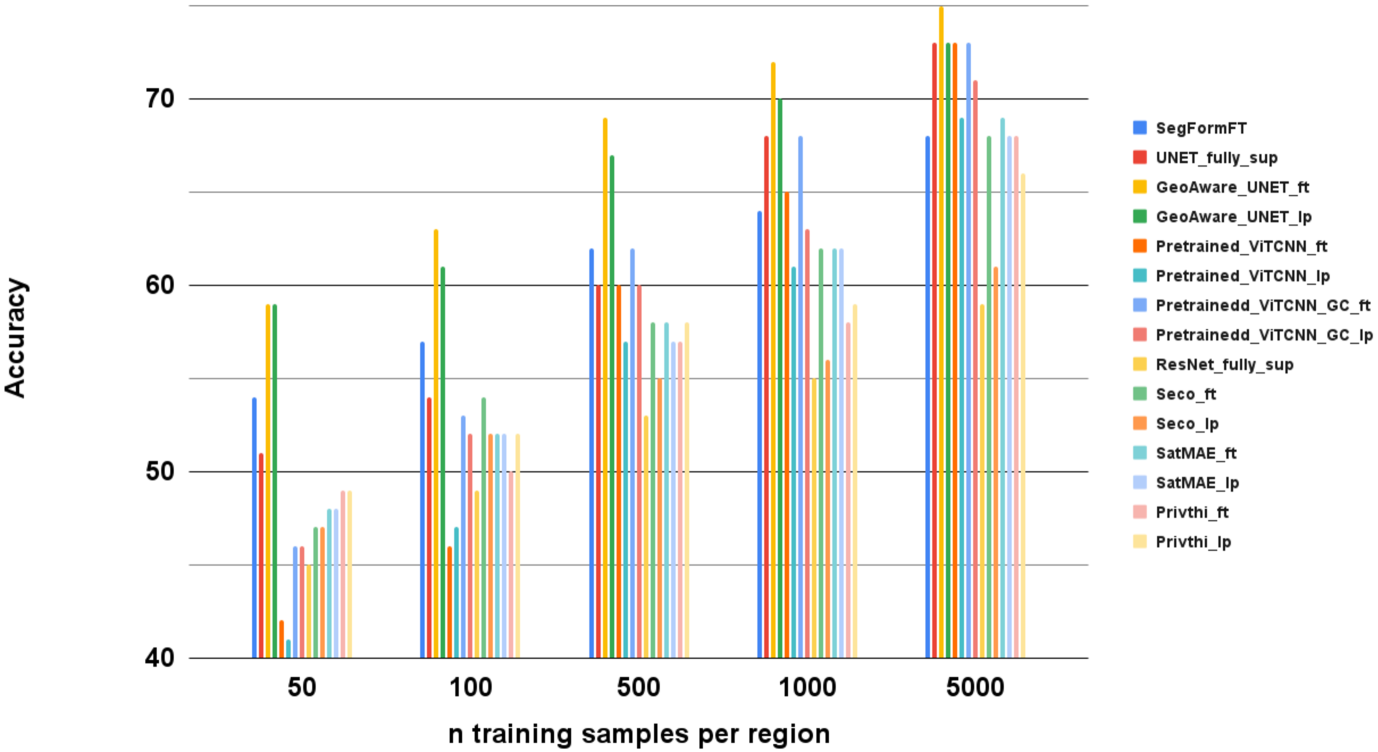
When we are primarily interested in solving several problems jointly with a given prescribed high performance accuracy for each target application, then Foundation Models should for most cases be used rather than problem-specific models. We focus on the specific Computer Vision application of Foundation Models for Earth Observation (EO) and geospatial AI. These models can solve important problems we are tackling, including for example land cover classification, crop type mapping, flood segmentation, building density estimation, and road regression segmentation. In this paper, we show that for a limited number of labelled data, Foundation Models achieve improved performance compared to problem-specific models. In this work, we also present our proposed evaluation benchmark for Foundation Models for EO. Benchmarking the generalization performance of Foundation Models is important as it has become difficult to standardize a fair comparison across the many different models that have been proposed recently. We present the results using our evaluation benchmark for EO Foundation Models and show that Foundation Models are label efficient in the downstream tasks and help us solve problems we are tackling in EO and remote sensing.
6/27/2024
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Yiqun Xie, Zhihao Wang, Weiye Chen, Zhili Li, Xiaowei Jia, Yanhua Li, Ruichen Wang, Kangyang Chai, Ruohan Li, Sergii Skakun
0
0
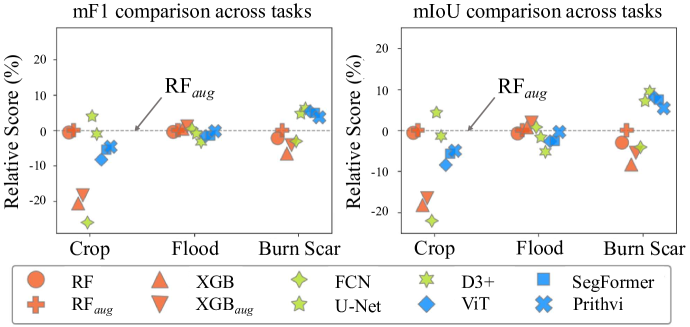
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
4/19/2024