When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
2404.11797
0
0
Abstract
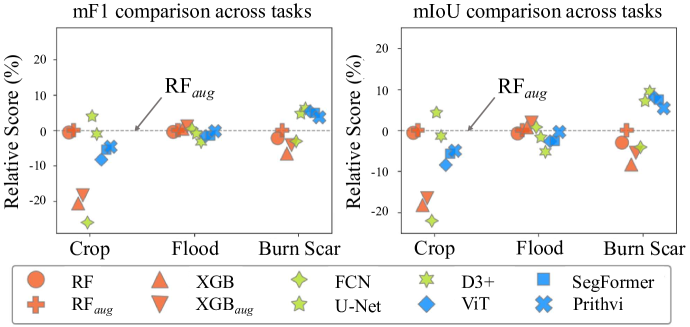
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
Create account to get full access
Overview
- The paper explores the effectiveness of foundation models, which are large, general-purpose AI models, for pixel-level classification tasks using multispectral satellite imagery.
- It examines the suitability of foundation models for these tasks and investigates the factors that influence their performance.
- The research aims to provide insights into when foundation models are most suitable and effective for pixel-level remote sensing applications.
Plain English Explanation
The paper looks at how well foundation models, which are powerful AI models trained on massive amounts of data, can be used for classifying individual pixels in satellite images. Satellite images often contain a lot of detailed information, and being able to accurately classify each pixel can be very useful for applications like urban planning or environmental monitoring.
The researchers wanted to understand the factors that determine whether foundation models are a good fit for these pixel-level classification tasks. They looked at things like the complexity of the images, the amount of training data available, and the nature of the classification problem. By exploring these factors, the paper aims to provide guidance on when foundation models are likely to be effective for this type of remote sensing work, and when other approaches might be better.
Technical Explanation
The paper evaluates the suitability of foundation models for pixel-level classification tasks using multispectral satellite imagery. The researchers conducted experiments on a benchmark dataset, assessing the performance of various foundation models and comparing them to specialized models trained from scratch.
The key factors examined include the complexity of the classification task, the availability of training data, and the characteristics of the satellite imagery (e.g., number of spectral bands). The researchers found that foundation models can be effective for relatively simple pixel-level tasks with abundant training data, but their performance degrades as the task complexity increases or the training data becomes scarce.
The paper also explores transfer learning techniques to adapt foundation models to more challenging pixel-level classification problems, and discusses the tradeoffs between the generalization capabilities of foundation models and the specialized performance of custom-trained models.
Critical Analysis
The paper provides a valuable empirical investigation into the suitability of foundation models for pixel-level remote sensing tasks. The researchers acknowledge that the performance of foundation models can be limited by task complexity and data availability, which aligns with recent findings in the field of few-shot semantic segmentation.
However, the paper does not fully explore the potential of transfer learning and fine-tuning techniques to adapt foundation models to more challenging remote sensing tasks. Additionally, the analysis could be strengthened by considering the impact of different foundation model architectures and pretraining approaches on their suitability for pixel-level classification.
Further research is needed to understand the tradeoffs between the generalization capabilities of foundation models and the specialized performance of custom-trained models in the context of remote sensing applications. Exploring the use of vision-language models for pixel-level tasks could also yield valuable insights.
Conclusion
This paper provides a nuanced understanding of when foundation models are most effective for pixel-level classification tasks using multispectral satellite imagery. The findings suggest that foundation models can be a suitable choice for relatively simple classification problems with abundant training data, but their performance may be limited for more complex tasks or scenarios with limited data.
The research highlights the importance of considering the specific characteristics of the remote sensing application and the available training data when selecting the most appropriate modeling approach. By understanding these factors, practitioners can make more informed decisions about leveraging foundation models or pursuing more specialized solutions for their pixel-level remote sensing needs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Evaluating and Benchmarking Foundation Models for Earth Observation and Geospatial AI
Nikolaos Dionelis, Casper Fibaek, Luke Camilleri, Andreas Luyts, Jente Bosmans, Bertrand Le Saux
0
0
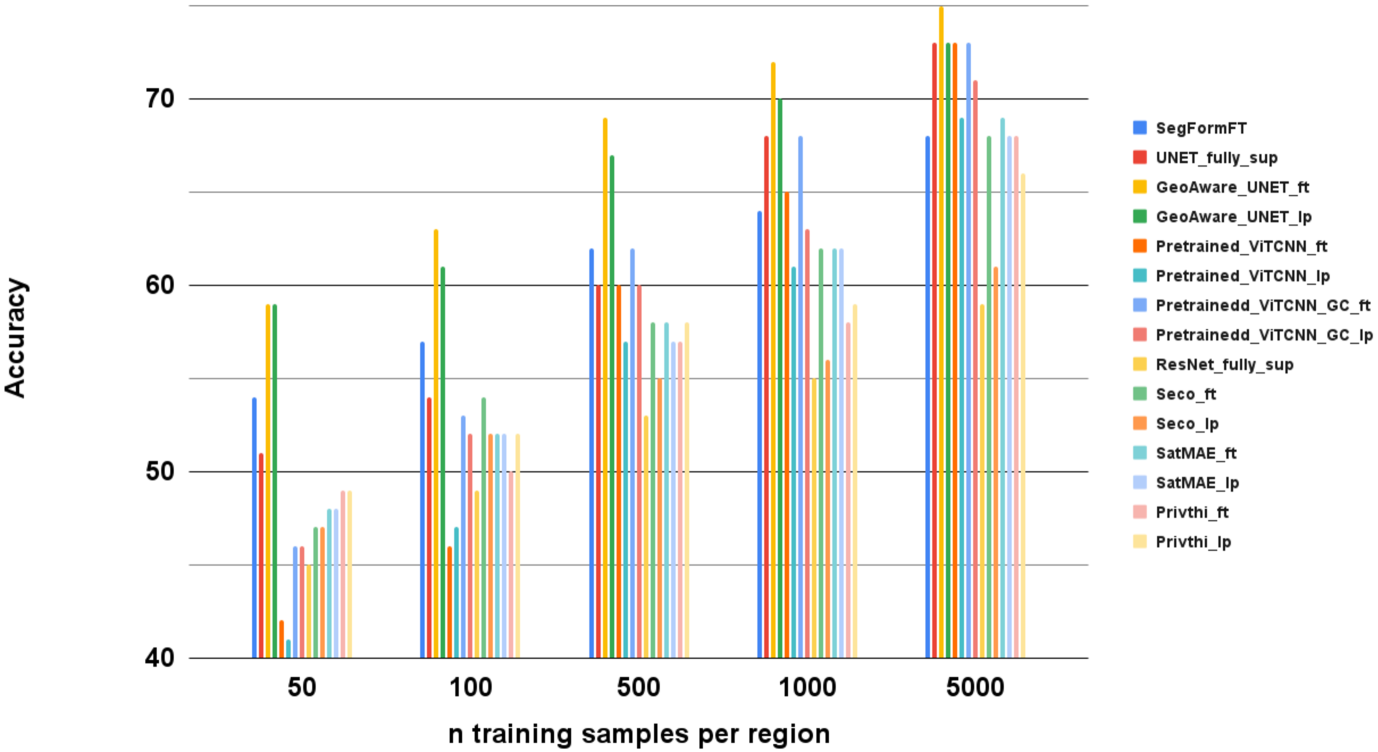
When we are primarily interested in solving several problems jointly with a given prescribed high performance accuracy for each target application, then Foundation Models should for most cases be used rather than problem-specific models. We focus on the specific Computer Vision application of Foundation Models for Earth Observation (EO) and geospatial AI. These models can solve important problems we are tackling, including for example land cover classification, crop type mapping, flood segmentation, building density estimation, and road regression segmentation. In this paper, we show that for a limited number of labelled data, Foundation Models achieve improved performance compared to problem-specific models. In this work, we also present our proposed evaluation benchmark for Foundation Models for EO. Benchmarking the generalization performance of Foundation Models is important as it has become difficult to standardize a fair comparison across the many different models that have been proposed recently. We present the results using our evaluation benchmark for EO Foundation Models and show that Foundation Models are label efficient in the downstream tasks and help us solve problems we are tackling in EO and remote sensing.
6/27/2024
📈
A Billion-scale Foundation Model for Remote Sensing Images
Keumgang Cha, Junghoon Seo, Taekyung Lee
0
0
As the potential of foundation models in visual tasks has garnered significant attention, pretraining these models before downstream tasks has become a crucial step. The three key factors in pretraining foundation models are the pretraining method, the size of the pretraining dataset, and the number of model parameters. Recently, research in the remote sensing field has focused primarily on the pretraining method and the size of the dataset, with limited emphasis on the number of model parameters. This paper addresses this gap by examining the effect of increasing the number of model parameters on the performance of foundation models in downstream tasks such as rotated object detection and semantic segmentation. We pretrained foundation models with varying numbers of parameters, including 86M, 605.26M, 1.3B, and 2.4B, to determine whether performance in downstream tasks improved with an increase in parameters. To the best of our knowledge, this is the first billion-scale foundation model in the remote sensing field. Furthermore, we propose an effective method for scaling up and fine-tuning a vision transformer in the remote sensing field. To evaluate general performance in downstream tasks, we employed the DOTA v2.0 and DIOR-R benchmark datasets for rotated object detection, and the Potsdam and LoveDA datasets for semantic segmentation. Experimental results demonstrated that, across all benchmark datasets and downstream tasks, the performance of the foundation models and data efficiency improved as the number of parameters increased. Moreover, our models achieve the state-of-the-art performance on several datasets including DIOR-R, Postdam, and LoveDA.
5/15/2024
Multi-Spectral Remote Sensing Image Retrieval Using Geospatial Foundation Models
Benedikt Blumenstiel, Viktoria Moor, Romeo Kienzler, Thomas Brunschwiler
0
0
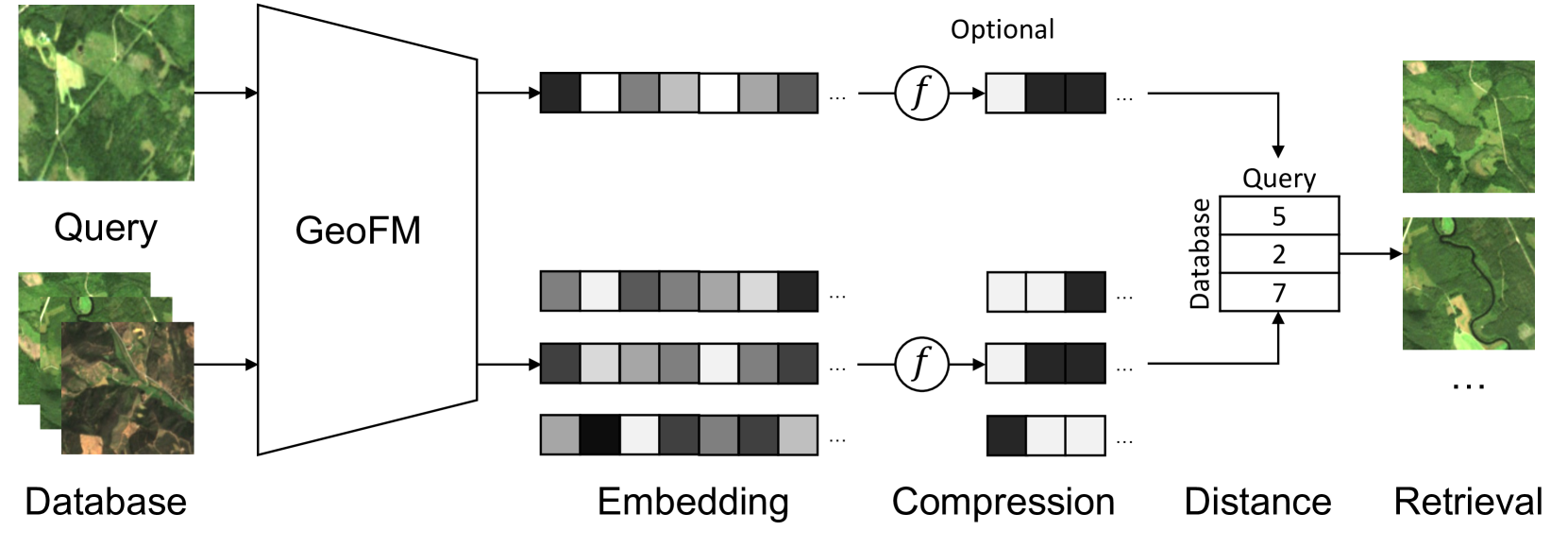
Image retrieval enables an efficient search through vast amounts of satellite imagery and returns similar images to a query. Deep learning models can identify images across various semantic concepts without the need for annotations. This work proposes to use Geospatial Foundation Models, like Prithvi, for remote sensing image retrieval with multiple benefits: i) the models encode multi-spectral satellite data and ii) generalize without further fine-tuning. We introduce two datasets to the retrieval task and observe a strong performance: Prithvi processes six bands and achieves a mean Average Precision of 97.62% on BigEarthNet-43 and 44.51% on ForestNet-12, outperforming other RGB-based models. Further, we evaluate three compression methods with binarized embeddings balancing retrieval speed and accuracy. They match the retrieval speed of much shorter hash codes while maintaining the same accuracy as floating-point embeddings but with a 32-fold compression. The code is available at https://github.com/IBM/remote-sensing-image-retrieval.
5/24/2024

One for All: Toward Unified Foundation Models for Earth Vision
Zhitong Xiong, Yi Wang, Fahong Zhang, Xiao Xiang Zhu
0
0
Foundation models characterized by extensive parameters and trained on large-scale datasets have demonstrated remarkable efficacy across various downstream tasks for remote sensing data. Current remote sensing foundation models typically specialize in a single modality or a specific spatial resolution range, limiting their versatility for downstream datasets. While there have been attempts to develop multi-modal remote sensing foundation models, they typically employ separate vision encoders for each modality or spatial resolution, necessitating a switch in backbones contingent upon the input data. To address this issue, we introduce a simple yet effective method, termed OFA-Net (One-For-All Network): employing a single, shared Transformer backbone for multiple data modalities with different spatial resolutions. Using the masked image modeling mechanism, we pre-train a single Transformer backbone on a curated multi-modal dataset with this simple design. Then the backbone model can be used in different downstream tasks, thus forging a path towards a unified foundation backbone model in Earth vision. The proposed method is evaluated on 12 distinct downstream tasks and demonstrates promising performance.
5/29/2024